Google Kick Start Archive — Round C 2021 problems
Overview
Thank you for participating in Kick Start 2021 Round C!
Cast
Smaller Strings: Written by Vipin Singh and prepared by Eric Dong.
Alien Generator: Written by Gregory Yap and prepared by Vijay Krishan Pandey.
Rock Paper Scissors: Written by Ian Tullis and prepared by Eric Dong.
Binary Operator: Written by Pablo Heiber and prepared by Anson Ho.
Solutions, other problem preparation, reviews and contest monitoring by Abhishek Saini, Akshay Mohan, Akul Siddalingaswamy, Amr Aboelkher, Aneesh D H, Ankit Goyal, Anoopam Mishra, Anson Ho, Anurag Singh, Ashveen Bansal, Bao Nguyen, Bartosz Kostka, Bohdan Pryshchenko, Chong Guo, Cristhian Bonilha, Deeksha Kaurav, Diksha Saxena, Eric Dong, Gagan Madan, Gregory Yap, Himanshi Jain, Hsin-cheng Hou, Ian Tullis, Jaaz Meribole, Janice Chui, Jared Gillespie, Jie Zhou, Joe Simons, Kashish Bansal, Khaled Ali, Lizzie Sapiro Santor, Maneeshita Sharma, Michał Łowicki, Mohamed Yosri Ahmed, Ossama Mahmoud, Pablo Heiber, Phil Sun, Priya Gupta, Samiksha Gupta, Sanyam Garg, Sarah Young, Shweta Karwa, Swapnil Gupta, Swapnil Mahajan, Szymon Rzeźnik, Teja Vardhan Reddy Dasannagari, Umang Goel, Vijay Krishan Pandey, Vipin Singh, Viplav Kadam, Wajeb Saab.
Analysis authors:
- Smaller Strings: Cristhian Bonilha
- Alien Generator: Akul Siddalingaswamy
- Rock Paper Scissors: Hsin-cheng Hou
- Binary Operator: Hsin-cheng Hou
A. Smaller Strings
Problem
You are given an integer $$$\mathbf{K}$$$ and a string $$$\mathbf{S}$$$ of length $$$\mathbf{N}$$$, consisting of lowercase letters from the first $$$\mathbf{K}$$$ letters of the English alphabet. Find the number of palindrome strings of length $$$\mathbf{N}$$$ which are lexicographically smaller than $$$\mathbf{S}$$$ and consist of lowercase letters from the first $$$\mathbf{K}$$$ letters of the English alphabet.
A string composed of ordered
letters $$$a_1, a_2, \dots, a_n$$$
is lexicographically smaller than another string of the same length $$$b_1, b_2, \dots, b_n$$$
if $$$a_i < b_i$$$, where $$$i$$$ is the first index where
characters differ in the two strings. For example, the following strings are arranged in lexicographically
increasing order: aaa, aab, aba, cab.
A palindrome is a string that is the same written forwards and backwards.
For example, anna, racecar, aaa and x are all palindromes, while
ab, frog and yoyo are not.
As the number of such strings can be very large, print the answer modulo $$$10^9 + 7$$$.
Input
The first line of the input gives the number of test cases, $$$\mathbf{T}$$$. $$$\mathbf{T}$$$ test cases follow.
Each test case consists of two lines. The first line contains two integers $$$\mathbf{N}$$$ and $$$\mathbf{K}$$$. The second line contains a string $$$\mathbf{S}$$$ of length $$$\mathbf{N}$$$, consisting of lowercase letters.
Output
For each test case, output one line containing Case #$$$x$$$: $$$y$$$,
where $$$x$$$ is the test case number (starting from 1) and $$$y$$$ is the number of
lexicographically smaller palindrome strings modulo $$$10^9 + 7$$$.
Limits
Memory limit: 1 GB.
$$$1 \le \mathbf{T} \le 100$$$.
The string $$$\mathbf{S}$$$ consists of lowercase letters from the first $$$\mathbf{K}$$$ letters of the English alphabet.
Test Set 1
Time limit: 20 seconds.
$$$1 \le \mathbf{N} \le 8$$$.
$$$1 \le \mathbf{K} \le 5$$$.
Test Set 2
Time limit: 10 seconds.
$$$1 \le \mathbf{N} \le 10^5$$$.
$$$1 \le \mathbf{K} \le 26$$$.
Sample
3 2 3 bc 5 5 abcdd 1 5 d
Case #1: 2 Case #2: 8 Case #3: 3
In Sample Case #1, the palindromes are ["aa", "bb"].
In Sample Case #2, the palindromes are
["aaaaa", "aabaa", "aacaa", "aadaa", "aaeaa", "ababa", "abbba", "abcba"].
In Sample Case #3, the palindromes are ["a", "b", "c"].
B. Alien Generator
Problem
Astronauts have landed on a new planet, Kickstartos. They have discovered a machine on the planet: a generator that creates gold bars. The generator works as follows. On the first day, an astronaut inputs a positive integer $$$K$$$ into the generator. The generator will produce $$$K$$$ gold bars that day. The next day, it will produce $$$K+1$$$, the following day, $$$K+2$$$, and so on. Formally, on day $$$i$$$, the generator will produce $$$K+i-1$$$ gold bars.
However, the astronauts also know that there is a limitation to the generator:
if on any day, the generator would end up producing more than $$$\mathbf{G}$$$ gold bars in total across all the days, then it will
break down on that day and will produce $$$0$$$ gold bars on that day and thereafter.
The astronauts would like to avoid this, so they want to produce exactly $$$\mathbf{G}$$$ gold bars.
Consider $$$K=2$$$ and $$$\mathbf{G}=8$$$. On day $$$1$$$, the generator would produce $$$2$$$ gold bars. On day $$$2$$$, the generator would produce $$$3$$$ more gold bars making the total gold bars is equal to $$$5$$$. On day $$$3$$$, the generator would produce $$$4$$$ more gold bars which would lead to a total of $$$9$$$ gold bars. Thus, the generator would break on day $$$3$$$ before producing $$$4$$$ gold bars. Hence, the total number of gold bars generated is $$$5$$$ in this case.
Formally, for a given $$$\mathbf{G}$$$, astronauts would like to know how many possible values of $$$K$$$ on day $$$1$$$ would eventually produce exactly $$$\mathbf{G}$$$ gold bars.
Input
The first line of the input gives the number of test cases, $$$\mathbf{T}$$$. $$$\mathbf{T}$$$ lines follow.
Each line contains a single integer $$$\mathbf{G}$$$, representing the maximum number of gold bars the generator
can generate.
Output
For each test case, output one line containing Case #$$$x$$$: $$$y$$$,
where $$$x$$$ is the test case number (starting from $$$1$$$) and $$$y$$$ is the number of
possible values of $$$K$$$
on day $$$1$$$ that would eventually produce exactly $$$\mathbf{G}$$$ gold bars.
Limits
Time limit: 30 seconds.
Memory limit: 1 GB.
$$$1 \le \mathbf{T} \le 100$$$
Test Set 1
$$$1 \le \mathbf{G} \le 10^4$$$.
Test Set 2
$$$1 \le \mathbf{G} \le 10^{12}$$$ for at most $$$20$$$ test cases.
For the remaining cases, $$$1 \le \mathbf{G} \le 10^4$$$.
Sample
2 10 125
Case #1: 2 Case #2: 4
For Sample Case #1, there are $$$2$$$ possible values of $$$K$$$ $$$(1,10)$$$ that would eventually produce exactly $$$10$$$ gold bars. For $$$K=1$$$, we will have $$$1+2+3+4=10$$$ gold bars after $$$4$$$ days, and for $$$K=10$$$, we will have $$$10$$$ gold bars after just $$$1$$$ day.
For Sample Case #2, there are $$$4$$$ possible values of $$$K$$$ $$$(8,23,62,125)$$$ that would eventually produce exactly $$$125$$$ gold bars.
C. Rock Paper Scissors
Problem
You and your friend like to play Rock Paper Scissors. Each day you play exactly $$$60$$$ rounds and at the end of each day, you tally up the score from these $$$60$$$ rounds.
During each round, without any knowledge of the other person's choice, you each make your choice.
Then, you both reveal the choice you made and determine your score. Rock wins over Scissors,
Scissors wins over Paper, and Paper wins over Rock.
Let R represent Rock, P represent Paper, and S represent
Scissors. Every day you both agree on values $$$\mathbf{W}$$$ and $$$\mathbf{E}$$$. If your choice wins, you get $$$\mathbf{W}$$$ points. If you and your friend both pick the same
choice, you get $$$\mathbf{E}$$$ points. If your choice loses, you get nothing.
By accident, you see your friend's strategy written in an open notebook on a desk one day. Your
friend keeps track of how many times you have chosen R, P, and
S so far during one day.
Let $$$A_i$$$ be your choice of R, P, or S on round $$$i$$$,
while $$$B_i$$$ is your friend's choice on the same round.
Let $$$r_i$$$ be the number of times $$$A_j =$$$ R for $$$1 \le j \le (i-1)$$$.
Similarly, let $$$p_i$$$ and $$$s_i$$$ be the total number of times you have chosen
P and S, respectively, prior to round $$$i$$$.
On round $$$1$$$ of each day, $$$i=1$$$ and $$$r_1=s_1=p_1=0$$$, and your friend plays randomly due to
the lack of information (i.e. your friend chooses each option with probability $$$1/3$$$).
On every subsequent round, your friend decides $$$B_i$$$ by choosing
R with probability $$$\Pr[$$$R$$$]=s_i/(i-1)$$$, P with
probability $$$\Pr[$$$P$$$]=r_i/(i-1)$$$, and S with probability
$$$\Pr[$$$S$$$]=p_i/(i-1)$$$. This strategy is adaptive and tough to beat!
You are going on vacation for the next $$$\mathbf{T}$$$ days. You must leave your assistant with instructions on what choice to pick each round each day. Let integer $$$\mathbf{X}$$$ be the average reward you are aiming for in this game after $$$\mathbf{T}$$$ days. Given $$$\mathbf{W}$$$ and $$$\mathbf{E}$$$ (different values for different days), provide your instructions as a string of $$$60$$$ characters, ordered from round $$$1$$$ to round $$$60$$$. Each character represents your choice for the corresponding round. Your goal is to choose your set of instructions so that the average expected value of the reward across all the days of your gameplay is at least $$$\mathbf{X}$$$. Note that you can choose different instructions for different values of $$$\mathbf{W}$$$ and $$$\mathbf{E}$$$.
Input
The first line of the input gives the number of days, $$$\mathbf{T}$$$. The second line contains an integer $$$\mathbf{X}$$$, your targeted average reward after these $$$\mathbf{T}$$$ days. Then the description of $$$\mathbf{T}$$$ days follows. Each day is described as two integers $$$\mathbf{W}$$$ and $$$\mathbf{E}$$$. $$$\mathbf{W}$$$ is how much you get if your choice wins for each round that day. $$$\mathbf{E}$$$ is how much you get for each round when your choice is the same as your friend's choice.
All the tests (except the sample test below) are generated as follows. We choose $$$50$$$ different values $$$G$$$ between $$$5$$$ and $$$95$$$ (with uniform distribution). Then for each of these values, there will be $$$4$$$ days, with $$$\mathbf{W}$$$ equal to $$$10 \times G$$$ and $$$\mathbf{E}$$$ equal to $$$\mathbf{W}, \frac{\mathbf{W}}{2}, \frac{\mathbf{W}}{10}$$$, and $$$0$$$. Do not assume anything about the order of these days.
Output
For each day, output one line containing Case #$$$x$$$: $$$A_1 A_2 \dots A_{60}$$$,
where $$$x$$$ is the day number (starting from 1) and $$$A_i$$$ is your choice of
R, P, or S on the $$$i$$$-th round of the game.
There should be no spaces between the choices.
The list of choices should result in an expected value that is greater than or equal to $$$\mathbf{X}$$$ on average after $$$\mathbf{T}$$$ days. There may be multiple solutions for a test case. If so, you may output any one of them. It is guaranteed that for given $$$\mathbf{X}$$$ a solution exists.
Limits
Time limit: 40 seconds.
Memory limit: 1 GB.
$$$\mathbf{T} = 200$$$ (for all tests except the sample where $$$\mathbf{T} = 2$$$).
$$$50 \le \mathbf{W} \le 950$$$.
$$$0 \le \mathbf{E} \le \mathbf{W}$$$ and $$$\mathbf{E}$$$ is one of $$$\mathbf{W}, \frac{\mathbf{W}}{2}, \frac{\mathbf{W}}{10}$$$, or $$$0$$$.
Each day you play exactly 60 rounds.
Test Set 1
$$$\mathbf{X} = 14600$$$.
Test Set 2
$$$\mathbf{X} = 15500$$$.
Test Set 3
$$$\mathbf{X} = 16400$$$.
Sample
2 30 60 0 60 60
Case #1: RSRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRR Case #2: PPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPP
In this sample test our targeted (average) reward across all $$$\mathbf{T}=2$$$ days is $$$30$$$.
For the first day, since $$$\mathbf{W}=60$$$, you can reach the total target by winning at least once. One possible strategy is to just get to that single win.
- On round $$$1$$$, you choose $$$A_1 =$$$
R. You have an equal chance of a win, a tie, or a loss, giving you an expected value of $$$20$$$. - On round $$$2$$$, $$$r_2=1$$$ and $$$p_2=s_2=0$$$. Your friend's probability of choosing
Pis $$$\Pr[$$$P$$$]=r_2/1=1$$$, which guarantees your friend's choice $$$B_2= $$$P. - If you choose $$$A_2=$$$
S, you are guaranteed a win, giving you a score of $$$60$$$ for round $$$2$$$. - Regardless of what you choose for all following rounds in the game, your expected value after just two rounds is $$$20 + 60 = 80$$$, which is enough to reach our target.
Moreover, as we already will have the average across all 2 days at least $$$\frac{80}{2} = 40 \ge \mathbf{X} = 30$$$, for the second day we can use any strategy.
Note that this is not a unique solution. As long as the average expected score is $$$\ge 30$$$, other outputs would also be accepted.
D. Binary Operator
Problem
You are given a list of valid arithmetic expressions using non-negative integers, parentheses (),
plus +, multiply *, and an extra operator #.
The expressions are fully parenthesized and in infix notation.
A fully parenthesized expression is an expression where every operator and its operands are wrapped in a single parenthesis.
For example, the expression $$$x+y$$$ becomes $$$(x+y)$$$ when fully parenthesized, and $$$x+y+z$$$ becomes $$$((x+y)+z)$$$.
However, $$$0$$$ is still $$$0$$$ when fully parenthesized, because it consists of a single number and no operators. $$$((x+y))$$$ is not
considered fully parenthesized because it has redundant parentheses.
The operators + and * denote addition and multiplication, and # can be any
total function.
You want to group the expressions into equivalence classes,
where expressions are in the same equivalence class if and only if they are guaranteed to result in the same numeric value,
regardless of which function # represents.
You can assume that # represents the same function across all expressions in a given test case.
That might mean that # represents some known function like addition or subtraction,
but not both in different parts of the same test case.
For example, consider the following expressions:
$$$F_1$$$=((1#(1+1))+((2#3)*2))$$$F_2$$$=(((2#3)+(1#2))+(2#3))$$$F_3$$$=((2*(2#3))+(1#2)).
Let A = 1#2, and let B = 2#3. Then we can say $$$F_1$$$=$$$F_2$$$=$$$F_3$$$,
regardless of the function # represents because the expressions can be rewritten as:
$$$F_1$$$=((1#2)+((2#3)*2))=(A+(B*2))=(A+2B)$$$F_2$$$=(((2#3)+(2#3))+(1#2))=((B+B)+A)=(A+2B)$$$F_3$$$=((2*(2#3))+(1#2))=((2*B)+A)=(A+2B).
However, consider the expressions $$$F_4$$$=((0#0)+(0#0)) and $$$F_5$$$=(0#0).
If # represents addition, then $$$F_4=F_5$$$.
However, if # is $$$f(x,y)=C$$$, such that $$$C$$$ is a non-zero integer, then
$$$F_4 \neq F_5$$$ since $$$2C \neq C$$$.
Therefore $$$F_4$$$ and $$$F_5$$$ are not in the same equivalence class.
Input
The first line of the input gives the number of test cases, $$$\mathbf{T}$$$. $$$\mathbf{T}$$$ test cases follow.
Each test case begins with a line containing the integer $$$\mathbf{N}$$$. $$$\mathbf{N}$$$ lines follow.
$$$i$$$-th line contains one expression, $$$\mathbf{E_i}$$$.
Output
For each test case, output one line containing Case #$$$x$$$: $$$Y_1, Y_2, \dots, Y_\mathbf{N}$$$,
where $$$x$$$ is the test case number (starting from 1) and $$$Y_i$$$ is the
lexicographically smallest
sequence satisfying the conditions below:
- $$$1 \le Y_i \le Z$$$, where $$$Z$$$ denotes the total number of equivalence classes in a given test case.
- $$$Y_i = Y_j$$$ if and only if $$$\mathbf{E_i}$$$ and $$$\mathbf{E_j}$$$ are in the same equivalence class.
Limits
Time limit: 20 seconds.
Memory limit: 1 GB.
$$$1 \le \mathbf{T} \le 100$$$
$$$1 \le \mathbf{N} \le 100$$$
The length of $$$\mathbf{E_i}$$$ is at most $$$100$$$, for all $$$i$$$.
$$$\mathbf{E_i}$$$ will be valid, for all $$$i$$$.
Test Set 1
No more than one # in each expression.
Test Set 2
No additional constraints.
Sample
Note: there are additional samples that are not run on submissions down below.3 7 (1*(1#2)) (0*(1#2)) (1#2) 0 (3*0) ((1#2)*1) (((1+(1#2))+3)*0) 5 (1*((1+(2#2))+3)) ((0+(2#2))+4) (100#2) (((1+(2#2))+3)*1) ((50*2)#2) 2 (9999999999999999999999999999999999999999+1) (100000000000000000000*100000000000000000000)
Case #1: 1 2 1 2 2 1 2 Case #2: 1 1 2 1 2 Case #3: 1 1
This sample test set contains $$$3$$$ test cases.
Test case 1 has $$$7$$$ expressions and a total of $$$2$$$ equivalence classes, denoted $$$G_1$$$ and $$$G_2$$$.
$$$\mathbf{E_1}$$$=(1*(1#2)), $$$\mathbf{E_2}$$$=(0*(1#2)), $$$\dots$$$, $$$\mathbf{E_7}$$$=(((1+(1#2))+3)*0).
There are $$$2$$$ sequences of $$$Y_i$$$ that satisfy the requirement about equivalence classes in test case 1:
2 1 2 1 1 2 1 and 1 2 1 2 2 1 2.Since
1 2 1 2 2 1 2 is the lexicographically smaller one, the output for test case 1 is:
Case #1: 1 2 1 2 2 1 2.
Test case 2 has $$$5$$$ expressions and a total of $$$2$$$ equivalence classes, denoted $$$G_1$$$ and $$$G_2$$$.
$$$\mathbf{E_1}$$$, $$$\mathbf{E_2}$$$, and $$$\mathbf{E_4}$$$ belong to $$$G_1$$$, and $$$\mathbf{E_3}$$$ and $$$\mathbf{E_5}$$$ belong to $$$G_2$$$.
Therefore, the output for test case 2 is: Case #2: 1 1 2 1 2.
Test case 3 has $$$2$$$ expressions that do not contain any #.
These two expressions evaluate to the same value, and therefore belong to the same equivalence class.
Additional Sample - Test Set 2
The following additional sample fits the limits of Test Set 2. It will not be run against your submitted solutions.1 9 ((2*(2#3))+(1#2)) (0*(1#2)) 0 ((1#(1+1))+((2#3)*2)) (3*0) (1#(2#3)) (((2#3)+(1#2))+(2#3)) (4#7) (7#4)
Case #1: 1 2 2 1 2 3 1 4 5
In the provided sample, there are a total of $$$5$$$ equivalence classes. The first expression in the input is
((2*(2#3))+(1#2)). All expressions from its equivalence class are denoted with 1 in the output.
The equivalence class denoted with 2 consists of (0*(1#2)), 0, and (3*0).
The equivalence class denoted with 3 consists of (1#(2#3)).
Finally, the last two expressions, (4#7) and (7#4), are not equivalent to any of the prior
expressions or to one another.
Note that 2 1 1 2 1 3 2 5 4 is one of many other sequences that satisfy the requirement about
equivalence classes the given input, but it is not a correct answer because this sequence is not
the lexicographically smallest one.
Analysis — A. Smaller Strings
Test Set 1
Let us calculate the upper bound of a brute-force solution in the worst case scenario.
Given the limits of Test Set 1, $$$1 \le \mathbf{K} \le 5$$$ and $$$1 \le \mathbf{N} \le 8$$$, we can compute the total number of strings, in the worst case scenario, to be $$$\mathbf{K} ^ \mathbf{N} = 5 ^ 8 = 390625$$$. This number is low enough to generate all of them, keeping track of the ones that are palindromes and lexicographically smaller than the input string $$$\mathbf{S}$$$.
Test Set 2
For Test Set 2, the limits are much higher, so the strategy mentioned above is too slow.
Let us start by making an observation about the definition of lexicographically smaller strings. Say we have two strings $$$A$$$ and $$$B$$$ of the same length, and $$$i$$$ is the first position at which $$$A_i$$$ and $$$B_i$$$ differ. By definition, if $$$A_i \lt B_i$$$, then $$$A$$$ is lexicographically smaller than $$$B$$$. Now notice no matter what characters we append to the end of the strings $$$A$$$ and $$$B$$$, we still have that $$$A$$$ is lexicographically smaller than $$$B$$$.
Let us define $$$H = \lceil \frac{\mathbf{N}}{2} \rceil$$$, which is the size of the first half of the input string $$$\mathbf{S}$$$, rounded up. Also, let us define $$$S'$$$ to be the prefix of length $$$H$$$ from the input string $$$\mathbf{S}$$$.
To come up with an efficient solution, we only need to count the number of strings $$$T'$$$ of size $$$H$$$ (not necessarily palindromes) are lexicographically smaller than $$$S'$$$ (with the caveat below). The reason is based on the above observation.
Insight 1: If $$$T'$$$ is lexicographically smaller than $$$S'$$$, then appending appropriate $$$\mathbf{N} - H$$$ characters to make it a palindrome of size $$$\mathbf{N}$$$, will keep it lexicographically smaller than $$$\mathbf{S}$$$.
We can construct a palindrome string $$$T$$$ of size $$$\mathbf{N}$$$ as follows. Let $$$R'$$$ be the reverse of $$$T'$$$. If $$$\mathbf{N}$$$ is even, then combine $$$T'$$$ and $$$R'$$$. For example, if $$$\mathbf{N} = 6$$$ and $$$T' =$$$ "$$$abc$$$", then $$$T =$$$ "$$$abccba$$$". If $$$\mathbf{N}$$$ is odd, then combine $$$T'$$$ (without the last character) and $$$R'$$$. And for example, if $$$\mathbf{N} = 7$$$ and $$$T' =$$$ "$$$abcd$$$", then $$$T =$$$ "$$$abcdcba$$$".
Let us see how these ideas fit together with an example: Let us say that $$$\mathbf{S} =$$$ "$$$tomato$$$" and $$$\mathbf{N} = 6$$$. Then, we have that $$$H = \lceil \frac{6}{2} \rceil = 3$$$ and $$$S' =$$$ "$$$tom$$$". If we choose an arbitrary string $$$T' =$$$ "$$$pea$$$", we can observe that "$$$pea$$$" is lexicographically smaller than "$$$tom$$$". Therefore, we can build a palindrome string $$$T =$$$ "$$$peaaep$$$", which is guaranteed to be lexicographically smaller than "$$$tomato$$$".
Hence, the problem can now be simplified to finding how many strings of size $$$H$$$ (not necessarily palindromes) are lexicographically smaller than $$$S'$$$.
The only caveat is for the string $$$T' = S'$$$. By just analysing $$$T'$$$, we can not say whether $$$T$$$ is going to be lexicographically smaller than $$$\mathbf{S}$$$ or not. Therefore, for this particular $$$T'$$$ we should generate $$$T$$$ manually and check if it is lexicographically smaller than $$$\mathbf{S}$$$, and if so, add that to our answer.
Also notice we do not have to generate all of the possible lexicographically smaller strings and count them. Notice, if we assume first $$$\mathbf{K}$$$ letters of the alphabet as digits in $$$\mathbf{K}$$$-based numeric system, i.e. $$$a=0, b=1, \cdots, z=25$$$, then every string $$$T'$$$ lexicographically smaller than $$$S'$$$ can be mapped to a number that is smaller than the number corresponding to $$$S'$$$(and vice versa).
Insight 2: In order to calculate the number of strings lexicographically smaller than $$$S'$$$, we just need to convert the $$$\mathbf{K}$$$-based number corresponding $$$S'$$$ to base 10.
For example, if $$$\mathbf{K} = 4$$$ and we want to find the number of strings lexicographically
smaller than $$$S' = $$$"$$$da$$$". Converting $$$S'$$$ from base-4 to base-10 will give
$$$3 \times 4^1 + 0 \times 4^0 = 12$$$ which is the number of strings smaller than "$$$da$$$"
which are ["aa", "ab", "ac", "ad", "ba", "bb", "bc", "bd", "ca", "cb", "cc", "cd"].
Analysis — B. Alien Generator
Test Set 1
We can check for every $$$i, (1 \le i \le \mathbf{G})$$$ whether there exists a $$$k$$$ such that $$$$\sum_{j=0}^{k}(i+ j) = \sum_{j=0}^{k}i + \sum_{j=0}^{k}j = ((k+1) \times i) + \frac{k\times(k+1)}{2} = \mathbf{G}$$$$ Finding such a $$$k$$$ (if one exists) can be done by binary searching the range $$$[0, \mathbf{G}]$$$, and hence takes $$$O(\log \mathbf{G})$$$ time. For a candidate $$$k$$$ in that range, we check if $$$((k+1) \times i) + \frac{k \times (k+1)}{2} = \mathbf{G}$$$ and alter the range based on the equality. Time complexity here is $$$O(\mathbf{G} \log \mathbf{G})$$$.
Alternative solution
For this Test Set, we can implement a brute force solution. We iterate over every $$$i, (1 \le i \le \mathbf{G})$$$ and try to sum up numbers $$$[i, i+1, i+2, \dots]$$$ until the sum exceeds or equals $$$\mathbf{G}$$$. If the sum equals $$$\mathbf{G}$$$, then we increment our result by one. Here, each iteration takes $$$O(\mathbf{G}/i)$$$ time. $$$$\sum_{i=1}^{\mathbf{G}}(1/i) = O(log(\mathbf{G}))$$$$ Therefore, the overall time complexity of this solution is $$$O(\mathbf{G} \log \mathbf{G})$$$.
Test Set 2
Since the upper bound on $$$\mathbf{G}$$$ is $$$10^{12}$$$, $$$O(\mathbf{G} \log \mathbf{G})$$$ solution times out. Let us define $$$H = \lceil \sqrt{2 \times \mathbf{G}} \rceil$$$. An observation can be made that $$$k \le H$$$. Therefore, for each $$$k$$$ in the range $$$[0, H]$$$, we can binary search for $$$i$$$ in the range $$$[1, \mathbf{G}]$$$ thereby making the total runtime $$$O(\sqrt{\mathbf{G}} \times \log(\mathbf{G}))$$$. This solution might not pass within the time limit for slow languages. Therefore, we will look at a better solution next. We can rewrite the equation we saw in Test Set 1 as $$$i = \frac{2 \times \mathbf{G} - k^{2} - k}{2 \times (k+1)}$$$. Next, for each $$$k$$$ in the range $$$[0, H]$$$, we can check in $$$O(1)$$$ whether we can obtain a positive integer value for $$$i$$$ that satisfies the above equation. The runtime here is $$$O(\sqrt{\mathbf{G}})$$$.
Alternative solution
We can dig deeper into the relationship between $$$\mathbf{G}$$$, $$$K$$$, and $$$d$$$, the number of days it takes for the machine to produce exactly $$$\mathbf{G}$$$ gold starting at $$$K$$$ on day one. They form the equation $$$$\frac{d(K + (K + d - 1))}{2} = \mathbf{G}$$$$ which is equivalent to $$$d(d + (2K - 1)) = 2\mathbf{G}$$$. Since one of $$$d$$$ and $$$(d + (2K - 1))$$$ is even and the other is odd, any pair of positive integers $$$x$$$ and $$$y$$$ such that exactly one of them is even and $$$x \times y = 2\mathbf{G}$$$ can be mapped to them with the smaller of the two being $$$d$$$ and the larger one $$$(d + (2K - 1))$$$, which is always greater than $$$d$$$. Since each mapping produces a different $$$d$$$, each pair corresponds to a unique solution for $$$d$$$ and $$$K$$$. Conversely, every pair of $$$d$$$ and $$$K$$$ that satisfies the equation corresponds to a different $$$x, y$$$ pair.
To count the number of such pairs, let $$$g$$$ be the largest odd factor of $$$2\mathbf{G}$$$. Note that any (ordered) pair $$$x', y'$$$ such that $$$x' \times y' = g$$$ corresponds to a pair $$$x = \frac{2\mathbf{G}}{g}x'$$$ and $$$y = y'$$$. Finally, assume the prime factorization of $$$g$$$ is $$$$g = p_1^{\alpha_1}p_2^{\alpha_2} \cdots p_n^{\alpha_n}$$$$ the number of such ordered pairs is $$$(\alpha_1 + 1)(\alpha_2 + 1) \cdots (\alpha_n + 1)$$$. We can thus prime factorize $$$\mathbf{G}$$$, ignore the 2, and multiply all other prime powers accordingly. Prime factorization can be trivially implemented in $$$O(\sqrt{\mathbf{G}})$$$ complexity and there are $$$o(\log(\mathbf{G}))$$$ prime factors. Therefore the total time complexity is $$$O(\sqrt{\mathbf{G}})$$$.
Analysis — C. Rock Paper Scissors
Test Set 1
We could observe that it is easy to calculate the expected value of a certain strategy by iterating
through all the choices you make every day and adjust your friend's probabilities of picking different
choices accordingly. Therefore, we could start from some naive strategy to maximize our chance of
winning, one strategy would be something like RSPRSPRSP$$$\dots$$$, and calculate its
expected value. If such
strategies cannot reach our expected bonus value, we could try to create a random strategy instead,
calculate its expected value of bonus, and do so repeatedly until we find a strategy of which the
expected bonus is at least $$$\mathbf{X}$$$. This approach is enough to solve the first test set.
Test Set 2
For the second test set, since the maximum value of $$$\mathbf{X}$$$ is raised, the method for Test Set 1 will exceed the time limit. Therefore we should find a more efficient way to look for a better strategy other than randomly generating them. We could first utilize what we have tried in the first test set, generating some random strategies, and pick the one with the best expected bonus as our base strategy $$$S$$$. We then randomly pick a day in $$$S$$$, and try to change the decision of that day and get a new strategy $$$S'$$$. If the expected bonus of the new strategy $$$E($$$S'$$$)$$$ is higher than that of the original $$$E($$$S$$$)$$$, we could substitute $$$S$$$ with $$$S'$$$ as our best strategy. By keep performing this substitution process, it is obvious the expected value of our strategy will be either increasing or reach a local maximum. Thus we could utilize this method, also known as hill climbing, to find a strategy which has an expected value larger than $$$\mathbf{X}$$$. Note that since what we find here is a local maximum, it is possible that we would eventually find out that the best stratgy derived from $$$S$$$ cannot reach the value of $$$\mathbf{X}$$$. In that case we have to reselect the initial $$$S$$$ and perform another substitutiton process.
Test Set 3
For the last test set, the methods we applied in the previous test sets could not find us a strategy in the given time limit. However we could try to solve the problem in a different angle. In this problem, we are targeting an expected bonus of $$$\mathbf{X}$$$. To simplify the problem, instead of finding a strategy to reach the targeted bonus, we can try to maximize the expected value we could get by using the best possible strategy we could have. This value will always be at least as large as $$$\mathbf{X}$$$ because the solution is guaranteed to exist in the problem statement. We could then use dynamic programming to solve this problem.
Let $$$v[r][p][s]$$$ denote the maximum expected value you could get if you made exactly $$$r$$$ rocks, $$$p$$$ papers, and $$$s$$$ scissors in you strategy on the $$$N$$$-th day. We could first observe $$$r + p + s = N$$$, and that this value will be affected by the last decision you made in your strategy. For example, if you decide to choose rock on the last day, the expected value will be
$$$v[r - 1][p][s] + \frac{p}{n - 1} \times \mathbf{W} + \frac{s}{n - 1} \times \mathbf{E}$$$.
Similarly, this can be applied to choosing paper or scissors as the last decision. Thus we could conclude that
We could do some brief analysis on the time and space complexity here. Notice that since in our dynamic programming process, if we want to find the optimal strategy for the $$$N$$$-th day, we will need to calculate all the states where $$$i + j + k \leq N$$$, which means that the space we are using will be $$$O(\binom{N}{3}) = O(N^3)$$$. As for the time complexity, since our transformation is constant, the dynamic programming process will be $$$O(\binom{N}{3}) = O(N^3)$$$. In our problem, where $$$N = 60$$$, such complexity is sufficient for our solution to find out the strategy in the given time limit.
Analysis — D. Binary Operator
For each expression, we could
construct an expression tree for it and consider it as an
arthimetric tree,
with, +, *, # as its operators.
We can then start trying to reduce the whole tree so that we could compare different expressions
more easily.
Test Set 1
In the first test set, for each expression we could first examine if there is a # in it. If not,
a simple traversal through the arthimetric tree would give us the value represented by the equation.
Otherwise, we could start from the node where the operator is #. We can reduce this
node's left and right subtrees into a single node each by traversing each subtree and calculating
its value accordingly. This will result in a subtree with leaf values $$$L$$$ and $$$R$$$,
and root # (i.e. $$$L$$$#$$$R$$$ in expression form). Now we have a
tree where there are only leaf nodes under the single #,
the next step will be trying to process node #'s ancestors, and ultimately we want to
reduce the whole expression into a general form of ($$$A$$$#$$$B$$$)*$$$C$$$+$$$D$$$ in order to do further
categorization. For simplicity we would denote $$$L$$$#$$$R$$$ as $$$X$$$ from now on.
We would start try to transform the expression into our desired form from the subtree where $$$X$$$
is the left leaf. Specifically we want to
Consider $$$X$$$'s sibling tree, since there is no # in that tree, we could use the
same traversal method to get its value $$$S$$$. Now consider the parent node of $$$X$$$:
- $$$X$$$'s parent is a
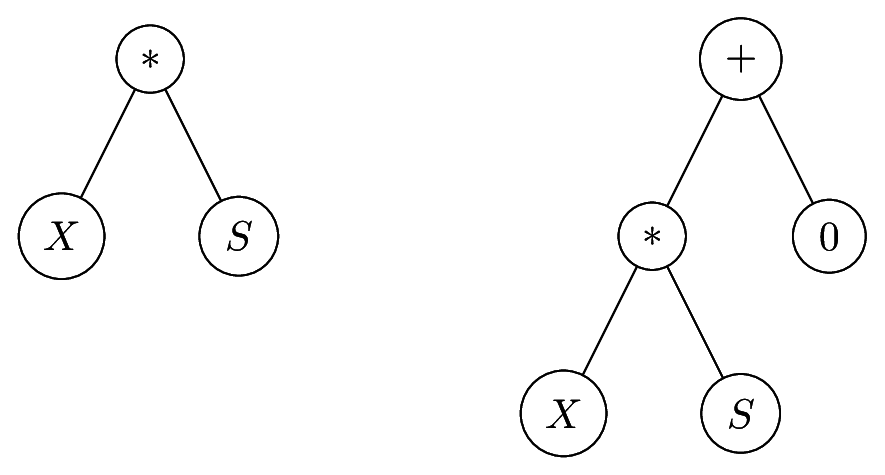
+, or $$$X$$$ is the root node: we would reconstruct $$$X$$$ into a subtree, where its root node is a $$$*$$$, and its left node being $$$X$$$, and right node being $$$1$$$. - $$$X$$$'s parent is a
*: in this case, we added a $$$+$$$ node as a new parent, and the value $$$0$$$ as the new right-sibling $$$S_p$$$.

- the node is a
+, or there is no such node: we could reduce the height of the tree by replacing the tree with its left subtree, and substitute the value of its right subtree from $$$S_p$$$ to $$$S_p + S_p'$$$ - the node is a
*: samely, we would reduce the subtree with its left subtree, but this time we substitute the value of its right subtree with $$$S_p * S_p'$$$, and also replace $$$X$$$'s sibling with $$$S * S_p'$$$
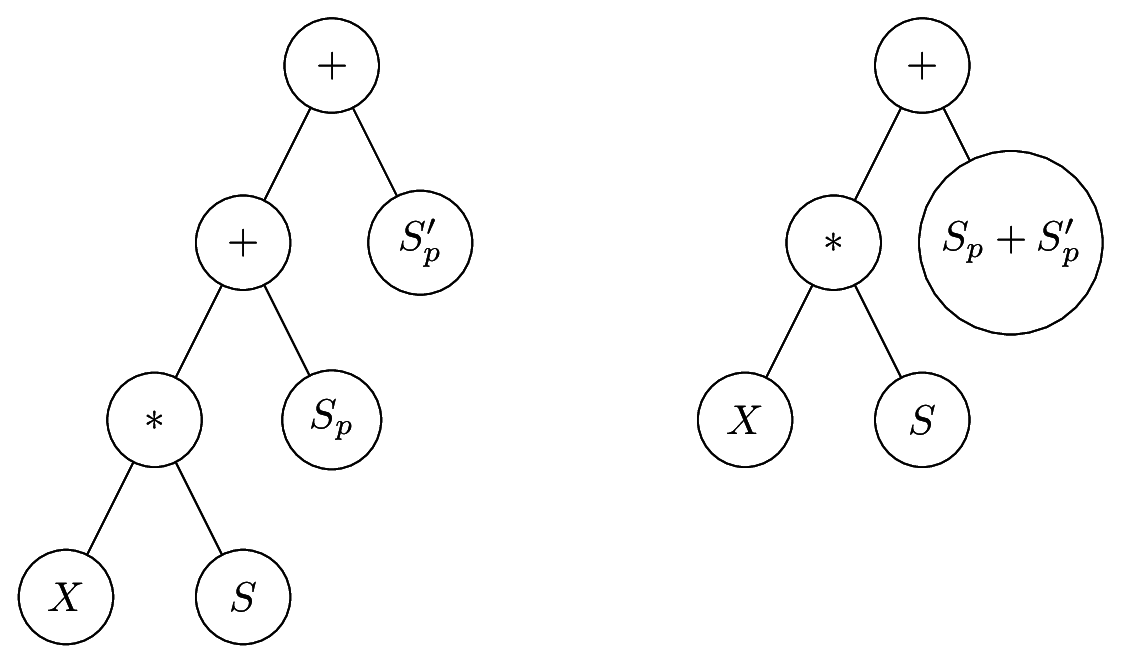
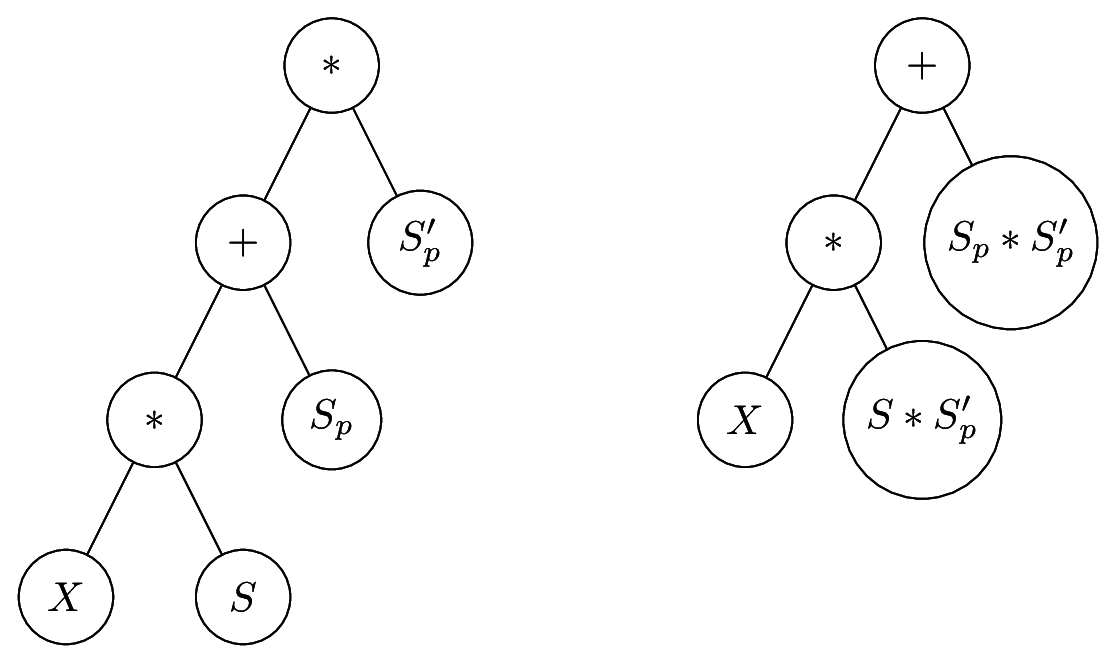
($$$A$$$#$$$B$$$)*$$$C$$$+$$$D$$$,
where $$$A, B, C, D$$$ are all integers. Therefore the expression can
be represented by a 4-tuple $$$(A, B, C, D)$$$. We can then use a hashtable or any similar data structure
to categorize them into different equilavence classes. Note that when $$$C = 0$$$, the only comparator matters
here will be $$$D$$$ only, since any value of $$$A$$$#$$$B$$$ does not affect the value at all.
Test Set 2
For the second test set, we could follow the similar solution as mentioned above: reduce the
expressions, then categorized into different classes. However, this method would become much more
complicated since there might be more than one # in each expression. As a result, we
cannot represent each expression as a 4-tuple, and the reduction rules are much more complicated.
In fact, consider the following expression (not fully parenthesized for the sake of simplicity):
((0#1)+1)*((0#2)+1)*((0#3)+1)*$$$\dots$$$
((0#1)+1) already takes $$$9$$$ characters per block,
and there is also need to spend additional characters on enclosing brackets and operators, the total number
of coefficients for any given input string will be small enough to allow such deterministic solution to pass.
Alternative solution
There is also a simpler nondeterministic approach to this problem. Since the operator #
represents a total function, for each calculation of some $$$X$$$#$$$Y$$$, we could randomly assign a
value as the result, and memorize it for further calculation of the same $$$X$$$#$$$Y$$$.
We could utilize it to calculate the exact value of an expression, then state that two expressions
belong to the same equivalence class if their corresponding values are the same. This process will never put two
expressions from the same class into different classes, but may result in a collision that mistakenly puts two
expressions from different classes into the same class. Unfortunately, we do not have a simple proof that such solution has
sufficiently small probability of failure. To further decrease the probability of false matches, the
process can be repeated several times, putting two expressions into the same class only if their evaluations matched every time.