Google Code Jam Archive — Farewell Round B problems
Overview
Gardel used to sing in the famous "Volver" tango song that 20 years is nothing. It certainly does not feel that way for Coding Competitions. With these farewell rounds, a marvelous maze reaches the exit. Hopefully it was as entertaining and educational for you to solve it as it was for us to put it together.
For today's rounds we went with a Code Jam-finals setup for everyone: 4 hours, 5 problems, lots of problems with the same score. In this way, each contestant can trace their own path, as you have done throughout our history before.
Round A had all problems at newcomer level with all test sets visible, to align with a Coding Practice With Kick Start round. Round B was also fully visible, but had increasingly harder problems and required some techniques, like a Kick Start round. Rounds C and D had hidden test sets, ad-hoc ideas, some more advanced algorithms and data structures, and included an interactive problem, to cover the full spectrum of the Coding Competitions experience.
We also had appearances from Cody-Jamal, pancakes, names of famous computer scientists, a multi-part problem, I/O problem names, faux references to computer-world terms, and quite a few throwbacks to old problems.
Problems from these rounds will be up for practice until June 1st so you can get a chance at all of them before sign-in is disabled on the site.
Thanks to those of you who could join us today, and to everyone who was around in our long history. It has been amazing. Last words are always hard, so we can borrow from Gardel the ending of "Volver" that does fit the moment: "I save hidden a humble hope, which is all the fortune of my heart."
8 6245 876543 374300 350000 378385 21342 46727 112358
1 2 NA D
1 2 6 *Oo*.d *cNCE*
Cast
Colliding Encoding: Written by Shashwat Badoni. Prepared by Jared Gillespie and Pablo Heiber.
Rainbow Sort: Written by Dmitry Brizhinev. Prepared by Shubham Avasthi.
Illumination Optimization: Written by Melisa Halsband. Prepared by Shaohui Qian.
Untie: Written and prepared by Pablo Heiber.
ASCII Art: Written by Bartosz Kostka. Prepared by Anveshi Shukla.
Collecting Pancakes: Written by Anurag Singh. Prepared by Pranav Gavvaji.
Spacious Sets: Written by Bartosz Kostka. Prepared by Deepanshu Aggarwal.
Intruder Outsmarting: Written by Muskan Garg. Prepared by Pablo Heiber and Saki Okubo.
Railroad Maintenance: Written by Emerson Lucena. Prepared by Mahmoud Ezzat.
Railroad Management: Written by Bintao Sun. Prepared by Yu-Che Cheng.
Game Sort: Part 1: Written by Luis Santiago Re and Pablo Heiber. Prepared by Isaac Arvestad and Luis Santiago Re.
Immunization Operation: Written by Chu-ling Ko. Prepared by Shaohui Qian.
Evolutionary Algorithms: Written by Anurag Singh. Prepared by Vinay Khilwani.
The Decades of Coding Competitions: Written by Ashish Gupta. Prepared by Bakuri Tsutskhashvili.
Game Sort: Part 2: Written by Luis Santiago Re. Prepared by Agustín Gutiérrez and Luis Santiago Re.
Indispensable Overpass: Written by Hsin-Yi Wang. Prepared by Shaohui Qian.
Ring-Preserving Networks: Written by Han-sheng Liu. Prepared by Pablo Heiber.
Hey Google, Drive!: Written by Archie Pusaka. Prepared by Chun-nien Chan.
Old Gold: Written and prepared by Ikumi Hide.
Genetic Sequences: Written and prepared by Max Ward.
Solutions and other problem preparation and review by Abhay Pratap Singh, Abhilash Tayade, Abhishek Saini, Aditya Mishra, Advitiya Brijesh, Agustín Gutiérrez, Akshay Mohan, Alan Lou, Alekh Gupta, Alice Kim, Alicja Kluczek, Alikhan Okas, Aman Singh, Andrey Kuznetsov, Anthony, Antonio Mendez, Anuj Asher, Anveshi Shukla, Arghya Pal, Arjun Sanjeev, Arooshi Verma, Artem Iglikov, Ashutosh Bang, Bakuri Tsutskhashvili, Balganym Tulebayeva, Bartosz Kostka, Chu-ling Ko, Chun-nien Chan, Cristhian Bonilha, Deeksha Kaurav, Deepanshu Aggarwal, Dennis Kormalev, Diksha Saxena, Dragos-Paul Vecerdea, Ekanshi Agrawal, Emerson Lucena, Erick Wong, Gagan Kumar, Han-sheng Liu, Harshada Kumbhare, Harshit Agarwala, Hsin-Yi Wang, Ikumi Hide, Indrajit Sinha, Isaac Arvestad, Jared Gillespie, Jasmine Yan, Jayant Sharma, Ji-Gui Zhang, Jin Gyu Lee, John Dethridge, João Medeiros, Junyang Jiang, Katharine Daly, Kevin Tran, Kuilin Wang, Kushagra Srivastava, Lauren Minchin, Lucas Maciel, Luis Santiago Re, Marina Vasilenko, Mary Yang, Max Ward, Mayank Aharwar, Md Mahbubul Hasan, Mo Luo, Mohamed Yosri Ahmed, Mohammad Abu-Amara, Murilo de Lima, Muskan Garg, Nafis Sadique, Nitish Rai, Nurdaulet Akhanov, Olya Kalitova, Ophelia Doan, Osama Fathy, Pablo Heiber, Pawel Zuczek, Raghul Rajasekar, Rahul Goswami, Raymond Kang, Ritesh Kumar, Rohan Garg, Ruiqing Xiang, Sadia Atique, Sakshi Mittal, Salik Mohammad, Samiksha Gupta, Samriddhi Srivastava, Sanyam Garg, Sara Biavaschi, Sarah Young, Sasha Fedorova, Shadman Protik, Shantam Agarwal, Sharmin Mahzabin, Sharvari Gaikwad, Shashwat Badoni, Shu Wang, Shubham Garg, Surya Upadrasta, Swapnil Gupta, Swapnil Mahajan, Tanveer Muttaqueen, Tarun Khullar, Thomas Tan, Timothy Buzzelli, Tushar Jape, Udbhav Chugh, Ulises Mendez Martinez, Umang Goel, Viktoriia Kovalova, Vinay Khilwani, Vishal Som, William Di Luigi, Yang Xiao, Yang Zheng, Yu-Che Cheng, and Zongxin Wu.
Analysis authors:
- Colliding Encoding: Surya Upadrasta.
- Rainbow Sort: Rakesh Theegala.
- Illumination Optimization: Sarah Young.
- Untie: Pablo Heiber.
- ASCII Art: Raghul Rajasekar.
- Collecting Pancakes: Raghul Rajasekar.
- Spacious Sets: Rakesh Theegala.
- Intruder Outsmarting: Ekanshi Agrawal.
- Railroad Maintenance: Cristhian Bonilha.
- Railroad Management: Emerson Lucena.
- Game Sort: Part 1: Mohamed Yosri Ahmed.
- Immunization Operation: Sadia Atique.
- Evolutionary Algorithms: Krists Boitmanis.
- The Decades of Coding Competitions: Chun-nien Chan.
- Game Sort: Part 2: Agustín Gutiérrez.
- Indispensable Overpass: Arooshi Verma.
- Ring-Preserving Networks: Han-sheng Liu.
- Hey Google, Drive!: Chu-ling Ko.
- Old Gold: Evan Dorundo.
- Genetic Sequences: Max Ward.
A. Collecting Pancakes
Problem
Alice and Bob both have a sweet tooth, and they are going to play a game to collect pancakes. There are $$$\mathbf{N}$$$ pancake stacks lined up on the table labeled from $$$1$$$ to $$$\mathbf{N}$$$. The $$$i$$$-th stack has exactly $$$\mathbf{A_i}$$$ pancakes. Alice and Bob are going to collect pancakes by alternating turns claiming full stacks. For the first turn, Alice must choose a stack labeled between $$$\mathbf{L_a}$$$ and $$$\mathbf{R_a}$$$, inclusive, and claim it. Then, Bob must choose a stack labeled between $$$\mathbf{L_b}$$$ and $$$\mathbf{R_b}$$$, inclusive, and different from the one chosen by Alice, and claim it.
In subsequent turns, each of them must choose an unclaimed stack that is adjacent to a stack they claimed themselves before. That is, for Alice to claim stack $$$i$$$ on one of her turns other than the first, she must have claimed either stack $$$i-1$$$ or stack $$$i+1$$$ in one of her previous turns. The same is true for Bob. If at some point there is no valid choice for either player, they skip that turn and claim no stack.
The game ends when every stack is claimed. At that point, Alice collects all pancakes from all stacks she claimed, and Bob collects all pancakes in all stacks he claimed.
Alice wants to get as many pancakes as possible for herself, and Bob wants to get as many pancakes as possible for himself. Can you help Alice find out the maximum number of pancakes she can collect if they both play optimally?
Input
The first line of the input gives the number of test cases, $$$\mathbf{T}$$$. $$$\mathbf{T}$$$ test cases follow. Each test case consists of three lines.
The first line of each test case contains an integer $$$\mathbf{N}$$$, representing the number of pancake stacks.
The second line contains $$$\mathbf{N}$$$ integers $$$\mathbf{A_1}, \mathbf{A_2}, \dots, \mathbf{A_N}$$$, where $$$\mathbf{A_i}$$$ denotes the number of pancakes in stack $$$i$$$.
The third line contains $$$4$$$ integers $$$\mathbf{L_a}$$$, $$$\mathbf{R_a}$$$, $$$\mathbf{L_b}$$$, and $$$\mathbf{R_b}$$$, the inclusive ranges of pancake stack labels Alice and Bob can choose for their first turn, respectively.
Output
For each test case, output one line containing
Case #$$$x$$$: $$$y$$$, where $$$x$$$ is the test case number
(starting from 1) and $$$y$$$ is the maximum number of pancakes Alice can
collect after playing the game optimally.
Limits
Time limit: 30 seconds.
Memory limit: 2 GB.
$$$1 \le \mathbf{T} \le 100$$$.
$$$1 \le \mathbf{A_i} \le 10^9$$$, for all $$$i$$$.
$$$1 \le \mathbf{L_a} \le \mathbf{R_a} \le \mathbf{N}$$$
$$$1 \le \mathbf{L_b} \le \mathbf{R_b} \le \mathbf{N}$$$
It is not the case that $$$\mathbf{L_a} \le \mathbf{L_b} = \mathbf{R_b} \le \mathbf{R_a}$$$. (Bob is guaranteed to be
able to pick a stack for his first turn regardless of Alice's choice.)
Test Set 1 (Visible Verdict)
$$$2 \le \mathbf{N} \le 100$$$.
Test Set 2 (Visible Verdict)
$$$2 \le \mathbf{N} \le 10^5$$$.
Sample
3 5 30 50 40 20 10 1 2 4 5 5 20 20 80 10 10 1 4 2 5 4 90 10 10 10 1 4 1 4
Case #1: 120 Case #2: 100 Case #3: 90
In Sample Case #1, there are $$$5$$$ pancake stacks with $$$30, 50, 40, 20, 10$$$ pancakes in them. Alice can choose the first or second stack at the beginning of the game, and Bob can choose the fourth or fifth stack to begin with. One way in which they both play optimally is:
- At the beginning, Alice claims stack $$$2$$$, then Bob claims stack $$$4$$$.
- Alice claims stack $$$3$$$ in her second turn, then Bob claims stack $$$5$$$ in his second turn.
- Alice claims stack $$$1$$$ in her third turn, then the game ends because all stacks have been claimed.
At the end of the game, Alice claimed stacks $$$1, 2$$$, and $$$3$$$ and Bob claimed stacks $$$4$$$ and $$$5$$$. The number of pancakes Alice collects is $$$30+50+40=120$$$.
In Sample Case #2, one way of optimal play is:
- At the beginning, Alice claims stack $$$3$$$, then Bob claims stack $$$2$$$.
- Alice claims stack $$$4$$$ in her second turn, then Bob claims stack $$$1$$$ in his second turn.
- Alice claims stack $$$5$$$ in her third turn, then the game ends because all stacks have been claimed.
The number of pancakes Alice collects is $$$80+10+10=100$$$.
In Sample Case #3, both can claim any stack in their first turn. Since stack $$$1$$$ is more valuable than everything else combined, Alice claims it before Bob does. Then, Bob can claim stack $$$2$$$, making Alice have to skip all her subsequent turns. Alice still finishes with $$$90$$$ pancakes and Bob with just $$$30$$$.
B. Intruder Outsmarting
Problem
Amiria is a cautious internet user, and as such, she is setting up two-factor authentication for her accounts. She is using a special type of security key as an extra precaution to outsmart any intruders that may want to take it. Amiria's security key requires a code to activate. To enter the code, one must place it on wheels with numbers, similar to code padlocks.
Amiria's security key has a sequence of $$$\mathbf{W}$$$ wheels. Each wheel has the numbers $$$1$$$ through $$$\mathbf{N}$$$ printed in order. When rotating the wheel, the user can move the currently shown integer either to the next or the previous integer. Numbers on the wheel wrap around. This means the number after $$$\mathbf{N}$$$ is $$$1$$$ and the number before $$$1$$$ is $$$\mathbf{N}$$$.
There is no hidden password. To activate the security key Amiria needs to move the wheels such that the sequence of numbers shown is palindromic. That is, the sequence of numbers is the same when read from left to right and from right to left. To slow down intruders, Amiria rigged the security key such that the wheels only rotate in increments of $$$\mathbf{D}$$$. That is, on a move, a wheel that is currently showing $$$x$$$ can be made to show $$$x - \mathbf{D}$$$ or $$$x + \mathbf{D}$$$, applying the proper wraparound. That is, if $$$x - \mathbf{D} \lt 1$$$ the actual number shown after the operation is $$$x - \mathbf{D} + \mathbf{N}$$$, and if $$$x + \mathbf{D} \gt \mathbf{N}$$$ the actual number shown is $$$x + \mathbf{D} - \mathbf{N}$$$.
Amiria wants to check how much this system would slow down an intruder trying to use her security key. Given the number of wheels and the number currently shown on each wheel, find the minimum number of operations needed to make the sequence of shown numbers palindromic, or report that it is impossible to do so.
Input
The first line of the input gives the number of test cases, $$$\mathbf{T}$$$. $$$\mathbf{T}$$$ test cases follow. Each test case consists of two lines. The first line of a test case contains $$$3$$$ integers $$$\mathbf{W}$$$, $$$\mathbf{N}$$$, and $$$\mathbf{D}$$$: the number of wheels in Amiria's security key, the number of integers shown in each of those wheels, and the fixed increment that Amiria rigged for every wheel. The second line of a test case contains $$$\mathbf{W}$$$ integers $$$\mathbf{X_1}, \mathbf{X_2}, \dots, \mathbf{X_W}$$$, where $$$\mathbf{X_i}$$$ is the number currently shown in the $$$i$$$-th wheel from left to right.
Output
For each test case, output one line containing Case #$$$x$$$: $$$y$$$,
where $$$x$$$ is the test case number (starting from 1) and $$$y$$$ is the minimum number of
operations needed to make the sequence of shown numbers palindromic. If there is no way to
make the sequence of shown numbers palindromic through the allowed operations, $$$y$$$ must
be IMPOSSIBLE instead.
Limits
Time limit: 5 seconds.
Memory limit: 2 GB.
$$$1 \le \mathbf{T} \le 100$$$.
$$$1 \le \mathbf{D} \le \mathbf{N} - 1$$$.
$$$1 \le \mathbf{X_i} \le \mathbf{N}$$$, for all $$$i$$$.
Test Set 1 (Visible Verdict)
$$$2 \le \mathbf{W} \le 5$$$.
$$$2 \le \mathbf{N} \le 5$$$.
Test Set 2 (Visible Verdict)
$$$2 \le \mathbf{W} \le 1000$$$.
$$$2 \le \mathbf{N} \le 10^9$$$.
Sample
3 5 5 4 1 4 5 5 4 3 4 2 3 4 3 2 4 2 1 4
Case #1: 3 Case #2: 0 Case #3: IMPOSSIBLE
In Sample Case #1, the sequence can be made $$$5 ~ 4 ~ 5 ~ 4 ~ 5$$$, which is palindromic, with $$$3$$$ operations by using one addition operation on the first and fourth wheels, and one subtraction operation on the fifth wheel. There is no way to make the sequence palindromic with fewer moves.
In Sample Case #2 the sequence is already palindromic, so we do not need any operations.
In Sample Case #3, both numbers would need to be equal for the sequence to be palindromic. Since wheel values can only move by $$$2$$$ and both current numbers have different parity, that cannot be done.
C. Spacious Sets
Problem
Ada and John are best friends. Since they are getting bored, Ada asks John to solve a puzzle for her.
A set $$$S$$$ is considered spacious if the absolute difference between each pair of distinct elements of $$$S$$$ is at least $$$\mathbf{K}$$$, that is, $$$|x - y| \ge \mathbf{K}$$$ for all $$$x, y \in S$$$, with $$$x \ne y$$$.
Ada has a list of distinct integers $$$\mathbf{A}$$$ of size $$$\mathbf{N}$$$, and an integer $$$\mathbf{K}$$$. For each $$$\mathbf{A_i}$$$, she asks John to find the maximum size of a set $$$S_i$$$ made of elements from $$$\mathbf{A}$$$, such that $$$S_i$$$ contains $$$\mathbf{A_i}$$$ and is spacious.
Note: The sets $$$S_i$$$ do not need to be made of consecutive elements from the list.
Input
The first line of the input gives the number of test cases, $$$\mathbf{T}$$$. $$$\mathbf{T}$$$ test cases follow.
The first line of each test case contains two integers $$$\mathbf{N}$$$ and $$$\mathbf{K}$$$.
The next line contains $$$\mathbf{N}$$$ integers $$$\mathbf{A_1} \mathbf{A_2} \dots \mathbf{A_N}$$$.
Output
For each test case, output one line containing
Case #$$$x$$$: $$$y_1 ~ y_2 \dots ~ y_\mathbf{N}$$$,
where $$$x$$$ is the test case number (starting from 1) and $$$y_i$$$
is the maximum size of a spacious set of elements from $$$\mathbf{A}$$$ that contains $$$\mathbf{A_i}$$$.
Limits
Time limit: 20 seconds.
Memory limit: 2 GB.
$$$1 \le \mathbf{T} \le 100$$$.
$$$-10^9 \le \mathbf{A_i} \le 10^9$$$, for all $$$i$$$.
$$$\mathbf{A_i} \ne \mathbf{A_j}$$$, for all $$$i \ne j$$$.
Test Set 1 (Visible Verdict)
$$$1 \le \mathbf{N} \le 10$$$.
$$$1 \le \mathbf{K} \le 100$$$.
Test Set 2 (Visible Verdict)
$$$1 \le \mathbf{K} \le 10^9$$$.
For at most 15 cases:
$$$1 \le \mathbf{N} \le 10^5$$$.
For the remaining cases:
$$$1 \le \mathbf{N} \le 10^3$$$.
Sample
2 3 2 1 2 3 6 4 2 7 11 19 5 3
Case #1: 2 1 2 Case #2: 4 4 4 4 3 4
In Sample Case #1, a spacious set cannot contain $$$1$$$ and $$$2$$$, nor it can contain $$$2$$$ and $$$3$$$. That implies that $$$S_2 = \{2\}$$$ and using $$$S_1 = S_3 = \{1,3\}$$$ makes them of maximum size.
In Sample Case #2, possible sets of maximum size are:
- $$$S_1 = S_2 = S_3 = S_4 = \{2,7,11,19\}$$$,
- $$$S_5 = \{11,19,5\}$$$, and
- $$$S_6 = \{7,11,19,3\}$$$.
D. Railroad Maintenance
Problem
You are in charge of the maintenance of a railroad network. The network consists of $$$\mathbf{N}$$$ stations and $$$\mathbf{L}$$$ train lines. Each train line serves a fixed list of stations bidirectionally (trains turn around in the first and last stations of the list). Transfers from one line to another in a station are possible, which means a trip in the network from station $$$a$$$ to station $$$b$$$ is possible if there is a list of train lines such that the first one serves station $$$a$$$, the last one serves station $$$b$$$, and for any consecutive pair of train lines in the list there is at least one station that they both serve.
The easiest way to do maintenance is to shut down entire lines, one at a time. However, some train lines may be essential. A train line is essential if removing it would make at least one trip between a pair of stations not possible.
Given the list of existing train lines, calculate how many of them are essential.
Input
The first line of the input gives the number of test cases, $$$\mathbf{T}$$$. $$$\mathbf{T}$$$ test cases follow. Each test case starts with a line containing two integers $$$\mathbf{N}$$$ and $$$\mathbf{L}$$$: the number of stations and train lines in the network. Then, $$$\mathbf{L}$$$ groups of 2 lines follow. The first line of the $$$i$$$-th group contains a single integer $$$\mathbf{K_i}$$$ the number of stations served by the $$$i$$$-th train line. The second line of the $$$i$$$-th group contains $$$\mathbf{K_i}$$$ integers $$$\mathbf{S_{i,1}}, \mathbf{S_{i,2}}, \dots, \mathbf{S_{i,{K_i}}}$$$ representing the stations served by the $$$i$$$-th train line.
Output
For each test case, output one line containing Case #$$$x$$$: $$$y$$$,
where $$$x$$$ is the test case number (starting from 1) and $$$y$$$ is the number of train
lines that are essential.
Limits
Time limit: 40 seconds.
Memory limit: 2 GB.
$$$1 \le \mathbf{T} \le 100$$$.
$$$2 \le \mathbf{K_i} \le \mathbf{N}$$$ for all $$$i$$$.
$$$1 \le \mathbf{S_{i,j}} \le \mathbf{N}$$$, for all $$$i, j$$$.
$$$\mathbf{S_{i,j}} \ne \mathbf{S_{i,j'}}$$$, for all $$$i, j, j'$$$ such that $$$j \ne j'$$$ (Each train
line serves a station at most once).
The trip between all pairs of stations is possible as per the definition above
when no train line is shut down.
Test Set 1 (Visible Verdict)
$$$2 \le \mathbf{N} \le 100$$$.
$$$1 \le \mathbf{L} \le 100$$$.
$$$\mathbf{K_1} + \mathbf{K_2} + \cdots + \mathbf{K_L} \le 200$$$.
Test Set 2 (Visible Verdict)
$$$2 \le \mathbf{N} \le 10^5$$$.
$$$1 \le \mathbf{L} \le 10^5$$$.
$$$\mathbf{K_1} + \mathbf{K_2} + \cdots + \mathbf{K_L} \le 2 \times 10^5$$$.
Sample
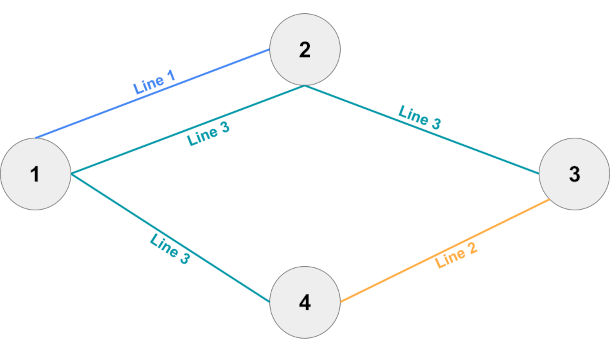
4 4 3 3 1 2 3 2 1 4 3 4 1 3 4 4 2 1 2 2 3 4 2 3 2 2 4 1 4 3 2 1 2 2 3 4 2 3 2 4 3 2 1 2 2 3 4 4 4 1 2 3
Case #1: 1 Case #2: 0 Case #3: 3 Case #4: 1
In Sample Case #1, the first train line is essential because it is the only one serving station $$$2$$$. Since shutting any other line down would not make travel between at least one pair of stations impossible, they are not essential.
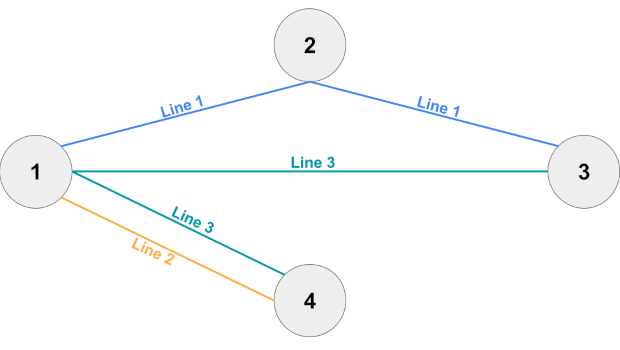
In Sample Case #2, no line is essential.
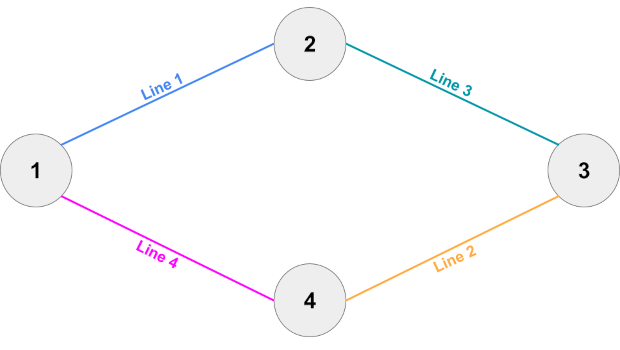
Sample Case #3 is similar to Sample Case #2, but missing the last train line. That makes all remaining train lines essential.
In Sample Case #4, the last train line is essential as there is no way to go from station $$$1$$$ to station $$$4$$$ without it. As in Sample Case #1, since this train line already connects every station, no other line is essential.
E. Railroad Management
Problem
You are in charge of the management of a railroad network. The network consists of $$$\mathbf{N}$$$ stations. Each station $$$i$$$ needs to ship goods to exactly one other station $$$\mathbf{D_i}$$$. Station $$$i$$$ will send exactly one shipment, in a train with exactly $$$\mathbf{C_i}$$$ railroad cars.
You get all the shipment information well in advance, so you plan on saving on railroad cars by reusing them. If station $$$i$$$ sends $$$n$$$ railroad cars to station $$$\mathbf{D_i}$$$, then $$$\mathbf{D_i}$$$ can add those railroad cars to its supply to use for its own shipment if it did not already happen.
Formally, you must give an initial supply of railroad cars to each station (some stations may get $$$0$$$) and provide an order for the shipments so that, by the time station $$$i$$$ must ship, the number of railroad cars between its initial supply and any previous shipments that arrived at $$$i$$$ must be at least the number it needs for its own shipment $$$\mathbf{C_i}$$$. You cannot send more than $$$\mathbf{C_i}$$$ cars in a shipment out of station $$$i$$$, even if the station has more than $$$\mathbf{C_i}$$$ available.
For example, suppose that station $$$1$$$ sends a train carrying exactly $$$3$$$ railroad cars to station $$$4$$$. Now, if station $$$4$$$ needs $$$2$$$ cars, it could reuse $$$2$$$ of the cars it received from station $$$1$$$. And if station $$$4$$$ needs to send $$$5$$$ cars, it can reuse all $$$3$$$ cars received from station $$$1$$$ and add $$$2$$$ of its own supply. Note that when station $$$4$$$ needs to send $$$2$$$ cars, it cannot send all $$$3$$$ it received from station $$$1$$$.
Given the shipment information, what is the minimum number of railroad cars you need to distribute for the stations' initial supplies, such that you can do all shipments in some order?
Input
The first line of the input gives the number of test cases, $$$\mathbf{T}$$$. $$$\mathbf{T}$$$ test cases follow. Each test case consists of $$$3$$$ lines. The first line contains a single integer $$$\mathbf{N}$$$, the number of stations in the network. The second line contains $$$\mathbf{N}$$$ integers $$$\mathbf{D_1}, \mathbf{D_2}, \dots, \mathbf{D_N}$$$ and the third and last line contains $$$\mathbf{N}$$$ integers $$$\mathbf{C_1}, \mathbf{C_2}, \dots, \mathbf{C_N}$$$. These represent that station $$$i$$$ must send a train of exactly $$$\mathbf{C_i}$$$ railroad cars to station $$$\mathbf{D_i}$$$.
Output
For each test case, output one line containing Case #$$$x$$$: $$$y$$$,
where $$$x$$$ is the test case number (starting from 1) and $$$y$$$ is the minimum number of
railroad cars you need to distribute among the stations so that all shipments can be performed.
Limits
Time limit: 40 seconds.
Memory limit: 2 GB.
$$$1 \le \mathbf{T} \le 100$$$.
$$$1 \le \mathbf{D_i} \le \mathbf{N}$$$, for all $$$i$$$.
$$$\mathbf{D_i} \ne i$$$, for all $$$i$$$.
$$$1 \le \mathbf{C_i} \le 10^9$$$, for all $$$i$$$.
Test Set 1 (Visible Verdict)
$$$2 \le \mathbf{N} \le 8$$$.
Test Set 2 (Visible Verdict)
$$$2 \le \mathbf{N} \le 10^5$$$.
Sample
3 4 2 3 4 3 4 3 2 1 4 2 3 4 1 1 3 1 3 7 3 5 2 5 3 7 6 3 4 6 3 5 1 2
Case #1: 4 Case #2: 5 Case #3: 10
In Sample Case #1 one optimal way is to do the shipments in increasing order of departure station. That requires sending $$$4$$$ cars to station $$$1$$$. But after that, each station receives enough cars for its shipment, for a total of $$$4$$$ overall. Since no cars arrive at station $$$1$$$, it definitely needs the initial $$$4$$$, so this is also the minimum possible.
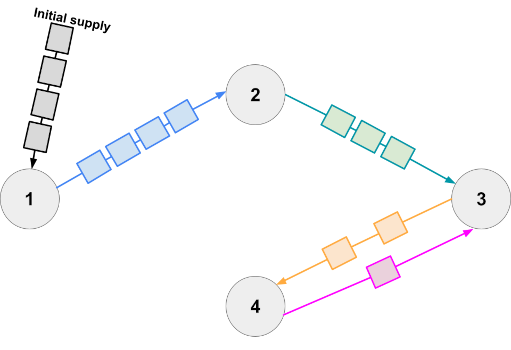
In Sample Case #2 one minimal way is to supply $$$1$$$ car to station $$$3$$$ and $$$2$$$ cars each to stations and $$$2$$$ and $$$4$$$, for a total of $$$5$$$. Then, we can start with the shipment $$$3 \to 4$$$ which gets one additional car to station $$$4$$$. This makes station $$$4$$$ have the $$$3$$$ cars it needs to ship $$$4 \to 1$$$. Station $$$1$$$ now has $$$3$$$ cars which is enough to do $$$1 \to 2$$$ with a single car, taking the total at station $$$2$$$ to $$$3$$$ cars, enough to do the final shipment $$$2 \to 3$$$. Notice that the shipment $$$1 \to 2$$$ cannot bring extra cars to station $$$2$$$, even though there are cars available and it would be helpful to do so. There are other ways to do all shipments with $$$5$$$ initial cars, but no way to do it with less.
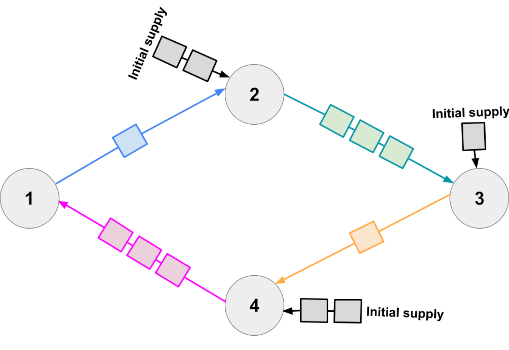
In Sample Case #3, one optimal starting number of cars is $$$3$$$ cars at stations $$$1$$$ and $$$4$$$ and $$$2$$$ cars at stations $$$5$$$ and $$$7$$$.
Analysis — A. Collecting Pancakes
Let $$$X_a$$$ and $$$X_b$$$ be the indices of the stacks chosen by Alice and Bob respectively. As per the definition in the question, $$$\mathbf{L_a} \le X_a \le \mathbf{R_a}$$$ and $$$\mathbf{L_b} \le X_b \le \mathbf{R_b} $$$.
The key observation to note here is that, while collecting pancakes, Alice and Bob cannot cross over any stack claimed by the other person at any point. Specifically, if $$$X_a \gt X_b$$$, then Bob cannot collect pancakes from any stacks with indices $$$\gt X_a$$$ and vice versa. This leads to the observation that only the pancake stacks in between Alice and Bob's initial choices are being contested for. All pancake stacks are guaranteed to be claimed by the person that started closer to them. Thus, the optimal strategy for either player would be to first start claiming stacks between $$$X_a$$$ and $$$X_b$$$, then start claiming the other stacks, leaving each player with a contiguous range of stacks which is either a prefix or suffix of the overall line of stacks.
Test Set 1
The constraint $$$\mathbf{N} \le 100$$$ allows a naive solution based on the observations above, which is to try out all valid combinations of $$$X_a$$$ and $$$X_b$$$, and simulate the optimal strategy described.
The optimal strategy would be for Alice and Bob to first start moving towards each other's initial positions, claiming stacks along the way. Once all stacks between $$$X_a$$$ and $$$X_b$$$ have been claimed, each player would claim all the stacks closer to them. The final answer would thus be the maximum number of pancakes collected by Alice in any such simulation.
Since there are $$$O(\mathbf{N}^2)$$$ combinations of $$$X_a$$$ and $$$X_b$$$, and simulating the strategy for any such $$$X_a$$$ and $$$X_b$$$ would take at most $$$\mathbf{N}$$$ steps, the overall time complexity of this approach is $$$O(\mathbf{N}^3)$$$.
Test Set 2
Another observation to be made is that once $$$X_a$$$ is chosen, Bob will always try to set $$$X_b$$$ as close to $$$X_a$$$ as possible, to minimize the number of additional pancakes Alice can get by choosing stacks between $$$X_a$$$ and $$$X_b$$$. This leads to three scenarios:
- $$$X_a \le \mathbf{L_b}$$$: In this case, Bob can only choose $$$X_b$$$ to the right of $$$X_a$$$. This will result in Bob choosing $$$X_b = \mathbf{L_b}$$$ (or $$$X_b = \mathbf{L_b} + 1$$$ if $$$X_a = \mathbf{L_b} $$$). Then, once Alice and Bob start claiming stacks between $$$X_a$$$ and $$$X_b$$$, Alice will end up claiming all the stacks from $$$X_a$$$ to $$$\lfloor \frac{X_a + X_b}{2} \rfloor$$$. Finally, Alice would claim the stacks from $$$1$$$ to $$$X_a - 1$$$, leaving her with all the stacks from $$$1$$$ to $$$\lfloor \frac{X_a + X_b}{2} \rfloor$$$.
- $$$X_a \ge \mathbf{R_b}$$$: Mirror image of Case 1.
- $$$\mathbf{L_b} \lt X_a \lt \mathbf{R_b}$$$: Here, Bob can choose a position immediately adjacent to $$$X_a$$$ (either $$$X_a - 1$$$ or $$$X_a + 1$$$). This leaves no stacks between Alice and Bob's initial positions, so both players would just claim all the stacks closer to them without crossing the other player. Bob would choose between $$$X_a - 1$$$ or $$$X_a + 1$$$ with the goal of minimizing the number of panackes Alice collects, so the final number of pancakes collected by Alice would be $$$\min($$$ sum of pancakes in stacks from $$$1$$$ to $$$X_a$$$, sum of pancakes in stacks from $$$X_a$$$ to $$$\mathbf{N})$$$.
Using these cases, for a given $$$X_a$$$, we can exactly predict the contiguous range of stacks that Alice will claim, assuming optimal play, in $$$O(1)$$$. Given a range, calculating the sum of pancakes in that range can be done in constant time if we precompute prefix sums. The precomputation can be done in $$$O(\mathbf{N})$$$ time. Finally, if we do the constant time computation for each possible $$$X_a$$$ and take the maximum, we find the answer in $$$O(\mathbf{N})$$$ time overall.
Analysis — B. Intruder Outsmarting
Reachable Numbers on a Wheel
Let us first define the concept of "reachable numbers" on a wheel. These are the set of numbers that can be displayed on a wheel by rotating it in increments of $$$\mathbf{D}$$$, starting from the initial number on the wheel as given in the input.
Example: Let us take $$$\mathbf{N} = 6$$$ and $$$\mathbf{D} = 4$$$, and we start from the number $$$1$$$ on the wheel. Then the reachable numbers are:
$$$1 + 4 = \textbf{5}$$$
$$$5 + 4 = 9 \Rightarrow 9 - 6 = \textbf{3}$$$
$$$3 + 4 = 7 \Rightarrow 7 - 6 = \textbf{1}$$$
Which brings us back to the beginning. Thus, our set of reachable numbers is {$$$1, 3, 5$$$}. Note here that we subtract $$$6$$$ from numbers $$$\gt 6$$$ because of the circular sequence of numbers on the wheel.
Test Set 1
We can try all combinations of reachable values on the wheels, check for each combination if it forms a palindrome and if it does, calculate the minimum number of operations required to form that combination.
Each wheel can have a maximum of $$$\mathbf{N}$$$ reachable values. For $$$\mathbf{W}$$$ wheels, the number of possible combinations that can be shown on the security key will be of the order of $$$\mathbf{N}^{\mathbf{W}}$$$. A combination can be generated by generating the possible values for each wheel. For a given index $$$i$$$, we can start with $$$\mathbf{X}_i$$$, then incrementing the values in steps of $$$\mathbf{D}$$$. If the value overflows beyond $$$\mathbf{N}$$$, we circle back around to $$$1$$$ by subtracting $$$\mathbf{N}$$$, which then brings us to a value lying in $$$[1 \cdots \mathbf{N}]$$$. When we get to a value that we have previously encountered, we then have the complete set of values reachable for that index. In this way, we can generate all combinations by iterating through all possible reachable values for each index.
For each index, the set of reachable positions can be generated in $$$O(\mathbf{N})$$$, and for $$$\mathbf{W}$$$ wheels, we can do this in $$$O(\mathbf{N} \times \mathbf{W})$$$. Then, we can generate all combinations in $$$O(\mathbf{N}^{\mathbf{W}})$$$.
For a particular combination $$$A$$$, we can check if it is a palindrome by simply iterating over the array and verifying that $$$A_i = A_{\mathbf{W} - i + 1}$$$ for all $$$i = 1$$$ to $$$\frac{W}{2}$$$ in $$$O(\mathbf{W})$$$.
If $$$A$$$ is verified to be a palindrome, we can find the minimum cost of achieving the combination by summing over the minimum cost of converting each $$$\mathbf{X}_i$$$ to $$$A_i$$$. For each $$$i$$$, we can perform a process similar to the combination generation process by starting with $$$\mathbf{X}_i$$$ and simulating successive forward operations (that is keep adding $$$\mathbf{D}$$$) or by simulating successive backward operations (that is keep subtracting $$$\mathbf{D}$$$) till we reach $$$A_i$$$. We take the minimum of the number of forward or backward operations as the minimum number of operations it will take to achieve the conversion. For each index $$$i$$$, we can hence find out the cost in $$$O(\mathbf{N})$$$. Therefore, the cost for all $$$\mathbf{W}$$$ wheels can be calculated in $$$O(\mathbf{N} \times \mathbf{W})$$$ time.
Thus, the overall time complexity: $$$O(\mathbf{N}^{\mathbf{W}} \times \mathbf{W} \times \mathbf{N})$$$
Test Set 2
The above brute force of generating all possible combinations approach is not feasible to pass test set 2 constraints. Instead for each pair $$$(\mathbf{X}_i, \mathbf{X}_{\mathbf{W} - i + 1})$$$ in the array $$$\mathbf{X}$$$ (for all $$$i = 1$$$ to $$$\frac{\mathbf{W}}{2}$$$) that need to be equalized to make the array a palindrome, we calculate the minimum number of operations that can do so.
Before we move forward, we transpose the set of possible values for each wheel from $$$[1 \cdots \mathbf{N}]$$$ to $$$[0 \cdots \mathbf{N} - 1]$$$. This will allow us to visualize the circular nature of operations as modulo $$$N$$$. We do this by simply subtracting $$$1$$$ from all elements in $$$\mathbf{X}$$$.
With that, let us try to find the minimum operations to change $$$\mathbf{X}_i$$$ to $$$\mathbf{X}_{\mathbf{W} - i + 1}$$$. Say we rotate the $$$i$$$-th wheel in the positive direction and try to make it equal to $$$\mathbf{X}_j$$$. Let $$$x$$$ be the number of operations it takes to do so. With operations being circular in nature, we get:
$$$\mathbf{X}_i + \mathbf{D}x \equiv \mathbf{X}_j \pmod{\mathbf{N}}$$$
$$$\Rightarrow \mathbf{X}_i + \mathbf{D}x + \mathbf{N}y = \mathbf{X}_j$$$
$$$\Rightarrow \mathbf{D}x + \mathbf{N}y = \mathbf{X}_j - \mathbf{X}_i$$$
The above equation is Linear Diophantine Equation. The greatest common divisor (GCD) of two numbers $$$i$$$ and $$$j$$$ can be written as $$$GCD_{i,j}$$$.
From the
Extended Euclidean Algorithm, an LDE (Linear Diophantine Equation) $$$ax + by = c$$$ has a solution only
if $$$c$$$ divides $$$GCD_{a,b}$$$. Thus, the above equation $$$\mathbf{D}x + \mathbf{N}y =
\mathbf{X}_j - \mathbf{X}_i$$$ will have a solution for $$$x$$$ and $$$y$$$ only if $$$\mathbf{X}_j
- \mathbf{X}_i$$$ is divisible by $$$GCD_{\mathbf{D},\mathbf{N}}$$$. Thus, for any pair $$$(\mathbf{X}_i,
\mathbf{X}_{\mathbf{W} - i + 1})$$$, if $$$\mathbf{X}_{\mathbf{W} - i + 1} - \mathbf{X}_i$$$ is not divisible by
$$$GCD_{\mathbf{D}, \mathbf{N}}$$$ the answer is IMPOSSIBLE.
Otherwise, we can use the Extended Euclidean Algorithm to solve for one possible solution for $$$x$$$ and $$$y$$$ in $$$O(\log min(\mathbf{D}, \mathbf{N}))$$$. We need the minimal operations $$$x_{min}$$$, which is $$$(\mathbf{N} + x) \pmod{\mathbf{N}}$$$. This is because a general solution for $$$(x, y)$$$ will be of the form $$$(x + k \frac{\mathbf{N}}{GCD_{\mathbf{D},\mathbf{N}}}, y - k \frac{\mathbf{D}}{GCD_{\mathbf{D},\mathbf{N}}})$$$, where $$$k$$$ is an arbitrary integer. From the above general form, we can see that the minimum number of operations $$$x_{min}$$$ would be in the range $$$[0, \frac{\mathbf{N}}{GCD_{\mathbf{D}, \mathbf{N}}} - 1]$$$ (if it is larger than that, we can simply subtract $$$\frac{\mathbf{N}}{GCD_{\mathbf{D}, \mathbf{N}}}$$$ from it to get a smaller value).
Hence, $$$x_{min} = x \pmod{\frac{\mathbf{N}}{GCD_{\mathbf{D}, \mathbf{N}}}}$$$. Since $$$x$$$ returned from the Extended Euclidean Algorithm can be negative, we add $$$\frac{\mathbf{N}}{GCD_{\mathbf{D}, \mathbf{N}}}$$$ and take modulo $$$\frac{\mathbf{N}}{GCD_{\mathbf{D}, \mathbf{N}}}$$$ again to get $$$x_{min} = (\frac{\mathbf{N}}{GCD_{\mathbf{D}, \mathbf{N}}} + x) \pmod{\frac{\mathbf{N}}{GCD_{\mathbf{D}, \mathbf{N}}}}$$$. Let us call this "forward direction $$$x_{min}$$$" as $$$x_{forward}$$$.
Similarly, we can find the minimum number of operations if we rotate $$$i$$$-th wheel in the backward direction. We get a similar equation in this case as well:
$$$\mathbf{X}_i - \mathbf{D}x \equiv \mathbf{X}_j \pmod{\mathbf{N}}$$$
$$$\Rightarrow \mathbf{X}_i - \mathbf{D}x + \mathbf{N}y = \mathbf{X}_j$$$
$$$\Rightarrow \mathbf{D}x - \mathbf{N}y = \mathbf{X}_i - \mathbf{X}_j$$$
We solve for $$$x_{min}$$$ for this equation in a similar fashion using the Extended Euclidean Algorithm as the forward case. Let us call the $$$x_{min}$$$ we get this time as $$$x_{backward}$$$.
Thus, the overall minimum operations it takes to change $$$\mathbf{X}_i$$$ to $$$\mathbf{X}_j$$$ is $$$min(x_{forward}, x_{backward})$$$. We add together the minimum costs for all such pairs (that is for all $$$i = 1$$$ to $$$\mathbf{W}/2$$$) to get the minimum cost to make the array a palindrome.
The overall time complexity: $$$O(\mathbf{W} \times \log \log min(\mathbf{N}, \mathbf{D}))$$$.
Analysis — C. Spacious Sets
For simplicty let us define a function $$$\text{minDiff(X)}$$$, which takes a list of numbers $$$X$$$ as input and returns the minimum absolute difference between any two elements in the list.
Test Set 1
Since $$$\mathbf{N}$$$ is very small, for each $$$i$$$ we can find all subsets of $$$\mathbf{A}$$$ containing $$$\mathbf{A_i}$$$ in $$$O(2^\mathbf{N})$$$ and then we can filter the subsets that have $$$\text{minDiff(subset)} \ge \mathbf{K}$$$ in $$$O(\mathbf{N}^2)$$$. We can find the size of such subsets in $$$O(\mathbf{N})$$$ and then we can find the maximum size of all such subsets while iterating through the subsets. So the total time complexity will be $$$O(\mathbf{N} \cdot 2^\mathbf{N} \cdot \mathbf{N}^2) = O(2^\mathbf{N} \cdot \mathbf{N}^3)$$$ which should work for Test Set 1.
Test Set 2
The previous algorithm would be too slow for Test Set 2, so we have to find another efficient solution.
Since the order of elements in the subset does not matter, let us sort the list $$$\mathbf{A}$$$ in increasing order and call it $$$B$$$. The output list $$$L$$$ for $$$B$$$ can be rearranged to find the output list of $$$\mathbf{A}$$$.
For simplicty, let us use the below definition on some key lists:
$$$E_i$$$ is the maximum length of some subsequence $$$s$$$ of $$$B$$$ such
that $$$s$$$ ends with $$$B_i$$$ and $$$\text{minDiff(s)} \ge \mathbf{K}$$$.
$$$S_i$$$ is the maximum length of some subsequence $$$s$$$ of $$$B$$$ such
that $$$s$$$ starts with $$$B_i$$$ and $$$\text{minDiff(s)} \ge \mathbf{K}$$$.
Now, $$$L_i$$$ can be written as $$$L_i = E_i + S_i - 1$$$ (since $$$B_i$$$ would be repeated). So we can derive $$$L$$$ by computing $$$E$$$ and $$$S$$$.
We can use dynamic programming to compute $$$E$$$ and $$$S$$$:
$$$E_i = E_{left_i} + 1$$$, where $$$\text{left}_i$$$ is the largest index less than
$$$i$$$ such that $$$B_i - B_{left_i} \ge \mathbf{K}$$$.
$$$S_i = S_{right_i} + 1$$$, where $$$\text{right}_i$$$ is the smallest index
greater than $$$i$$$ such that $$$B_{right_i} - B_i \ge \mathbf{K}$$$.
Binary Search
Now the problem reduces to compute the $$$\text{left}$$$ and $$$\text{right}$$$ lists efficiently. Since $$$B$$$ is sorted, by using binary search we can find $$$\text{left}_i$$$ and $$$\text{right}_i$$$ for each $$$i$$$ in $$$O(\log\mathbf{N})$$$. Once we know $$$\text{left}$$$ and $$$\text{right}$$$ lists then we can easily compute the $$$E$$$ and $$$S$$$ lists in $$$O(\mathbf{N})$$$, and then we can compute the $$$L$$$ list in $$$O(\mathbf{N})$$$. The total complexity will be $$$O(\mathbf{N}\log \mathbf{N} + \mathbf{N}\log\mathbf{N} + \mathbf{N} + \mathbf{N}) = O(\mathbf{N} \log \mathbf{N})$$$.
Sweeping Technique
Instead of binary search, there is a more efficient algorithm if we observe the pattern of $$$\text{left}_i$$$ and $$$\text{right}_i$$$ values. The observation is: as $$$i$$$ increases, $$$\text{left}_i$$$ increases, and as $$$i$$$ decreases, $$$\text{right}_i$$$ decreases.
Now initialize a variable $$$x = 0$$$ and try to find $$$\text{left}_i$$$ while
iterating through $$$i$$$. At the $$$i$$$-th iteration, keep incrementing $$$x$$$
by $$$1$$$ till you find $$$B_i - B_{x+1} \lt \mathbf{K}$$$ or $$$x = i-1$$$.
Now $$$\text{left}_i = x$$$. At the end of the $$$i$$$-th step $$$x = \text{left}_i$$$.
As $$$x$$$ always increases, total increment step of $$$x$$$ can be at max
length of list which is $$$\mathbf{N}$$$. So the amortized time complexity of finding the
$$$\text{left}$$$ list is $$$O(\mathbf{N})$$$.
Similarly, $$$\text{right}$$$ list can found by iterating from right to left (from $$$\mathbf{N}$$$ to $$$1$$$),
and initializing the $$$x$$$ with $$$\mathbf{N}$$$ and keep decrementing in $$$O(\mathbf{N})$$$.
Once we compute the $$$\text{left}$$$ and $$$\text{right}$$$ lists, we can compute $$$L$$$
list in $$$O(\mathbf{N})$$$. Total time complexity is $$$O(\mathbf{N}\log\mathbf{N} +\mathbf{N}) =
O(\mathbf{N}\log\mathbf{N})$$$.
Analysis — D. Railroad Maintenance
Test Set 1
We can represent the railroad network as an undirected graph by creating a node for each station, and then creating an edge for each pair of adjacent stations in each train line, that is, for every $$$1 \le i \le \mathbf{L}$$$, and for every $$$1 \le j \le \mathbf{K_i} - 1$$$, add an edge between nodes $$$\mathbf{S_{i,j}}$$$ and $$$\mathbf{S_{i,{j+1}}}$$$.
Let's define an undirected graph to be connected if, for every pair of vertices $$$x$$$ and $$$y$$$, there is a path between them. From that definition, we can say that a train line is essential if, by removing it, a connected graph stops being connected.
Given an undirected graph, to check if it's connected, it is enough to check if a single arbitrary vertex can reach all others. To prove it, let's assume that a vertex $$$v$$$ can reach all other vertices. Then, because the graph is undirected, all vertices can also reach vertex $$$v$$$. Therefore, for any pair of vertices $$$x$$$ and $$$y$$$, we can see that $$$x$$$ can reach $$$y$$$ because $$$x$$$ can reach $$$v$$$ and $$$v$$$ can reach $$$y$$$.
Now we can check if a train line is essential by building the graph without the edges that belong to that train line, and checking if the graph is not connected. If we do that for each train line, we will be able to solve Test Set 1.
Let's define $$$E$$$ as the number of edges of the entire graph, that is, $$$E = \mathbf{K_1} + \mathbf{K_2} + \dots + \mathbf{K_L}$$$. The time complexity to build the graph is $$$O(\mathbf{N} + E)$$$. The time complexity to check if the graph is connected is $$$O(\mathbf{N} + E)$$$. These two operations have to be performed for every train line, therefore the overall time complexity of the algorithm will be $$$O(\mathbf{L} \times (\mathbf{N} + E))$$$.
Test Set 2
The algorithm described for Test Set 1 is too slow for the limits of Test Set 2.
Now let's introduce the concept of articulation points (or cut vertices), which are vertices that, when removed (along with its adjacent edges), make a connected undirected graph not be connected anymore.
Let's explore a different way to represent the railroad network. We will first create $$$\mathbf{L}$$$ special nodes to represent each train line, and then add edges between each train line's special node and the stations that such train line goes through. In other words, for every $$$1 \le i \le \mathbf{L}$$$, let's create a special node $$$\mathbf{P_i}$$$, and for every $$$1 \le j \le \mathbf{K_i}$$$, add an edge between nodes $$$\mathbf{S_{i,j}}$$$ and $$$\mathbf{P_i}$$$.
For this graph representation, the action of shutting down a train line can be seen as removing its special node and all its adjacent edges. Now notice that if a train line's special node is an articulation point, that means that such train line is essential.
To find all articulation points of an undirected graph we can use this modified Depth First Search (DFS) algorithm.
The time complexity to build the graph is $$$O(\mathbf{N} + E)$$$. The time complexity to run the modified DFS algorithm is $$$O(\mathbf{N} + E)$$$. Therefore, the overall time complexity of the algorithm will be $$$O(\mathbf{N} + E)$$$.
Analysis — E. Railroad Management
For this problem, let's define $$$R_i$$$ as the number of railroad cars that the station $$$i$$$ has already received from other stations. At the beginning, $$$R_i = 0$$$ for all $$$i$$$. Then, each time we make a shipment from station $$$i$$$ to station $$$\mathbf{D_i}$$$, $$$R_{\mathbf{D_i}}$$$ increases by $$$\mathbf{C_i}$$$.
Test Set 1
The shipment order can be defined as a permutation of the network stations. In Test Set 1, the limits are small enough that we can try every possible order and output the smallest answer among all of them.
For a given order, we process the shipments one by one. For the station $$$i$$$, let $$$cost(i)$$$ be the number of additional railroad cars required to complete the shipment. Since we can reuse the received cars to reduce the answer, $$$cost(i) = \max(\mathbf{C_i} - R_i, 0)$$$. We can then add $$$cost(i)$$$ to the answer, and also increase $$$R_{\mathbf{D_i}}$$$ by $$$\mathbf{C_i}$$$.
The answer for a given shipment order can be calculated in $$$O(\mathbf{N})$$$ and there are $$$\mathbf{N}!$$$ different orders. Therefore, a test case can be solved in $$$O(\mathbf{N}! \times \mathbf{N})$$$.
Test Set 2
Let's create a weighted directed graph with $$$\mathbf{N}$$$ vertices (one for each station) and $$$\mathbf{N}$$$ edges (one for each shipment). In other words, for each vertex $$$i$$$ there will be exactly one outgoing edge, from $$$i$$$ to $$$\mathbf{D_i}$$$, with weight $$$\mathbf{C_i}$$$.
Note that for each edge $$$e$$$ from $$$u$$$ to $$$v$$$, if $$$e$$$ is not part of a cycle, then it is optimal to complete the shipment of $$$u$$$ before the shipment of $$$v$$$. The reasoning behind this is that $$$v$$$ can reuse railroad cars sent by $$$u$$$, possibly reducing the answer, while it is impossible to do the opposite: no car can ever travel from $$$v$$$ to $$$u$$$. Therefore, we can apply the following process:
- Pick any vertex $$$u$$$ with no incoming edges
- Increase the answer by $$$cost(u)$$$ and $$$R_{\mathbf{D_u}}$$$ by $$$\mathbf{C_u}$$$
- Erase the vertex $$$u$$$ and its outgoing edge from the graph
- Repeat while there are vertices with no incoming edges.
Now, since each remaining vertex has at least one incoming edge and exactly one outgoing edge, the graph is now a collection of disjoint simple cycles. Thus, we can add the cost of each cycle separately.
One way to calculate the cost of a cycle is to traverse it for each possible starting point, completing the shipments in order, and then use the smallest answer among all traversals. However, the time complexity of this is $$$O(\mathbf{N}^2)$$$, which is not enough to pass Test Set 2.
We can optimize this to a linear solution with the following observation: suppose that the starting vertex is $$$s$$$. The cost of $$$s$$$ is $$$cost(s) = \max(\mathbf{C_s} - R_s, 0)$$$. For any other vertex $$$u$$$ which is not the starting one, its cost is $$$cost\_in\_cycle(u) = \max(\mathbf{C_u} - R_u - \mathbf{C_{pred(u)}}, 0)$$$, where $$$pred(u)$$$ is the predecessor of $$$u$$$ in the cycle (i.e. $$$\mathbf{D_{pred(u)}} = u$$$). Note that this is independent of $$$s$$$, hence we can precalculate $$$sum\_of\_costs$$$ as the sum of $$$cost\_in\_cycle(u)$$$ for all vertices $$$u$$$ in the cycle and compute the cost for each starting vertex $$$s$$$ as $$$sum\_of\_costs - cost\_in\_cycle(s) + cost(s)$$$, in constant time.