Google Code Jam Archive — Farewell Round C problems
Overview
Gardel used to sing in the famous "Volver" tango song that 20 years is nothing. It certainly does not feel that way for Coding Competitions. With these farewell rounds, a marvelous maze reaches the exit. Hopefully it was as entertaining and educational for you to solve it as it was for us to put it together.
For today's rounds we went with a Code Jam-finals setup for everyone: 4 hours, 5 problems, lots of problems with the same score. In this way, each contestant can trace their own path, as you have done throughout our history before.
Round A had all problems at newcomer level with all test sets visible, to align with a Coding Practice With Kick Start round. Round B was also fully visible, but had increasingly harder problems and required some techniques, like a Kick Start round. Rounds C and D had hidden test sets, ad-hoc ideas, some more advanced algorithms and data structures, and included an interactive problem, to cover the full spectrum of the Coding Competitions experience.
We also had appearances from Cody-Jamal, pancakes, names of famous computer scientists, a multi-part problem, I/O problem names, faux references to computer-world terms, and quite a few throwbacks to old problems.
Problems from these rounds will be up for practice until June 1st so you can get a chance at all of them before sign-in is disabled on the site.
Thanks to those of you who could join us today, and to everyone who was around in our long history. It has been amazing. Last words are always hard, so we can borrow from Gardel the ending of "Volver" that does fit the moment: "I save hidden a humble hope, which is all the fortune of my heart."
8 6245 876543 374300 350000 378385 21342 46727 112358
1 2 NA D
1 2 6 *Oo*.d *cNCE*
Cast
Colliding Encoding: Written by Shashwat Badoni. Prepared by Jared Gillespie and Pablo Heiber.
Rainbow Sort: Written by Dmitry Brizhinev. Prepared by Shubham Avasthi.
Illumination Optimization: Written by Melisa Halsband. Prepared by Shaohui Qian.
Untie: Written and prepared by Pablo Heiber.
ASCII Art: Written by Bartosz Kostka. Prepared by Anveshi Shukla.
Collecting Pancakes: Written by Anurag Singh. Prepared by Pranav Gavvaji.
Spacious Sets: Written by Bartosz Kostka. Prepared by Deepanshu Aggarwal.
Intruder Outsmarting: Written by Muskan Garg. Prepared by Pablo Heiber and Saki Okubo.
Railroad Maintenance: Written by Emerson Lucena. Prepared by Mahmoud Ezzat.
Railroad Management: Written by Bintao Sun. Prepared by Yu-Che Cheng.
Game Sort: Part 1: Written by Luis Santiago Re and Pablo Heiber. Prepared by Isaac Arvestad and Luis Santiago Re.
Immunization Operation: Written by Chu-ling Ko. Prepared by Shaohui Qian.
Evolutionary Algorithms: Written by Anurag Singh. Prepared by Vinay Khilwani.
The Decades of Coding Competitions: Written by Ashish Gupta. Prepared by Bakuri Tsutskhashvili.
Game Sort: Part 2: Written by Luis Santiago Re. Prepared by Agustín Gutiérrez and Luis Santiago Re.
Indispensable Overpass: Written by Hsin-Yi Wang. Prepared by Shaohui Qian.
Ring-Preserving Networks: Written by Han-sheng Liu. Prepared by Pablo Heiber.
Hey Google, Drive!: Written by Archie Pusaka. Prepared by Chun-nien Chan.
Old Gold: Written and prepared by Ikumi Hide.
Genetic Sequences: Written and prepared by Max Ward.
Solutions and other problem preparation and review by Abhay Pratap Singh, Abhilash Tayade, Abhishek Saini, Aditya Mishra, Advitiya Brijesh, Agustín Gutiérrez, Akshay Mohan, Alan Lou, Alekh Gupta, Alice Kim, Alicja Kluczek, Alikhan Okas, Aman Singh, Andrey Kuznetsov, Anthony, Antonio Mendez, Anuj Asher, Anveshi Shukla, Arghya Pal, Arjun Sanjeev, Arooshi Verma, Artem Iglikov, Ashutosh Bang, Bakuri Tsutskhashvili, Balganym Tulebayeva, Bartosz Kostka, Chu-ling Ko, Chun-nien Chan, Cristhian Bonilha, Deeksha Kaurav, Deepanshu Aggarwal, Dennis Kormalev, Diksha Saxena, Dragos-Paul Vecerdea, Ekanshi Agrawal, Emerson Lucena, Erick Wong, Gagan Kumar, Han-sheng Liu, Harshada Kumbhare, Harshit Agarwala, Hsin-Yi Wang, Ikumi Hide, Indrajit Sinha, Isaac Arvestad, Jared Gillespie, Jasmine Yan, Jayant Sharma, Ji-Gui Zhang, Jin Gyu Lee, John Dethridge, João Medeiros, Junyang Jiang, Katharine Daly, Kevin Tran, Kuilin Wang, Kushagra Srivastava, Lauren Minchin, Lucas Maciel, Luis Santiago Re, Marina Vasilenko, Mary Yang, Max Ward, Mayank Aharwar, Md Mahbubul Hasan, Mo Luo, Mohamed Yosri Ahmed, Mohammad Abu-Amara, Murilo de Lima, Muskan Garg, Nafis Sadique, Nitish Rai, Nurdaulet Akhanov, Olya Kalitova, Ophelia Doan, Osama Fathy, Pablo Heiber, Pawel Zuczek, Raghul Rajasekar, Rahul Goswami, Raymond Kang, Ritesh Kumar, Rohan Garg, Ruiqing Xiang, Sadia Atique, Sakshi Mittal, Salik Mohammad, Samiksha Gupta, Samriddhi Srivastava, Sanyam Garg, Sara Biavaschi, Sarah Young, Sasha Fedorova, Shadman Protik, Shantam Agarwal, Sharmin Mahzabin, Sharvari Gaikwad, Shashwat Badoni, Shu Wang, Shubham Garg, Surya Upadrasta, Swapnil Gupta, Swapnil Mahajan, Tanveer Muttaqueen, Tarun Khullar, Thomas Tan, Timothy Buzzelli, Tushar Jape, Udbhav Chugh, Ulises Mendez Martinez, Umang Goel, Viktoriia Kovalova, Vinay Khilwani, Vishal Som, William Di Luigi, Yang Xiao, Yang Zheng, Yu-Che Cheng, and Zongxin Wu.
Analysis authors:
- Colliding Encoding: Surya Upadrasta.
- Rainbow Sort: Rakesh Theegala.
- Illumination Optimization: Sarah Young.
- Untie: Pablo Heiber.
- ASCII Art: Raghul Rajasekar.
- Collecting Pancakes: Raghul Rajasekar.
- Spacious Sets: Rakesh Theegala.
- Intruder Outsmarting: Ekanshi Agrawal.
- Railroad Maintenance: Cristhian Bonilha.
- Railroad Management: Emerson Lucena.
- Game Sort: Part 1: Mohamed Yosri Ahmed.
- Immunization Operation: Sadia Atique.
- Evolutionary Algorithms: Krists Boitmanis.
- The Decades of Coding Competitions: Chun-nien Chan.
- Game Sort: Part 2: Agustín Gutiérrez.
- Indispensable Overpass: Arooshi Verma.
- Ring-Preserving Networks: Han-sheng Liu.
- Hey Google, Drive!: Chu-ling Ko.
- Old Gold: Evan Dorundo.
- Genetic Sequences: Max Ward.
A. Game Sort: Part 1
Problem
Note: The main parts of the statements of the problems "Game Sort: Part 1" and "Game Sort: Part 2" are identical, except for the last paragraph. The problems can otherwise be solved independently.
Amir and Badari are playing a sorting game. The game starts with a string $$$\mathbf{S}$$$ and an integer
$$$\mathbf{P}$$$ being chosen by an impartial judge. Then, Amir has to split $$$\mathbf{S}$$$ into exactly $$$\mathbf{P}$$$ contiguous
non-empty parts (substrings). For example, if $$$\mathbf{S} = \vphantom{}$$$CODEJAM was
the chosen string and $$$\mathbf{P} = 3$$$, Amir could split it up as [COD, EJA,
M] or as [CO, D, EJAM], but not as
[COD, EJAM], [COD, JA, M],
[EJA, COD, M], nor as
[CODE, EJA, M].
Given the partition Amir made, can you help Badari win the game, or say that it is not possible?
Input
The first line of the input gives the number of test cases, $$$\mathbf{T}$$$. $$$\mathbf{T}$$$ test cases follow. Each test case consists of two lines. The first line of a test case contains a single integer $$$\mathbf{P}$$$, the number of parts Amir made. The second line contains $$$\mathbf{P}$$$ strings $$$\mathbf{S_1}, \mathbf{S_2}, \dots, \mathbf{S_P}$$$, representing the $$$\mathbf{P}$$$ parts, in order.
Output
For each test case, output one line containing Case #$$$x$$$: $$$y$$$,
where $$$x$$$ is the test case number (starting from 1) and $$$y$$$ is either POSSIBLE
if Badari can win the game, or IMPOSSIBLE if she cannot. If she can win the game,
output a second line containing $$$t_1 ~ t_2 ~ \dots ~ t_{\mathbf{P}}$$$ where
$$$t_i$$$ is a rearrangement of the letters of $$$\mathbf{S_i}$$$, and $$$t_i$$$ is lexicographically earlier
than or equal to $$$t_{i+1}$$$, for all $$$i$$$. If there are multiple solutions, you may output
any one of them.
Limits
Time limit: 5 seconds.
Memory limit: 2 GB.
$$$1 \le \mathbf{T} \le 100$$$.
Each character of $$$\mathbf{S_i}$$$ is an English uppercase letter A through Z,
for all $$$i$$$.
Test Set 1 (Visible Verdict)
$$$2 \le \mathbf{P} \le 3$$$.
$$$1 \le $$$ the length of $$$\mathbf{S_i} \le 8$$$, for all $$$i$$$.
Test Set 2 (Hidden Verdict)
$$$2 \le \mathbf{P} \le 100$$$.
$$$1 \le $$$ the length of $$$\mathbf{S_i} \le 100$$$, for all $$$i$$$.
Sample
3 3 CO DEJ AM 3 CODE JA M 2 ABABABAB AAA
Case #1: POSSIBLE CO DEJ MA Case #2: POSSIBLE CODE JA M Case #3: IMPOSSIBLE
In Sample Case #1, Badari could also win in $$$5$$$ other ways. Two of them are
[CO, JED, MA] and
[CO, EJD, MA].
In Sample Case #2, Badari can win simply by leaving all parts as Amir gave it to her, but other ways are also possible.
In Sample Case #3 Amir has guaranteed a win for himself leaving Badari no winning option.
B. Immunization Operation
Problem
Making every vaccine available to the entire world population is a complicated problem in many respects. Ñambi is leading the charge to optimize delivery. To reduce the access barriers as much as possible, she is trying to have automated robots deliver and apply vaccines directly in patients' homes.
In the current iteration, the robot that Ñambi is designing will work on a single street that runs from west to east. As such, the robot accepts a single command 'move $$$x$$$ meters'. If $$$x$$$ is positive, the robot moves $$$x$$$ meters to the east. If $$$x$$$ is negative, the robot moves $$$-x$$$ meters to the west.
The robot is loaded at the start of the day with the information about all immunizations it must provide that day. Each of these pieces of information consists of the current location of the vaccine, for pickup, and the location of the patient that must receive it, for delivery. Each vaccine is custom-made for one patient. Of course, the delivery location of a vaccine is never the same as its own pickup location. The robot must pick up the vaccine before it delivers it to the patient.
The robot is programmed to automatically pick up and load onto its cargo area vaccines when it passes through their pickup locations for the first time. The robot is also programmed to deliver the vaccine to its recipient as soon as it passes through their location if the vaccine was already picked up. Ñambi wants to track how many vaccinations happen after each movement command. A vaccination happens when the vaccine is delivered. Notice that the vaccine might be picked up during any of the previous commands, or during the same command, but before delivery.
The following picture illustrates one possible scenario (Sample Case #1 below). The smiley face represents the initial position of the robot, and the long black line is the street. The marks above the line are the pickup locations and the marks below are the delivery locations. Finally, the arrows below represent the moves the robot makes, in order from top to bottom, labeled with how many deliveries are completed during the move.
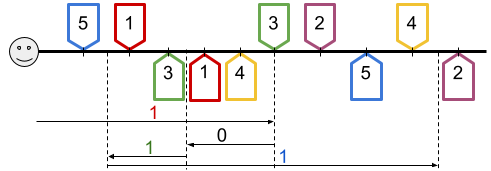
This is what happens during each move, in order:
- Move 1. The robot picks up vaccines $$$5$$$ and $$$1$$$, then delivers vaccine $$$1$$$, and then picks up vaccine $$$3$$$ just as the move is finishing. Notice that the robot passes through the delivery location for vaccine $$$3$$$, but since that happens before picking vaccine $$$3$$$ up, it cannot deliver it.
- Move 2. The robot passes through the delivery locations of vaccines $$$1$$$ and $$$4$$$. However, vaccine $$$1$$$ is already delivered and vaccine $$$4$$$ has not been picked up, so no vaccination is finished.
- Move 3. The robot delivers vaccine $$$3$$$.
- Move 4. The robot picks up vaccine $$$2$$$, delivers vaccine $$$5$$$ and picks up vaccine $$$4$$$.
Notice that vaccine $$$2$$$ and $$$4$$$ were picked up but not delivered because the delivery location of vaccine $$$2$$$ was never reached, and the delivery location of vaccine $$$4$$$ was not reached after the vaccine had been picked up.
Given the list of immunizations to be given and the list of moving commands to be executed by the robot in order, compute how many vaccinations are completed after each command.
Input
The first line of the input gives the number of test cases, $$$\mathbf{T}$$$. $$$\mathbf{T}$$$ test cases follow. Each test case consists of $$$4$$$ lines. The first line of a test case contains $$$2$$$ integers $$$\mathbf{V}$$$ and $$$\mathbf{M}$$$, the number of vaccinations and the number of move commands.
The second line of a test case contains $$$\mathbf{V}$$$ integers $$$\mathbf{P_1}, \mathbf{P_2}, \dots, \mathbf{P_V}$$$, representing that the $$$i$$$-th vaccine must be picked up exactly $$$\mathbf{P_i}$$$ meters to the east of the robot's initial location. Note that several vaccines can have the same pickup location.The third line contains $$$\mathbf{V}$$$ integers $$$\mathbf{D_1}, \mathbf{D_2}, \dots, \mathbf{D_V}$$$, representing that the $$$i$$$-th vaccine must be delivered exactly $$$\mathbf{D_i}$$$ meters to the east of the robot's initial location. Note that several vaccines can have the same delivery location.
The final line of a test case contains $$$\mathbf{M}$$$ integers $$$\mathbf{X_1}, \mathbf{X_2}, \dots, \mathbf{X_M}$$$, where the absolute value of $$$\mathbf{X_j}$$$ is the number of meters the robot must move for the $$$j$$$-th movement command. The $$$j$$$-th move must be towards the east if $$$\mathbf{X_j}$$$ is positive, and towards the west if it is negative. Notice that the vaccinations can happen in an order different than the numbering of the input, but movement commands happen in the given order.
Output
For each test case, output one line containing
Case #$$$x$$$: $$$y_1 ~ y_2 ~ \dots ~ y_{\mathbf{M}}$$$,
where $$$x$$$ is the test case number (starting from 1) and $$$y_j$$$ is the number of vaccinations
completed while performing the $$$j$$$-th given movement command.
Limits
Memory limit: 2 GB.
$$$1 \le \mathbf{T} \le 100$$$.
$$$1 \le \mathbf{P_i} \le 10^9$$$, for all $$$i$$$.
$$$1 \le \mathbf{D_i} \le 10^9$$$, for all $$$i$$$.
$$$\mathbf{P_i} \neq \mathbf{D_i}$$$, for all $$$i$$$.
$$$-10^9 \le \mathbf{X_j} \le 10^9$$$, for all $$$j$$$.
$$$\mathbf{X_j} \ne 0$$$, for all $$$j$$$.
Test Set 1 (Visible Verdict)
Time limit: 20 seconds.
$$$1 \le \mathbf{V} \le 100$$$.
$$$1 \le \mathbf{M} \le 100$$$.
Test Set 2 (Hidden Verdict)
Time limit: 40 seconds.
$$$1 \le \mathbf{V} \le 10^5$$$.
$$$1 \le \mathbf{M} \le 10^5$$$.
Sample
4 5 4 121 312 271 422 75 199 464 160 234 368 271 -109 -70 371 2 2 1 3 4 4 4 -1 2 2 1 4 4 3 4 -1 1 10 1 2 -987654321 -987654321 -987654321 -987654321 -987654321 987654321 987654321 987654321 987654321 987654323
Case #1: 1 0 1 1 Case #2: 2 0 Case #3: 1 1 Case #4: 0 0 0 0 0 0 0 0 0 1
Sample Case #1 is the one explained and illustrated in the problem statement.
In Sample Case #2 and Sample Case #3, notice that it is possible to pick up and deliver vaccines in the same move only if the pickup place is visited first. In addition, notice that it is possible pick up and to deliver exactly as a move is ending.
Sample Case #4, the robot moves $$$987654321$$$ meters to the west five times, then $$$987654321$$$ meters to the east four times, then $$$987654323$$$ meters to the east. The only pickup and delivery are both made in the final move. Note that the commands can be very extreme so the robot can be at some point very far away from its initial position, either west or east.
C. Evolutionary Algorithms
Problem
Ada is working on a science project for school. She is studying evolution and she would like to compare how different species of organisms would perform when trying to solve a coding competition problem.
The $$$\mathbf{N}$$$ species are numbered with integers between $$$1$$$ and $$$\mathbf{N}$$$, inclusive. Species $$$1$$$ has no direct ancestor, and all other species have exactly one direct ancestor each, from which they directly evolved. A (not necessarily direct) ancestor of species $$$x$$$ is any other species $$$y$$$ such that $$$y$$$ can be reached from $$$x$$$ by moving one or more times to a species direct ancestor starting from $$$x$$$. In this way, species $$$1$$$ is a (direct or indirect) ancestor of every other species.
Through complex genetic simulations, she calculated the average score each of the $$$\mathbf{N}$$$ species would get in a particular coding competition. $$$\mathbf{S_i}$$$ is that average score for species $$$i$$$.
Ada is looking for interesting triplets to showcase in her presentation. An interesting triplet is defined as an ordered triplet of distinct species $$$(a, b, c)$$$ such that:
- Species $$$b$$$ is a (direct or indirect) ancestor of species $$$a$$$.
- Species $$$b$$$ is not a (direct or indirect) ancestor of species $$$c$$$.
- Species $$$b$$$ has an average score strictly more than $$$\mathbf{K}$$$ times higher than both of those of $$$a$$$ and $$$c$$$. That is, $$$\mathbf{S_b} \ge \mathbf{K} \times \max(\mathbf{S_a}, \mathbf{S_c}) + 1$$$.
Given the species scores and ancestry relationships, help Ada by writing a program to count the total number of interesting triplets.
Input
The first line of the input gives the number of test cases, $$$\mathbf{T}$$$. $$$\mathbf{T}$$$ test
cases follow.
The first line of each test case contains two integers $$$\mathbf{N}$$$ and $$$\mathbf{K}$$$, denoting the number of species
and the factor which determines interesting triplets, respectively.
The second line of each test case contains $$$\mathbf{N}$$$ integers $$$\mathbf{S_1}, \mathbf{S_2}, \dots, \mathbf{S_N}$$$, where
$$$\mathbf{S_i}$$$ denotes the average score of species $$$i$$$.
The third line of each test case contains $$$\mathbf{N}-1$$$ integers $$$\mathbf{P_2}, \mathbf{P_3}, \dots, \mathbf{P_N}$$$,
meaning species $$$\mathbf{P_i}$$$ is the direct ancestor of species $$$i$$$.
Output
For each test case, output one line containing
Case #$$$x$$$: $$$y$$$, where $$$x$$$ is the test case number
(starting from 1) and $$$y$$$ is the total number of interesting triplets according to Ada's
definition.
Limits
Time limit: 40 seconds.
Memory limit: 2 GB.
$$$1 \le \mathbf{T} \le 100$$$.
$$$1 \le \mathbf{K} \le 10^9$$$.
$$$1 \le \mathbf{S_i} \le 10^9$$$, for all $$$i$$$.
$$$1 \le \mathbf{P_i} \le \mathbf{N}$$$, for all $$$i$$$.
Species $$$1$$$ is a (direct or indirect) ancestor of all other species.
Test Set 1 (Visible Verdict)
$$$3 \le \mathbf{N} \le 1000$$$.
Test Set 2 (Hidden Verdict)
For at most 30 cases:
$$$3 \le \mathbf{N} \le 2 \times 10^5$$$.
For the remaining cases:
$$$3 \le \mathbf{N} \le 1000$$$.
Sample
2 5 2 3 3 6 2 2 3 1 1 3 7 3 2 4 7 2 2 1 8 6 1 7 3 1 3
Case #1: 1 Case #2: 7
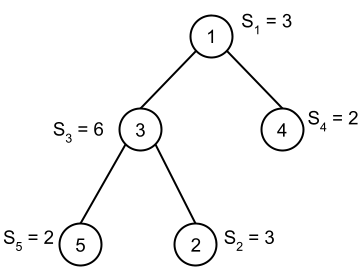
In Sample Case #1, there is only one possible interesting triplet: $$$(5, 3, 4)$$$. Indeed, we can verify that:
- Species $$$b = 3$$$ is an ancestor of species $$$a = 5$$$.
- Species $$$b = 3$$$ is not an ancestor of species $$$c = 4$$$.
- The score of species $$$b = 3$$$ is more than $$$\mathbf{K}$$$ times higher than the scores of both $$$a = 5$$$ and $$$c = 4$$$: $$$6 = \mathbf{S_3} \ge \mathbf{K} \times \max(\mathbf{S_4}, \mathbf{S_5}) + 1 = 2 \times \max(2, 2) + 1 = 5$$$.
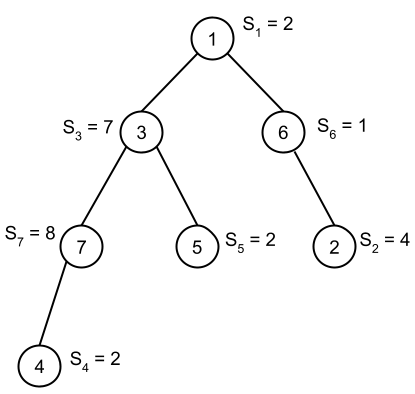
In Sample Case #2, there are seven interesting triplets:
- $$$(4, 3, 1)$$$
- $$$(4, 3, 6)$$$
- $$$(4, 7, 1)$$$
- $$$(4, 7, 5)$$$
- $$$(4, 7, 6)$$$
- $$$(5, 3, 1)$$$
- $$$(5, 3, 6)$$$
D. The Decades of Coding Competitions
Problem
It has been almost $$$15$$$ years since Sphinny became the premiere programming contestant by mastering the art of scheduling contests. She has grown alongside Coding Competitions and graduated into a programming contest organizer, and her Programming Club League (PCL) is the most popular sport in her city.
There are $$$\mathbf{N}$$$ bus stops in Sphinny's city, and $$$\mathbf{M}$$$ express bus routes. Each route bidirectionally connects two different bus stops, called their endpoints. Because of the popularity of PCL, the driver of each bus routes cheers for exactly one club.
Sphinny has to pick up the contest materials for the $$$j$$$-th contest at bus stop $$$\mathbf{P_j}$$$ and then the contest will be run in bus stop $$$\mathbf{C_j}$$$. She can only use the given bus routes to travel between them. Formally, a path for Sphinny to go from $$$\mathbf{P_j}$$$ to $$$\mathbf{C_j}$$$ is a list of bus routes such that each two consecutive routes have a common endpoint. Also the first route in the path has $$$\mathbf{P_j}$$$ as an endpoint and the last one has $$$\mathbf{C_j}$$$ as an endpoint. Notice that the same bus route can be used multiple times in a path. If Sphinny's path from $$$\mathbf{P_j}$$$ to $$$\mathbf{C_j}$$$ contains one or more bus routes whose driver cheers for club $$$c$$$, then club $$$c$$$ will join the contest. Otherwise, club $$$c$$$ will not join the contest. For organizational reasons, Sphinny needs the number of clubs in each contest to be an odd number.
Given the layout of Sphinny's city's bus routes and the contests' details, find out for how many contests there exists a path for Sphinny to take that can ensure an odd number of clubs joining it.
Input
The first line of the input gives the number of test cases, $$$\mathbf{T}$$$. $$$\mathbf{T}$$$ test
cases follow.
The first line of each test case contains three integers $$$\mathbf{N}$$$, $$$\mathbf{M}$$$, and $$$\mathbf{Q}$$$:
the number of bus stops, bus routes, and contests, respectively.
Then, $$$\mathbf{M}$$$ lines follow representing a different bus route each. The $$$i$$$-th of these lines contains three integers $$$\mathbf{U_i}$$$, $$$\mathbf{V_i}$$$, and $$$\mathbf{K_i}$$$, meaning that the $$$i$$$-th bus route connects bus stops $$$\mathbf{U_i}$$$ and $$$\mathbf{V_i}$$$ and its driver cheers for club $$$\mathbf{K_i}$$$.
Finally, the last $$$\mathbf{Q}$$$ lines represent a contest each. The $$$j$$$-th of these lines contains two integers $$$\mathbf{P_j}$$$ and $$$\mathbf{C_j}$$$, representing that materials for the $$$j$$$-th contest need to be picked up at bus stop $$$\mathbf{P_j}$$$ and the contest needs to be run at bus stop $$$\mathbf{C_j}$$$.
Output
For each test case, output one line containing
Case #$$$x$$$: $$$y$$$, where $$$x$$$ is the test case number
(starting from 1) and $$$y$$$ is the number of contests for which Sphinny can find a path
that ensures an odd number of clubs join it.
Limits
Memory limit: 2 GB.
$$$1 \le \mathbf{T} \le 100$$$.
$$$1 \le \mathbf{U_i} \le \mathbf{N}$$$, for all $$$i$$$.
$$$1 \le \mathbf{V_i} \le \mathbf{N}$$$, for all $$$i$$$.
$$$\mathbf{U_i} \neq \mathbf{V_i}$$$, for all $$$i$$$
$$$(\mathbf{U_i}, \mathbf{V_i}) \neq (\mathbf{U_j}, \mathbf{V_j})$$$ and $$$(\mathbf{U_i}, \mathbf{V_i}) \neq (\mathbf{V_j}, \mathbf{U_j})$$$,
for all $$$i \neq j$$$. (No two bus routes
have the same pair of endpoints.)
$$$1 \le \mathbf{P_j} \le \mathbf{N}$$$, for all $$$j$$$.
$$$1 \le \mathbf{C_j} \le \mathbf{N}$$$, for all $$$j$$$.
$$$\mathbf{P_j} \neq \mathbf{C_j}$$$, for all $$$j$$$.
Test Set 1 (Visible Verdict)
Time limit: 20 seconds.
$$$2 \le \mathbf{N} \le 500$$$.
$$$1 \le \mathbf{M} \le 500$$$.
$$$1 \le \mathbf{Q} \le 500$$$.
$$$1 \le \mathbf{K_j} \le 2$$$, for all $$$j$$$.
Test Set 2 (Visible Verdict)
Time limit: 40 seconds.
$$$2 \le \mathbf{N} \le 500$$$.
$$$1 \le \mathbf{M} \le 500$$$.
$$$1 \le \mathbf{Q} \le 500$$$.
$$$1 \le \mathbf{K_j} \le 100$$$, for all $$$j$$$.
Test Set 3 (Hidden Verdict)
Time limit: 120 seconds.
$$$2 \le \mathbf{N} \le 10000$$$.
$$$1 \le \mathbf{M} \le 10000$$$.
$$$1 \le \mathbf{Q} \le 10000$$$.
$$$1 \le \mathbf{K_j} \le 100$$$, for all $$$j$$$.
Sample
Note: there are additional samples that are not run on submissions down below.2 5 5 3 1 2 1 2 3 2 2 4 1 2 5 1 4 5 1 1 3 3 4 5 1 3 1 2 1 3 1 1 2 1 3
Case #1: 1 Case #2: 1
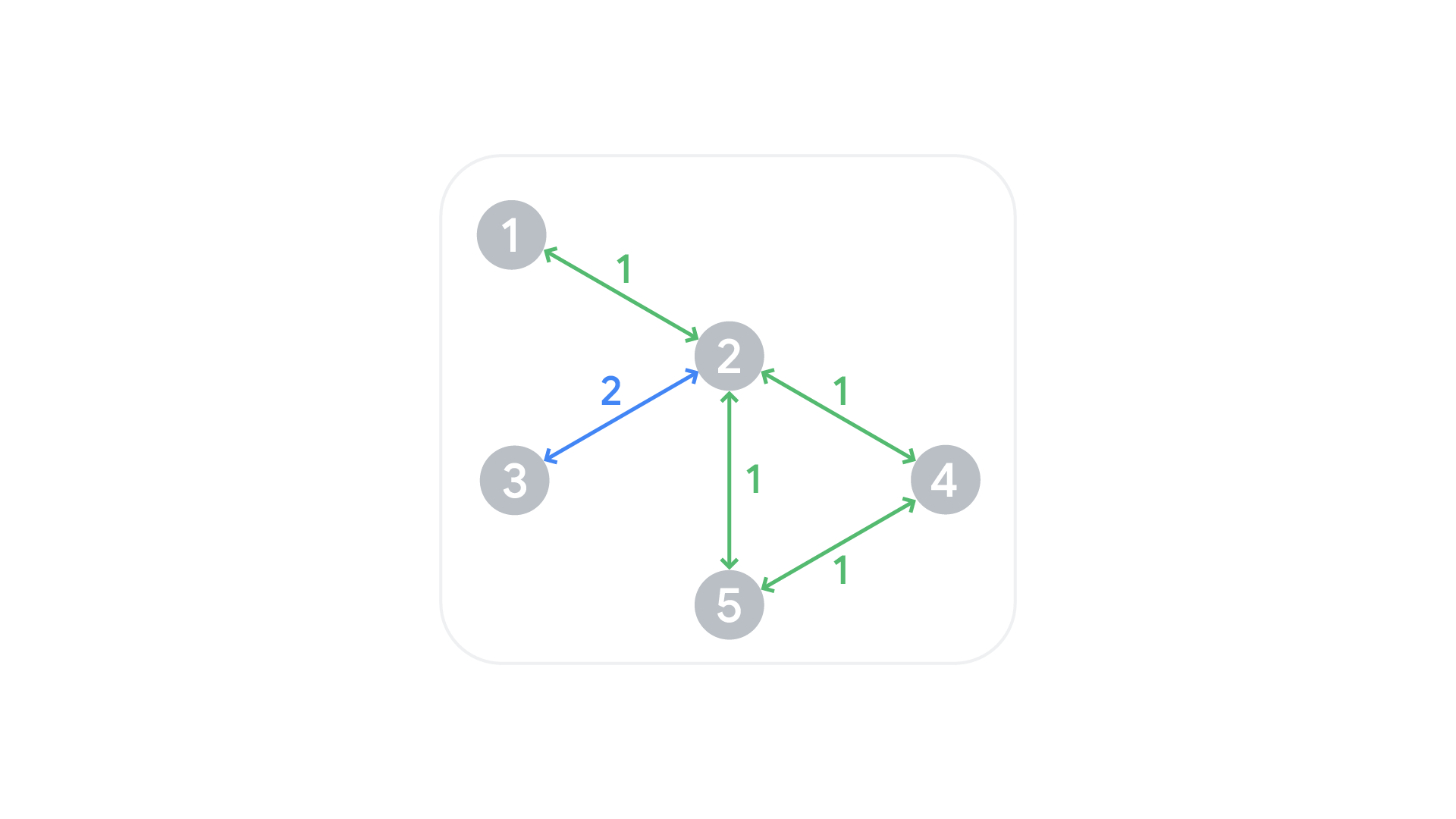
Sample Case #1 is pictured above. In the first two contests, both clubs (green and blue) must be involved in it no matter what path is chosen. For the last contest, it is possible to involve only the green club by using the path through bus stops $$$1, 2, 4, 5$$$.
For Sample Case #2, the first contest is not possible because there is no path to go from bus stop $$$1$$$ to bus stop $$$2$$$. For the second contest, there is a path including the only bus route going bus stop $$$1$$$ to bus stop $$$3$$$, therefore yielding a contest involving exactly $$$1$$$ club, which is an acceptable odd number of clubs.
Additional Sample - Test Set 2
The following additional sample fits the limits of Test Set 2. It will not be run against your submitted solutions.1 4 5 2 1 2 3 1 3 3 3 4 7 2 3 3 2 4 6 1 2 1 4
Case #1: 2
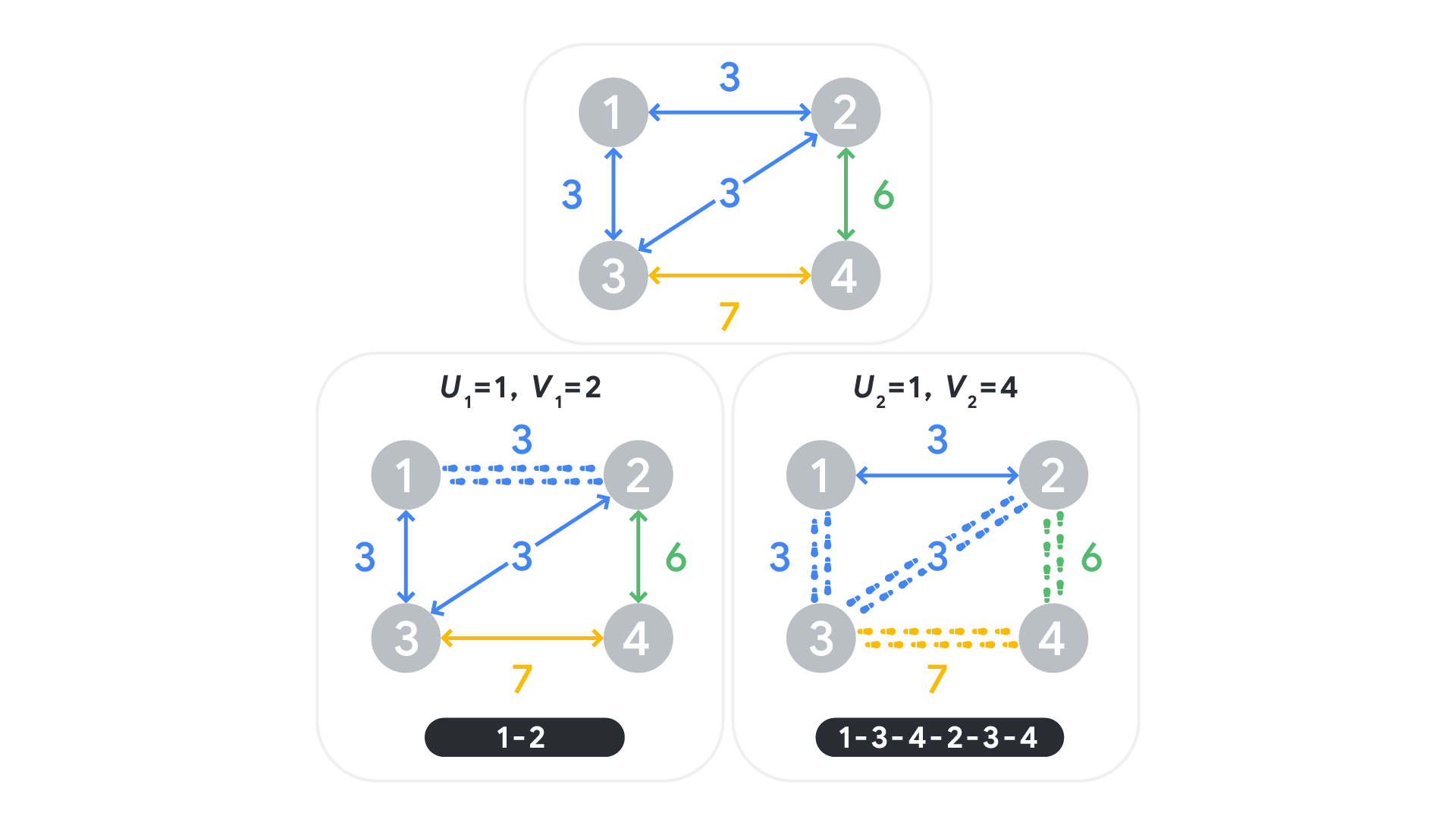
This additional Sample Case is pictured above. In this case, both contests can be done with an odd number of clubs. An example path that achieves that is shown in the picture.
E. Game Sort: Part 2
Problem
Note: The main parts of the statements of the problems "Game Sort: Part 1" and "Game Sort: Part 2" are identical, except for the last paragraph. The problems can otherwise be solved independently.
Amir and Badari are playing a sorting game. The game starts with a string $$$\mathbf{S}$$$ and an integer
$$$\mathbf{P}$$$ being chosen by an impartial judge. Then, Amir has to split $$$\mathbf{S}$$$ into exactly $$$\mathbf{P}$$$ contiguous
non-empty parts (substrings). For example, if $$$\mathbf{S} = \vphantom{}$$$CODEJAM was
the chosen string and $$$\mathbf{P} = 3$$$, Amir could split it up as [COD, EJA,
M] or as [CO, D, EJAM], but not as
[COD, EJAM], [COD, JA, M],
[EJA, COD, M], nor as
[CODE, EJA, M].
Given the initial string and number of parts, can you help Amir win the game by choosing his parts in a way Badari cannot win herself? If not, say that it is not possible.
Input
The first line of the input gives the number of test cases, $$$\mathbf{T}$$$. $$$\mathbf{T}$$$ lines follow, each describing a single test case containing an integer $$$\mathbf{P}$$$ and a string $$$\mathbf{S}$$$, the number of parts and string to be partitioned, respectively.
Output
For each test case, output one line containing Case #$$$x$$$: $$$y$$$,
where $$$x$$$ is the test case number (starting from 1) and $$$y$$$ is either POSSIBLE
if Amir can win the game, or IMPOSSIBLE if he cannot. If he can win the game,
output a second line containing $$$t_1 ~ t_2 ~ \dots ~ t_{\mathbf{P}}$$$ where
$$$t_i$$$ is a the $$$i$$$-th part of the winning partition you found for Amir. If there are
multiple solutions, you may output any one of them.
Limits
Time limit: 40 seconds.
Memory limit: 2 GB.
$$$1 \le \mathbf{T} \le 100$$$.
Each character of $$$\mathbf{S}$$$ is an English uppercase letter A through Z.
Test Set 1 (Visible Verdict)
$$$2 \le \mathbf{P} \le 3$$$.
$$$\mathbf{P} \le $$$ the length of $$$\mathbf{S} \le 100$$$.
Test Set 2 (Hidden Verdict)
$$$2 \le \mathbf{P} \le 100$$$.
$$$\mathbf{P} \le $$$ the length of $$$\mathbf{S} \le 10^5$$$.
Sample
3 3 CODEJAM 2 ABABABABAAAA 3 AABBCDEEFGHIJJKLMNOPQRRSTUVWXYZZ
Case #1: POSSIBLE C O DEJAM Case #2: POSSIBLE ABABABABA AAA Case #3: IMPOSSIBLE
In Sample Case #1, there is no way for Badari to rearrange DEJAM to be
lexicographically after O, so Amir guaranteed a win.
In Sample Case #2, AAA is guaranteed to be earlier than any rearrangement
of a string containing more than $$$3$$$ letters, so Amir also wins.
In Sample Case #3, all possible partitions result in a list of parts that is already sorted in lexicographical order, so Amir cannot possibly win.
Analysis — A. Game Sort: Part 1
Test Set 1
In Test Set 1, the initial idea is to try all possible permutations of each part, but the limits are not small enough to try everything. We observe that it is always better to sort the first part to be the (lexicographically) smallest possible permutation, and to sort the last part to be the (lexicographically) largest possible permutation. Then we can try all permutations of the middle part (there are at most $$$8!$$$) and check if any of them makes all parts sorted in non-decreasing lexicographical order.
Test Set 2
For Test Set 2 we need a different approach, as there are too many permutations per part to try. We observe that, for each part, it is best to make it the smallest possible permutation that is not smaller than the previous part (or the smallest permutation in case of the first part). By doing so, we give the next part more opportunities (if any) to be a permutation that is not smaller than the current part.
We see that the best permutation of the current part is the one that shares the longest common prefix with the previous part, such that one of the following conditions holds:
- There is a character we can append to that prefix in the current part that is larger than the next character in the previous part; or
- The whole previous part is a prefix of the current part.
One way to do this is to maintain a count of each character per part. When we are at a part, we need to find the longest common prefix with the previous part, subject to the condition above.
The solution above only requires a constant number of scans for each part. This makes the algorithm $$$O(\sum_{i} |\mathbf{S_i}|)$$$, which works for the problem constraints. However, less efficient implementations can also pass.
Analysis — B. Immunization Operation
Test Set 1
We can simulate each query. First, we can store all the vaccines and the patients in an ordered data structure. Then, for each query, we can go through the range from start to end positions, maintain the list of picked up vaccines, and each time we encounter a patient whose vaccine is picked up and has not been administered yet, we mark them as vaccinated. This can give us the count of vaccinated patients for every move. For each query, there will be at most $$$O(\mathbf{V})$$$ patients and vaccines we will encounter. Saving the picked up vaccine and looking up if we can vaccinate someone with the available vaccines can be done in $$$O(\log\mathbf{V})$$$ using a set-like data structure. So the total time complexity of this approach is $$$O(\mathbf{M} \times \mathbf{V}\log\mathbf{V})$$$, which is sufficient for Test Set 1.
Test Set 2
For Test Set 2, we need to optimize the simulation. One important observation here is that for each patient who is located to the east side of their vaccine, they would be vaccinated when the robot is moving in the east direction. Let us consider two cases where that can happen. The vaccine is at $$$x$$$, the patient at $$$y$$$, and $$$y$$$ > $$$x$$$ (the patient is on the east of the vaccine). Let us assume the move range from $$$r_1$$$ to $$$r_2$$$.
- The move range covers both the vaccine and the patient. The vaccine will be picked up, and then
the patient will be vaccinated in the same move.

- The move covers only the vaccine, not the patient. The vaccine will be picked in this move and
the robot will finish at position $$$r_2$$$.
To complete the vaccination, the robot needs to go to $$$y$$$, so it must move in the east
direction to come to position $$$y$$$.

The same can be said about the patients who are on the west side of their vaccines, that they will be vaccinated when the robot is moving in the west direction. With this insight, we can process these two types of cases separately. Let us call them east case (where patients will be vaccinated in an east move) and west case (where patients will be vaccinated in a west move).
For the east cases, we can keep track of the farthest right point $$$Max_R$$$ that the robot visited so far. When the robot is making an east move with the range ($$$r_1$$$,$$$r_2$$$] and $$$r_2$$$ is on the west of the $$$Max_R$$$, then this range has been already visited by the robot, and nothing new happens. Otherwise, we can count the east case patients in that range(max($$$r_1$$$, $$$Max_R$$$), $$$r_2$$$], and that count will be the answer of the query. Since each patient can be vaccinated only once, this does not take longer than $$$O(\mathbf{V})$$$ time in total.
For the west cases, this simple strategy does not work, because we need to know not just the farthest right point, but also all the west case vaccines that have been picked in previous moves, and not used yet. Since the robot starts at position 0, and the vaccines and patients are always on the positive coordinates, for any west move that visits a patient, their vaccine is already picked up in one of the past east moves. So we can maintain an ordered list of west case patients whose vaccines have been picked during the previous east moves, and in each west move, find the number of patients in that move range from the list. We should later delete those patients. Since each patient will be counted and deleted only once, and we can complete each find, insert, delete operations in $$$O(\log\mathbf{V})$$$ time, the total time complexity here is $$$O(\mathbf{V} \log\mathbf{V})$$$. The overall time complexity of the whole solution is $$$O(\mathbf{M} + \mathbf{V} + \mathbf{V} \log\mathbf{V})$$$, which is sufficient for Test Set 2. $$$O(\mathbf{M})$$$ is included since we need to go through each query once at least.
Analysis — C. Evolutionary Algorithms
From the definition of an interesting triplet $$$(a,b,c)$$$, it is clear that the node $$$b$$$ has a central role, so let us find the number of interesting triplets for a fixed node $$$b$$$. If $$$A_b$$$ is the number of nodes $$$a$$$ in the subtree of $$$b$$$ such that $$$\mathbf{S_b} \gt \mathbf{K} \times \mathbf{S_a}$$$ and $$$C_b$$$ is the number of nodes $$$c$$$ outside the subtree of $$$b$$$ such that $$$\mathbf{S_b} \gt \mathbf{K} \times \mathbf{S_c}$$$, then the number of interesting triplets with the given middle node $$$b$$$ is $$$A_b \times C_b$$$. The answer is the sum $$$\sum_{b=1}^\mathbf{N} A_b \times C_b$$$ of contributions over all nodes $$$b$$$.
Test Set 1
The constraint $$$\mathbf{N} \le 1000$$$ suggests that we are a looking for a quadratic algorithm. If we manage to compute $$$A_b$$$ and $$$C_b$$$ in linear time for a fixed node $$$b$$$, we would obtain a solution with the overall time complexity $$$O(\mathbf{N}^2)$$$.
For a fixed node $$$b$$$, $$$A_b$$$ can be computed by performing a Depth-first search (DFS) rooted at the node $$$b$$$ and verifying the inequality for each and every node. As for $$$C_b$$$, we can do a linear search and count the total number $$$X$$$ of nodes $$$x$$$ such that $$$\mathbf{S_b} \gt \mathbf{K} \times \mathbf{S_x}$$$ holds. Then $$$C_b=X-A_b$$$.
Test Set 2
For the large test set, the general idea remains the same. However, we cannot afford to spend linear time to compute $$$A_b$$$ and $$$C_b$$$. It seems like we need a data structure $$$D$$$ that supports the following queries efficiently:
- What is the number of nodes $$$a$$$ in the subtree rooted at $$$b$$$ such that $$$\mathbf{S_b} \gt \mathbf{K} \times \mathbf{S_a}$$$?
- What is the total number of nodes $$$x$$$ such that $$$\mathbf{S_b} \gt \mathbf{K} \times \mathbf{S_x}$$$?
That sounds complicated though. Fortunately, we can simplify these questions a great deal if we process the nodes $$$b$$$ in a non-decreasing order by $$$\mathbf{S_b}$$$. Then, by using a two pointer technique, we can make sure that the data structure $$$D$$$ contains precisely the nodes $$$x$$$ such that $$$\mathbf{S_b} \gt \mathbf{K} \times \mathbf{S_x}$$$ and nothing else. Now the above questions can be translated as follows:
- How many nodes of $$$D$$$ are in the subtree rooted at $$$b$$$?
- What is the size of $$$D$$$?
A very efficient technique for testing if a node $$$a$$$ is in the subtree of the node $$$b$$$ is called tree flattening. Essentially, we perform a post-order tree traversal to compute the labels $$$end(v)$$$ for each node $$$v$$$, which are shown at the right side of each node in the following illustration. Moreover, using the same DFS traversal, we compute the label $$$start(v)$$$ for each node $$$v$$$ (shown at the left side of nodes in the example), which is the minimum $$$end(u)$$$ over all nodes $$$u$$$ in the subtree of $$$v$$$. Then a node $$$a$$$ is in the subtree rooted at $$$b$$$ if and only if $$$start(b) \le end(a) \le end(b)$$$.
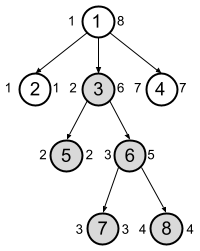
For example, the set of labels $$$end(v)$$$ of all nodes in the subtree of node $$$3$$$ in the above drawing form a consecutive interval $$$[2,6]$$$, which is conveniently stored as $$$[start(3),end(3)]$$$, hence, a node $$$v$$$ belongs to the subtree of node $$$3$$$ if and only if $$$2 \le end(v) \le 6$$$.
Answering the first question now seems a lot like a range query that a segment tree or a Fenwick tree is a perfect fit for. For example, we can use a segment tree $$$D$$$ on the range $$$[1,\mathbf{N}]$$$, which is initially empty, namely, $$$D[i]=0$$$ for all $$$i$$$. Whenever we add a node $$$v$$$ to $$$D$$$, we modify the segment tree to set $$$D[end(v)]=1$$$. It is important to note that we are marking the presence of a node at the position $$$end(v)$$$ of the segment tree rather than $$$v$$$ itself. In this way, a range query $$$D[start(b),end(b)]$$$ returns the number of nodes $$$a$$$ that are in the subtree of $$$b$$$ and present in $$$D$$$.
The time complexity of this solution is $$$O(\mathbf{N} \log \mathbf{N})$$$ because of the sorting and $$$2\mathbf{N}$$$ segment tree operations.
Analysis — D. The Decades of Coding Competitions
Let's start by treating the city as a graph, where nodes represent bus stops, edges represent bus routes, and a label on each edge represents the club cheered on by the bus route driver.
There is a key observation for this problem: if two nodes $$$\mathbf{P_j}$$$ and $$$\mathbf{C_j}$$$ are connected, we would be able to traverse all the edges in the connected component in the path from $$$\mathbf{P_j}$$$ to $$$\mathbf{C_j}$$$. The proof for this observation is provided at the end of this analysis. With this observation, we can find that if the total number of distinct edge clubs in this connected component is odd, there is always a path from $$$\mathbf{P_j}$$$ to $$$\mathbf{C_j}$$$ that can walk on an odd number of clubs by traversing all the edges in the connected component at least once.
Therefore, for each query, we can check if there exists a subgraph that satisfies:
- $$$\mathbf{P_j}$$$ and $$$\mathbf{C_j}$$$ are connected.
- There is an odd number of distinct edge clubs in the connected component that contains $$$\mathbf{P_j}$$$ and $$$\mathbf{C_j}$$$.
Test Set 1
Since the number of distinct clubs $$$\mathbf{K}$$$ is small in Test Set 1, we can enumerate all combinations of an odd number of distinct clubs. For each combination, build a new graph $$$G'$$$ by removing edges with clubs not in the combination. Afterwards, for each query we can check if $$$\mathbf{P_j}$$$and $$$\mathbf{C_j}$$$ are connected in any $$$G'$$$, and if there is an odd number of edge clubs in the corresponding connected component by iterating through all the edges in the connected component.
We can use Disjoint Set Union (DSU) to find the connected componnets in $$$G'$$$ and all the nodes and edges in them. A connected component has edge club $$$c$$$ if and only if $$$u$$$ and $$$v$$$ are in this component (in the same set in DSU) and the edge $$$(u, v)$$$ has club $$$c$$$. We can prebuild the DSU for all $$$G'$$$s and find the number of distinct clubs for each of the connected component in them. For each query, we can iterate through all prebuilt DSUs and check if $$$\mathbf{P_j}$$$ and $$$\mathbf{C_j}$$$ are connected in a component with odd number of edge clubs in it.
Space complexity:
There are at most $$$2^\mathbf{K}$$$ $$$G'$$$s, and each graph has at most $$$\mathbf{N}$$$ connected components:
- Disjoint Set Unions(DSUs): $$$O(2^\mathbf{K} \times \mathbf{N})$$$
- Number of distinct clubs in connected components in graphs: $$$O(2^\mathbf{K} \times \mathbf{N})$$$
Time complexity:
- Build DSUs and component clubs set (number of distinct clubs): $$$O(2^\mathbf{K} \times (\mathbf{N} + \mathbf{M}))$$$
- Per query: $$$O(2^\mathbf{K})$$$ for checking all DSUs and number of distinct clubs in the corresponding connected component.
- Overall: $$$O(2^\mathbf{K} \times (\mathbf{N} + \mathbf{M}) + \mathbf{Q} \times 2^\mathbf{K}) = O(2^\mathbf{K} \times (\mathbf{N} + \mathbf{M} + \mathbf{Q}))$$$
Test Set 2 and Test Set 3
We can improve our solution by reducing the club combinations to check: we just need to check the original graph $$$G$$$ and all $$$G'$$$ built by removing edges with one club. We can prove this statement by considering all possible cases for query $$$\mathbf{P_j}$$$ and $$$\mathbf{C_j}$$$:
Let $$$\text{Clubs}(G, \mathbf{P_j}, \mathbf{C_j})$$$ be the set of distinct clubs in the connected component containing $$$\mathbf{P_j}$$$ and $$$\mathbf{C_j}$$$ in graph $$$G$$$, and $$$|\text{Clubs}(G, \mathbf{P_j}, \mathbf{C_j})|$$$ be the number of distinct clubs:
- If $$$\mathbf{P_j}$$$ and $$$\mathbf{C_j}$$$ are not connected in $$$G$$$, there is no valid path for this query.
- If $$$\text{Clubs}(G, \mathbf{P_j}, \mathbf{C_j})$$$ has an odd number of distinct clubs ($$$|\text{Clubs}(G, \mathbf{P_j}, \mathbf{C_j})| = 2n + 1$$$), there is always a valid path walking on an odd number of distinct clubs.
- Otherwise, if there is a path from $$$\mathbf{P_j}$$$ to $$$\mathbf{C_j}$$$ composed of edges with odd number ($$$2n + 1$$$) of distinct clubs, $$$\mathbf{P_j}$$$ and $$$\mathbf{C_j}$$$ will always be connected after removing edges with those $$$\mathbf{K} - (2n + 1)$$$ clubs not in that path from graph $$$G$$$. Then, let $$$G_{minimal}$$$ be graph after removing those edges, we can find another path with an odd number of clubs by traversing additional connected edges with two extra clubs $$$c_1$$$ and $$$c_2$$$ where $$$c_1, c_2 \notin \text{Clubs}(G_{minimal}, \mathbf{P_j}, \mathbf{C_j})$$$ and $$$c_1, c_2 \in \text{Clubs}(G, \mathbf{P_j}, \mathbf{C_j})$$$. Recursively, we can find a valid path in $$$G'$$$ by removing only one club from $$$\text{Clubs}(G, \mathbf{P_j}, \mathbf{C_j})$$$. It means if there is a valid path, there is always a $$$G'$$$ where $$$|\text{Clubs}(G', \mathbf{P_j}, \mathbf{C_j})|$$$ is odd and built by removing edges of one club.
Therefore, we just need to build the DSUs and connected components clubs sets for the $$$\mathbf{K}+1$$$ graphs that result from removing $$$0$$$ or $$$1$$$ club from the original graph.
Space complexity:
There are $$$\mathbf{K} + 1$$$ $$$G'$$$s, and each graph has at most $$$\mathbf{N}$$$ connected components:
- Disjoint Set Unions(DSUs): $$$O((\mathbf{K} + 1) \times \mathbf{N}) = O(\mathbf{K} \times \mathbf{N})$$$
- Number of distinct clubs in connected components in graphs: $$$O(\mathbf{K} \times \mathbf{N})$$$
Time complexity:
- Build DSUs and component clubs set (number of distinct clubs): $$$O((\mathbf{K} + 1) \times (\mathbf{N} + \mathbf{M})) = O(\mathbf{K} \times (\mathbf{N} + \mathbf{M}))$$$
- Per query: $$$O(\mathbf{K})$$$ for checking all DSUs and number of distinct clubs in the corresponding connected component.
- Overall: $$$O(\mathbf{K} \times (\mathbf{N} + \mathbf{M} + \mathbf{Q}))$$$
Test Set 2 does not require prebuilding and sharing the DSU and clubs sets across queries. Solutions with time complexity $$$O(\mathbf{Q} \times (\mathbf{K} \times (\mathbf{N} + \mathbf{M})))$$$ that build DSUs and clubs sets for each of the query separately are acceptable.
Proof: Path traversing all edges in the connect component always exists
Suppose there is a path from $$$v_1$$$ to $$$v_n$$$ where $$$p=(v_1,v_2,\dots,v_{n-1}, v_n)$$$, and let $$$\text{Nodes}(p) = \{v_1, v_2, \dots, v_n\}$$$ to be the set of nodes visited at least once in path $$$p$$$:
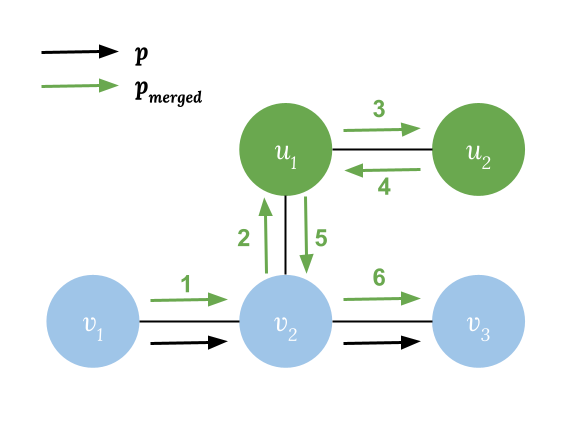
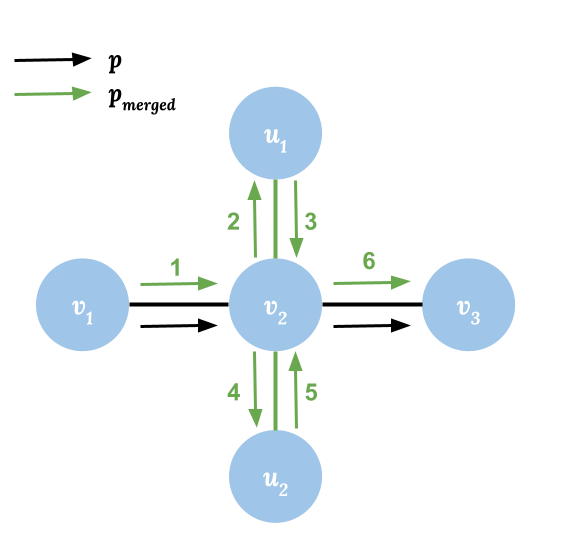
- Node Reachability: For any node $$$v_i \in \text{Nodes}(p)$$$, if there is a node $$$u_m$$$ and a path from $$$v_i$$$ to $$$u_m$$$ where $$$p'=(v_i, u_1, u_2, \dots, u_m)$$$ in the graph, there is always a path $$$p_{merged}$$$ from $$$v_1$$$ to $$$v_n$$$ where $$$\text{Nodes}(p_{merged}) = \text{Nodes}(p) \cup \text{Nodes}(p') \supseteq \text{Nodes}(p) \cup \{u_m\}$$$. A valid path would be $$$p_{merged}=(v_1, \dots,v_i, u_1,\dots, u_{m-1}, u_m, u_{m-1}, \dots, u_1, v_i, v_{i+1}, \dots, v_n)$$$. Notice that we can visit same node or edge multiple times.
- Edge Reachability: For any node $$$v_i \in \text{Nodes}(p)$$$, and for edges $$$(v_i, u_1), (v_i, u_2), \dots, (v_i, u_m)$$$ directly connect to $$$v_i$$$, there always exists a path $$$p'_{merged}$$$ from $$$v_1$$$ to $$$v_n$$$ which traverses all these edges at least once. A valid path would be $$$p'_{merged}=(v_1, \dots,v_i, u_1, v_i, u_2, \dots, v_i, u_m, v_i, v_{i+1}, \dots, v_n)$$$.
- From (1), we can derive that if nodes $$$\mathbf{P}$$$ and $$$\mathbf{C}$$$ are connected, there exist a path from $$$\mathbf{P}$$$ to $$$\mathbf{C}$$$ which visits all reachable nodes from $$$\mathbf{P}$$$ at least once, which are all nodes in the connected component.
- From (2) and (3), we can derive that if nodes $$$\mathbf{P}$$$ and $$$\mathbf{C}$$$ are connected, there exists a path which traverses all the edges in the connected component at least once.
Analysis — E. Game Sort: Part 2
Let $$$N$$$ be the length of $$$\mathbf{S}$$$.
Test Set 1
In Test Set 1, we have either $$$\mathbf{P}=2$$$ or $$$\mathbf{P}=3$$$. We can solve each of those cases separately:
- If $$$\mathbf{P} = 2$$$, there are exactly $$$N-1$$$ possible places to split $$$\mathbf{S}$$$ into two parts. We can try them all, and for each one, check whether Badari can win by using a solution to problem Game Sort: Part 1. Then we know that Amir wins if any of those $$$N-1$$$ places results in a situation where Badari cannot win.
- If $$$\mathbf{P} = 3$$$, there are exactly $$$\frac{(N-1)(N-2)}{2}$$$ possible ways to separate: as before, there are $$$N-1$$$ possible places to split, and we must now choose two of those in order to separate $$$\mathbf{S}$$$ into three parts. Just like before, one option is to try all such pairs, and for each one, check whether Badari can win.
Such an algorithm has a time complexity $$$O(N^3 \lg N)$$$ or perhaps $$$O(N^3)$$$ depending on implementation details, so it is enough to pass Test Set 1.
Test Set 2
First of all, we should notice that, whenever $$$\mathbf{P} = N$$$, Amir has no choice and $$$\mathbf{S}$$$ has to be separated into its $$$N$$$ individual letters. Furthermore, for each single-letter part Badari has no choice of rearrangement. Thus, Badari wins in this case if and only if the letters of $$$\mathbf{S}$$$ are already sorted in non-decreasing order.
This is a special case to check separately, as many of the properties that we will use later to solve Test Set 2 are false if $$$\mathbf{P} = N$$$. From now on, we assume $$$\mathbf{P} \lt N$$$.
We can solve the case $$$\mathbf{P} = 2$$$ as in Test Set 1, trying all $$$N-1$$$ possible ways to split $$$\mathbf{S}$$$. To avoid doing so in quadratic time, we can keep two arrays with a count of each character per part. Then, when moving from position $$$i$$$ to $$$i+1$$$, we only need to increment one count and decrement the other, and use the check from the solution for Game Sort: Part 1. We thus get an $$$O(N)$$$ solution for $$$\mathbf{P}=2$$$.
Finally, the only remaining case is $$$3 \leq \mathbf{P} \lt N$$$. Having at least three parts allows Amir to win lots of strings easily. For instance, for any string which does not start with its alphabetically smallest character (let us call it $$$c$$$), Amir can win by simply splitting the first occurrence of $$$c$$$ as a single-letter part.
Similarly, if the alphabetically smallest character $$$c$$$ appears anywhere on the string that is not the first or second character, it is possible to win by splitting that occurrence of $$$c$$$ as a single-letter part, while leaving the first and second characters of the string unsplit (it is possible because $$$\mathbf{P} \lt N$$$).
In the remaining case for $$$\mathbf{P} \geq 3$$$, $$$\mathbf{S}$$$ has the following property:
- $$$c$$$ appears in $$$\mathbf{S}$$$ either exactly once as the first character of $$$\mathbf{S}$$$, or exactly twice as the first two characters of $$$\mathbf{S}$$$.
Let us call a string having that property a bad string, and any string without the property good. The only remaining case to solve is for bad strings and $$$\mathbf{P} \geq 3$$$.
We can assume that Badari plays optimally, and that she follows the optimal strategy explained in the solution of Game Sort: Part 1. That strategy implies that, for a bad string, no matter how we separate $$$\mathbf{S}$$$ into parts, after Badari's rearrangement, the first part is lexicographically lower than or equal to all the other parts. This is because the first part will either contain a single $$$c$$$, or every occurrence of $$$c$$$.
Thus, to split a bad string into $$$\mathbf{P}$$$ parts, we must choose the length $$$l$$$ of the first part, and then separate the remaining $$$N-l$$$ characters into $$$\mathbf{P}-1$$$ parts. Note that the first part will be in sorted order, and by the property of bad strings, it will be the lexicographically smallest part and will not impose restrictions on the rearrangement of the second part. So Amir wins such a split if and only if he wins the split of the last $$$N-l$$$ characters into $$$\mathbf{P}-1$$$ parts.
Using all these ideas, we can recursively compute, for each suffix of the initial string $$$\mathbf{S}$$$ and each $$$k$$$ with $$$2 \leq k \leq \mathbf{P}$$$, who wins when the game is played for that suffix as initial string and $$$k$$$ as the number of parts.
Note that, with this approach, computing who wins for each suffix when splitting into $$$k=2$$$ parts must be done independently as a base case. It is possible to compute all such values efficiently, but it involves even more case analysis and careful implementation, so we will leave it as an exercise for the reader. Such an approach would lead to an overall $$$O(N \times \mathbf{P})$$$ time solution, which should pass if implemented carefully.
Although the main idea of this solution is relatively direct, the implementation has many special cases and details, and is tricky to code quickly and correctly. This approach can be implemented more efficiently and in a simpler way, by not storing all of the $$$N \times \mathbf{P}$$$ subproblems. Instead, we can store, for each $$$k$$$ between $$$2$$$ and $$$\mathbf{P}$$$, the index of the shortest suffix that Amir wins when splitting that suffix into $$$k$$$ parts. In a sense, the shortest suffix that works is the only relevant working suffix, because when choosing the length $$$l$$$ of a first part to cut, if any winning suffix is available, then the shortest one is. This key observation also avoids having to code the general problem of identifying all winning suffixes for $$$k=2$$$, since we only need to find the shortest such suffix now, which is quite a simpler problem that we will also leave as an exercise. (Hint: focus only on which characters are lower, equal to, or higher than the very last character of the input string.) With this, we get an $$$O(N)$$$ solution.
Another approach
There is another approach which is quite simpler to code, but maybe harder to find and prove correct. We will sketch the algorithm and leave the proof of correctness as an exercise for the reader.
We solve cases $$$\mathbf{P}=N$$$ and $$$\mathbf{P}=2$$$ exactly as before. Then we observe that, for $$$\mathbf{P} \geq 4$$$, Amir has even more favorable strings:
- If $$$\mathbf{S}$$$ is not sorted, then Amir wins by taking the first consecutive pair of letters in $$$\mathbf{S}$$$ that are out of order, and separating them both into single-letter parts.
- If $$$\mathbf{S}$$$ contains three consecutive identical letters, then Amir wins by splitting so that the first two occurrences form a part of length $$$2$$$, and the third consecutive occurrence forms a single-letter part.
- If neither (1) nor (2) hold, then it is easy to see that Amir cannot win.
Only the hardest case where $$$\mathbf{P}=3$$$ remains. Suppose that Amir splits $$$\mathbf{S}$$$ into three parts, say $$$A,B,C$$$ (so $$$\mathbf{S}=ABC$$$). It is clear that, if partitioning string $$$AB$$$ into $$$A,B$$$ is a win for Amir with $$$\mathbf{P}=2$$$ and input string $$$AB$$$, then $$$A,B,C$$$ works for $$$\mathbf{P}=3$$$ and input string $$$\mathbf{S}=ABC$$$. Similarly, if partitioning $$$BC$$$ into $$$B,C$$$ is a win for Amir for $$$\mathbf{P}=2$$$ and input string $$$BC$$$, then also $$$A,B,C$$$ for $$$\mathbf{P}=3$$$ and input $$$\mathbf{S}=ABC$$$.
The surprising result is that, for any string $$$\mathbf{S}$$$, Amir wins if and only
if one of these two cases occur. This is not obvious: There are examples of
partitions $$$A,B,C$$$ that work, but neither $$$A,B$$$ nor $$$B,C$$$ work;
e.g. XY,AZ,XY for input string XYAZXY. However, in
any such case there will be some other partition that works and has this
property, e.g. XY,A,ZXY for input string XYAZXY, as
XY,A works.
Finally, we only need to check if Amir wins any prefix or suffix of $$$\mathbf{S}$$$ with $$$\mathbf{P}=2$$$. Note that this is actually simpler than computing for every suffix and prefix whether Amir wins with $$$\mathbf{P}=2$$$, and can be done by a slight modification of the full solution to the $$$\mathbf{P}=2$$$ case, which we leave as an exercise.