Google Kick Start Archive — Round C 2020 problems
Overview
Thank you for participating in Kick Start 2020 Round C.
Cast
Countdown: Written by Kevin Tran and prepared by Jonathan Irvin Gunawan.
Stable Wall: Written by Chan Min Kim and prepared by Seunghyun Jo.
Perfect Subarray: Written by Himanshu Jaju and prepared by Sherry Wu.
Candies: Written by Bartosz Kostka and prepared by Jonathan Irvin Gunawan.
Solutions, other problem preparation, reviews and contest monitoring by Akul Siddalingaswamy, Anson Ho, Bohdan Pryshchenko, Cristhian Bonilha, Diksha Saxena, Giovanni Pezzino, Jared Gillespie, Jonathan Irvin Gunawan, Kashish Bansal, Kevin Tran, Krists Boitmanis, Lalit Kundu, Lizzie Sapiro, Michał Łowicki, Naranbayar Uuganbayar, Nikhil Hassija, Mohamed Yosri Ahmed, Ruoyu Zhang, Sadia Atique, Sadlil Rhythom, Sanyam Garg, Saurabh Joshi, Seunghyun Jo, Sherry Wu, Raihat Zaman Neloy, Sudarsan Srinivasan, Swante Scholz, Swapnil Gupta, Vikash Dubey, and Vipin Singh.
Analysis authors:
- Countdown: Jonathan Irvin Gunawan
- Stable Wall: Sadia Atique
- Perfect Subarray: Akul Siddalingaswamy
- Candies: Krists Boitmanis
A. Countdown
Problem
Avery has an array of N positive integers. The i-th integer of the array is Ai.
A contiguous subarray is an m-countdown if it is of
length m and contains the integers m, m-1, m-2, ..., 2, 1 in that order.
For example, [3, 2, 1] is a 3-countdown.
Can you help Avery count the number of K-countdowns in her array?
Input
The first line of the input gives the number of test cases, T. T test cases follow. Each test case begins with a line containing the integers N and K. The second line contains N integers. The i-th integer is Ai.
Output
For each test case, output one line containing Case #x: y, where x is the test case number (starting from 1) and y is
the number of K-countdowns in her array.
Limits
Time limit: 20 seconds.
Memory limit: 1 GB.
1 ≤ T ≤ 100.
2 ≤ K ≤ N.
1 ≤ Ai ≤ 2 × 105, for all i.
Test Set 1
2 ≤ N ≤ 1000.
Test Set 2
2 ≤ N ≤ 2 × 105 for at most 10 test cases.
For the remaining cases, 2 ≤ N ≤ 1000.
Sample
3 12 3 1 2 3 7 9 3 2 1 8 3 2 1 4 2 101 100 99 98 9 6 100 7 6 5 4 3 2 1 100
Case #1: 2 Case #2: 0 Case #3: 1
In sample case #1, there are two 3-countdowns as highlighted below.
- 1 2 3 7 9 3 2 1 8 3 2 1
- 1 2 3 7 9 3 2 1 8 3 2 1
In sample case #2, there are no 2-countdowns.
In sample case #3, there is one 6-countdown as highlighted below.
- 100 7 6 5 4 3 2 1 100
B. Stable Wall
Problem
Apollo is playing a game involving A to Z.
Apollo has finished the game and created a rectangular wall containing R rows and C columns. He took a picture and sent it to his friend Selene. Selene likes pictures of walls, but she likes them even more if they are stable walls. A wall is stable if it can be created by adding polyominos one at a time to the wall so that each polyomino is always supported. A polyomino is supported if each of its squares is either on the ground, or has another square below it.
Apollo would like to check if his wall is stable and if it is, prove that fact to Selene by telling her the order in which he added the polyominos.
Input
The first line of the input gives the number of test cases, T. T test cases follow.
Each test case begins with a line containing the two integers R and C.
Then, R lines follow, describing the wall from top to bottom.
Each line contains a string of C uppercase characters from A to Z, describing
that row of the wall.
Output
For each test case, output one line containing Case #x: y, where x is the test case number (starting from 1) and y is
a string of N uppercase characters, describing the order in which he built them.
If there is more than one such order, output any of them.
If the wall is not stable, output -1 instead.
Limits
Time limit: 20 seconds.
Memory limit: 1 GB.
1 ≤ T ≤ 100.
1 ≤ R ≤ 30.
1 ≤ C ≤ 30.
No two polyominos will be labeled with the same letter.
The input is guaranteed to be valid according to the rules described in the statement.
Test Set 1
1 ≤ N ≤ 5.
Test Set 2
1 ≤ N ≤ 26.
Sample
4 4 6 ZOAAMM ZOAOMM ZOOOOM ZZZZOM 4 4 XXOO XFFO XFXO XXXO 5 3 XXX XPX XXX XJX XXX 3 10 AAABBCCDDE AABBCCDDEE AABBCCDDEE
Case #1: ZOAM Case #2: -1 Case #3: -1 Case #4: EDCBA
In sample case #1, note that ZOMA is another possible answer.
In sample case #2 and sample case #3, the wall is not stable, so the answer is -1.
In sample case #4, the only possible answer is EDCBA.
C. Perfect Subarray
Problem
Cristobal has an array of N (possibly negative) integers. The i-th integer in his array is Ai. A contiguous non-empty subarray of Cristobal's array is perfect if its total sum is a perfect square. A perfect square is a number that is the product of a non-negative integer with itself. For example, the first five perfect squares are 0, 1, 4, 9 and 16.
How many subarrays are perfect? Two subarrays are different if they start or end at different indices in the array, even if the subarrays contain the same values in the same order.
Input
The first line of the input gives the number of test cases, T. T test cases follow. The first line of each test case contains the integer N. The second line contains N integers describing Cristobal's array. The i-th integer is Ai.
Output
For each test case, output one line containing Case #x: y, where x is the test case number (starting from 1) and y is
the number of perfect subarrays.
Limits
Memory limit: 1 GB.
1 ≤ T ≤ 100.
-100 ≤ Ai ≤ 100, for all i.
Test Set 1
Time limit: 20 seconds.
1 ≤ N ≤ 1000.
Test Set 2
Time limit: 30 seconds.
For up to 5 cases, 1 ≤ N ≤ 105.
For the remaining cases, 1 ≤ N ≤ 1000.
Sample
3 3 2 2 6 5 30 30 9 1 30 4 4 0 0 16
Case #1: 1 Case #2: 3 Case #3: 9
In sample case #1, there is one perfect subarray: [2 2] whose sum is 22.
In sample case #2, there are three perfect subarrays:
[9], whose total sum is 32.[1], whose total sum is 12.[30 30 9 1 30], whose total sum is 102.
In sample case #3, there are nine perfect subarrays:
[4], whose total sum is 22.[4 0], whose total sum is 22.[4 0 0], whose total sum is 22.[0], whose total sum is 02.[0 0], whose total sum is 02.[0 0 16], whose total sum is 42.[0], whose total sum is 02.[0 16], whose total sum is 42.[16], whose total sum is 42.
Note: We do not recommend using interpreted/slower languages for the test set 2 of this problem.
D. Candies
Problem
Carl has an array of N candies. The i-th element of the array (indexed starting from 1) is Ai representing sweetness value of the i-th candy. He would like to perform a series of Q operations. There are two types of operation:
- Update the sweetness value of a candy in the array.
- Query the sweetness score of a subarray.
The sweetness score of a subarray from index l to r is: Al × 1 - Al+1 × 2 + Al+2 × 3 - Al+3 × 4 + Al+4 × 5 ...
More formally, the sweetness score is the sum of (-1)i-lAi × (i - l + 1), for all i from l to r inclusive.
For example, the sweetness score of:
- [3, 1, 6] is 3 × 1 - 1 × 2 + 6 × 3 = 19
- [40, 30, 20, 10] is 40 × 1 - 30 × 2 + 20 × 3 - 10 × 4 = 0
- [2, 100] is 2 × 1 - 100 × 2 = -198
Carl is interested in finding out the total sum of sweetness scores of all queries. If there is no query operation, the sum is considered to be 0. Can you help Carl find the sum?
Input
The first line of the input gives the number of test cases, T. T test cases follow.
Each test case begins with a line containing N and Q.
The second line contains N integers describing the array. The i-th integer is Ai.
The j-th of the following Q lines describe the j-th operation.
Each line begins with a single character describing the type of operation (U for update, Q for query).
- For an update operation, two integers Xj and Vj follow, indicating that the Xj-th element of the array is changed to Vj.
- For a query operation, two integers Lj and Rj follow, querying the sweetness score of the subarray from the Lj-th element to the Rj-th element (inclusive).
Output
For each test case, output one line containing Case #x: y, where x is the test case number (starting from 1) and y is
the total sum of sweetness scores of all the queries.
Limits
Time limit: 20 seconds.
Memory limit: 1 GB.
1 ≤ T ≤ 100.
1 ≤ Ai ≤ 100, for all i.
1 ≤ N ≤ 2 × 105 and
1 ≤ Q ≤ 105 for at most 6 test cases.
For the remaining cases, 1 ≤ N ≤ 300 and
1 ≤ Q ≤ 300.
If the j-th operation is an update operation, 1 ≤ Xj ≤ N and 1 ≤ Vj ≤ 100.
If the j-th operation is a query operation, 1 ≤ Lj ≤ Rj ≤ N.
Test Set 1
There will be at most 5 update operations.
Test Set 2
There are no special constraints.
Sample
2 5 4 1 3 9 8 2 Q 2 4 Q 5 5 U 2 10 Q 1 2 3 3 4 5 5 U 1 2 U 1 7 Q 1 2
Case #1: -8 Case #2: -3
In sample case #1:
- The first query asks for the sweetness score of [3, 9, 8] which is 3 × 1 - 9 × 2 + 8 × 3 = 9.
- The second query asks for the sweetness score of [2] which is 2 × 1 = 2.
- The third query asks for the sweetness score of [1, 10] which is 1 × 1 - 10 × 2 = -19.
In sample case #2:
- The first and only query asks for the sweetness score of [7, 5] which is 7 × 1 - 5 × 2 = -3.
Analysis — A. Countdown
Test Set 1
For each element Ai, we can check whether it is a start of a K-countdown. In other words, we check whether Ai + j = K - j for all 0 ≤ j ≤ K. If the element Ai satisfies the condition, we can can increment our answer counter by 1. This solution runs in O(N × K).
Test Set 2
To solve this test set, we can loop through the elements and keep track of the number of consecutive elements such that the next element is one less than the previous element. We can do this by keeping a counter. If the current element is one less than the previous element, we increment this counter by 1. Otherwise, we reset the counter to 0. If the current element is 1 and our counter is at least K - 1, we know that the current element is the end of a K-countdown. We can increment our answer counter by 1 in this case.
This approach works since any pair of K-countdown subarrays does not overlap. This solution runs in O(N).
Pseudocode
answer_counter = 0
decreasing_counter = 0
for (i = 1 to N - 1) {
if (A[i] == A[i - 1] - 1) {
decreasing_counter = decreasing_counter + 1
} else {
decreasing_counter = 0
}
if (A[i] == 1 and decreasing_counter >= K - 1) {
answer_counter = answer_counter + 1
}
}
print answer_counter
Analysis — B. Stable Wall
Test set 1
Each of the polyominos contains only one letter. We can take each of the permutations of the distinct letters, and check if the resulting wall is stable by following the order of the letters in the permutation to place the polyominos, one by one. There are N distinct letters in the input, so we will have N! permutations.
Let's say W is the given input wall letters. There are various ways to check if a wall is stable for a given permutation. One way is to create a new 2D array of integers, I. I[i][j] will contain the index of the letter W[i][j] in the permutation. Each of the letters at(i, j) in the wall must be placed after the letter below them, i.e. at(i+1, j), if they are not part of the same polyomino. We can check if it's true by checking if I[i][j] ≥ I[i+1][j], for all positions (i, j). Since I contains relative indexing of the order of the polyominos that were placed, this check works as intended. We can check this in O(R × C) time, so the runtime complexity of this approach for each test case is O(N! × R × C). This is sufficient for test set 1.
Test set 2
Given the picture of the wall, if two polyominos are positioned one above another, and they touch each other, then to make a stable wall, the bottom one must be placed before the top one. This gives us a set of orderings of pairs of letters which must be followed while placing the polyominos.
We can make a graph with the set of orderings just mentioned. Each polyomino/letter can be considered as a vertex, and each of the orderings can be considered as a directed edge of the graph. If the resulting graph contains any cycle, it is not possible to have a stable wall. Otherwise, we can use topological sort to find a suitable order that fulfills all the orderings. We can find all the orderings in O(R × C) time. We can find a topological sorting of the vertices of a directed acyclic graph by using depth first search. Depth first search gives us a runtime complexity of O(number of edges + number of vertices). The number of edges in the graph is at most (R-1) × C, as each cell of the grid adds at most one edge, to the cell right above it. So the total runtime complexity of this approach for each test case is O(R × C) + O(N + R × C) = O(R × C), since N can be at most R × C. This is sufficient for test set 2.
Analysis — C. Perfect Subarray
For test set 1, we can use the brute force approach to generate all subarray sums, check if each one is a square and return the total count. This would be enough to pass all the test cases under the time complexity.
For test set 2, looking at the problem constraints, we can estabilish that the largest subarray sum possible across all testcases would be N*MAX_A where MAX_A is the largest element in A. Therefore, we can precompute all squares ≤ N*MAX_A. This amounts to √(N*MAX_A) squares. Let's call this S[].
First, let's define Res[] where Resi stores the number of subarrays ending at index i
with subarray sum that is a perfect square.
Note: sum(A[L....R]) = sum(A[0.....R]) - sum(A[0....L-1]) for
0 < L ≤ R ≤ N..
Next, define an array P[] that keeps count of the number of indices i such that A[0...i]
amount to a specific prefix_sum. i.e., P[prefix_sum] should give us the number of indices i such that
sum(A[0...i])=prefix_sum. However, we could have negative prefix_sum values and hence
P[prefix_sum] could be an invalid lookup. To resolve this, instead of mapping a prefix_sum to
P[prefix_sum], we map it to P[prefix_sum + offset], where offset = min(sum(A[0.....i]), 0)*-1
for 0 ≤ i < N. i.e., The minimum among the N+1 (+1 for the empty prefix)
prefix_sum values possible which can be computed with a single pass over A.
Note that the offset is at least 0.
Next, we iterate the A left to right, while maintaining the sum of elements seen so
far - let's call that prefix_sum. Now, at every i-th index, we ask the question,
How many subarrays end at i and have the subarray sum which is also a square?
To answer this, we iterate S[] and for each square Sk, we add
P[(prefix_sum-Sk) + offset] to Res[i]. Why so? - P is built as we iterate
A and hence, at a certain index i, P holds the mapping of {prefix_sum, count}
where count is the number of indices j (< i) such that sum(A[0....j])=prefix_sum. Therefore,
P[(prefix_sum-Sk) + offset] holds the number of indices such that sum(A[j...i])=Sk.
We also increment the count of P[prefix_sum+offset] by 1 to record that
sum(A[0....i])=prefix_sum. Finally, summing up all values Res[] would give us our answer.
Since we traverse A once, iterate S[] for every index i and lookup in P[] is O(1), the total time complexity for this solution is O(N*√(N*MAX_A)).
Appendix
A subtle observation and a potential improvement is to early exit on iteration of S[] at every stage. As mentioned earlier, we check P[(prefix_sum-Sk) + offset] and notice that at some point (prefix_sum-Sk) + offset could become < 0 which indicates not only that accessing P would be invalid, but also that Sk is too large to be obtained from all elements upto the current index i. We can use this criteria as a way to early exit the iteration on S[]. The asymptotic time complexity would remain the same, but would be slightly faster in run-time.
Next, instead of using an array with an offset for lookup of prefix sums , we could use a normal map, which would remove the need of an offset, but adds the cost of lookup that would take logarithmic time instead of the O(1). This solution may also be accepted if written efficiently and the time comoplexity would be O(N*log(N)*√(N*MAX_A)).
Analysis — D. Candies
Let us ignore the update operations for now and look at how we can answer the queries efficiently. Take the array A = [5, 2, 7, 4, 6, 3, 9, 1, 8] as an example. The sweetness score for the query (1, 9) from l = 1 to r = 9 is intuitively visualized in the following diagram.
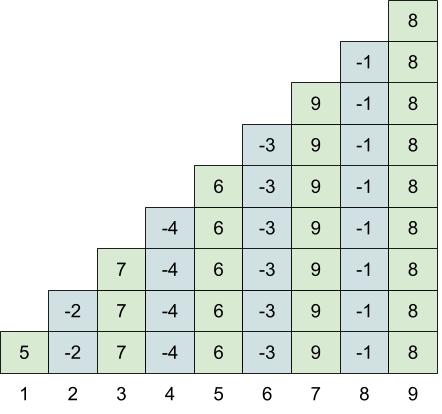
The i-th element (-1)i-1Ai × i of the sweetness score sum is represented as a stack of i blocks in the i-th column of the diagram. The values in every other column are negated to account for the sign in the sweetness score sum. Obviously, the sum of all squares in the diagram is the sweetness score of the query (1, 9).
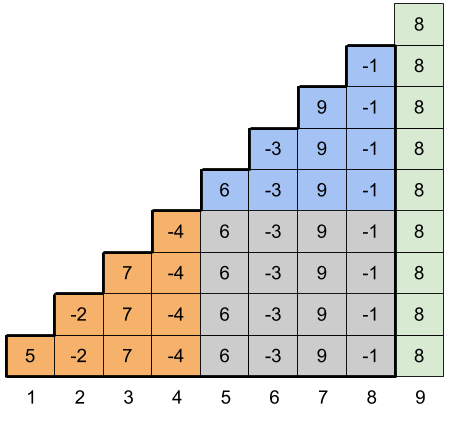
A crucial observation is that the sweetness scores for all other queries are embedded in the diagram as well. For example, the query (5, 8) corresponds to the blue shaded blocks in the diagram below, and the sweetness score of (5, 8) can be conveniently computed as the sum of all blocks inside the area with the bold outline minus the sum of orange and gray blocks. Note, however, that for queries (l, r) with even left endpoint l, we should take the additive inverse of the value computed this way to obtain the correct sweetness score.
Test Set 1
The above observations suggest a solution using prefix sums. Let us define the
regular prefix sums S(i) as S(0) = 0 and
S(i) = (-1)i-1Ai + S(i - 1) for i ≥ 1. Similarly, let us define
the multiple prefix sums MS(i) as MS(0) = 0 and
MS(i) = (-1)i-1Ai × i + MS(i - 1) for i ≥ 1. Then the sweetness
score of a query (l, r) is
(-1)l-1(MS(r) - MS(l - 1) - (l - 1) × (S(r) - S(l - 1))).
Computing the prefix sums takes O(N) time, and once we have them, each query can be answered in constant time. Therefore, the overall time complexity of the algorithm is O(N + Q).
So far we have disregarded the update operations, however, since there are no more than 5 of them, we can recompute the prefix sums after each update operation without increasing the time complexity.
Test Set 2
Here the number of update operations is unlimited, and the time complexity of the previous algorithm becomes O(NQ), which is inefficient. However, we can still use very much the same idea by maintaining two segment trees – a tree T for storing the values (-1)i-1Ai and another tree MT for storing the values (-1)i-1Ai × i. Then the answer to a query (l, r) becomes (-1)l-1(MT.rangeSum(l, r) - (l - 1) × T.rangeSum(l, r)).
Since updates and range queries in a segment tree take O(log N) time, the overall time complexity of the algorithm is O(N + Q log N).