Google Code Jam Archive — Round 1C 2022 problems
Overview
Round 1C started with Letter Blocks which had contestants trying to stack towers of blocks into one megatower while adhearing to certain guidelines. Next, Squary tested contestants' mathematical skills as they tried to make a list of numbers "squary". Finally, Intranets truly put contestants to the test and had an extremely hard Test Set 2 asking for the probability that a network using a suboptimal routing algorithm would be broken up into a certain number of sub-networks.
The first perfect score took just over an hour, which was longer than both of the other Round 1s. This gave Laurie666 first place in the round. VArtem and square1001 came in second and third place, respectively. Ultimately, 8 coders managed a perfect score. The unofficial cutoff to advance to Round 2 is 34 points.
This wraps up our Round 1s for the year. We'll finalize the results in the coming days. In the meantime, you can keep improving your skills by practicing on this round's or any past round's problems in the archive.
If you placed in the top 1500, we will see you again in about 2 weeks as you join 3000 participants coming from the other Round 1s to compete in Round 2. Don't forget to check your local time in the schedule page. If you didn't earn enough points to advance, we hope you had a wonderful time with our first 14 problems of the year. You are invited to follow along for the rest of the season, and we hope to see you again next year!
Cast
Letter Blocks: Written and prepared by Yeabkal Wubshit.
Squary: Written by Onufry Wojtaszczyk. Prepared by Petr Mitrichev and Swapnil Gupta.
Intranets: Written by Yui Hosaka. Prepared by Mahmoud Ezzat.
Solutions and other problem preparation and review by Abhilash Tayade, Aditya Mishra, Akul Siddalingaswamy, Anushi Maheshwari, Arjun Sanjeev, Chu-ling Ko, Hsin-Yi Wang, Ian Tullis, Ikumi Hide, Liang Bai, Mahmoud Ezzat, Md Mahbubul Hasan, Mohammad Abu Aboud, Nour Yosri, Pablo Heiber, Priyam Khandelwal, Ritesh Kumar, Shantam Agarwal, Timothy Buzzelli, Ulises Mendez Martinez, Yan Li, Yang Xiao, Yeabkal Wubshit, and Yui Hosaka.
Analysis authors:
- Letter Blocks: Jakub Kuczkowiak.
- Squary: Arjun Sanjeev.
- Intranets: Dafeng Xu and Yui Hosaka.
A. Letter Blocks
Problem
It is a rainy day, so you are indoors building towers of letter blocks. A letter block is a wooden cube that has a letter printed on one of its sides. The font used for the letters makes the blocks have a clear orientation: that is, there is only one side that can be pointed down (toward the floor) and one side that can be pointed up (toward the ceiling).
You have built multiple separate towers so far. Now you want to combine all of them into a single megatower by choosing one of your towers as the base, then picking up another tower (without changing the order of its blocks) and stacking the whole thing on top of that, and so on, until all towers have been used.
As an additional constraint for the megatower, for any two blocks that have the same letter, all blocks between them must also have that letter. That is, each letter of the alphabet that appears in the megatower needs to appear in one contiguous group (of one or more blocks).
For example, consider the following three possible megatowers. (These are separate examples, not built from the same original towers. Also note that the different block sizes are just for fun and are not part of the problem.)
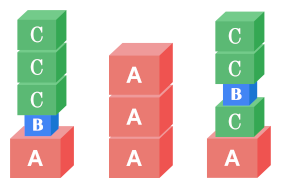
The leftmost two megatowers are valid, since each letter appears in a contiguous group. However,
the rightmost megatower is not valid, because there is a B in between two
Cs.
Given the towers that you have built so far, can you stack them all up into a valid megatower?
Input
The first line of the input gives the number of test cases, $$$\mathbf{T}$$$. $$$\mathbf{T}$$$ test cases follow. Each test case is described by two lines. The first line consists of a single integer $$$\mathbf{N}$$$, the number of towers that are currently built. The second line consists of $$$\mathbf{N}$$$ strings $$$\mathbf{S_1}, \mathbf{S_2}, \dots, \mathbf{S_N}$$$ representing the towers. Each of these strings consists of only uppercase letters. The $$$i$$$-th letter of each of these strings is the letter on the $$$i$$$-th block from the bottom in the represented tower.
Output
For each test case, output one line containing Case #$$$x$$$: $$$y$$$,
where $$$x$$$ is the test case number (starting from 1) and $$$y$$$ is a string representing a
valid megatower as described above, or the word IMPOSSIBLE if no valid megatower
can be built. (Notice that the string IMPOSSIBLE can never itself represent a valid
megatower, since the two Is have other letters in between.)
Limits
Time limit: 5 seconds.
Memory limit: 1 GB.
$$$1 \le \mathbf{T} \le 100$$$.
$$$1 \le $$$ the length of $$$\mathbf{S_i} \le 10$$$, for all $$$i$$$.
Test Set 1 (Visible Verdict)
$$$2 \le \mathbf{N} \le 6$$$.
Test Set 2 (Visible Verdict)
$$$2 \le \mathbf{N} \le 100$$$.
Sample
6 5 CODE JAM MIC EEL ZZZZZ 6 CODE JAM MIC EEL ZZZZZ EEK 2 OY YO 2 HASH CODE 6 A AA BB A BA BB 2 CAT TAX
Case #1: ZZZZZJAMMICCODEEEL Case #2: IMPOSSIBLE Case #3: IMPOSSIBLE Case #4: IMPOSSIBLE Case #5: BBBBBAAAAA Case #6: IMPOSSIBLE
In Sample Case #1, JAMMICCODEEELZZZZZ and ZZZZZJAMMICCODEEEL are the
only two valid outputs.
In Sample Case #2, recall that all towers must be used in the megatower, so even though
the first five towers together would form a valid megatower (as in Sample Case #1), the
additional EEK makes the case impossible. No matter how the EEL and
EEK towers are stacked relative to each other, there will be at least two
non-contiguous groups of Es.
In Sample Case #3, no matter how you stack the towers, either the two Os are
not contiguous or the two Ys are not contiguous.
In Sample Case #4, there are non-H letters in between the Hs of
HASH, so this case is also impossible.
In Sample Case #5, this answer is the only valid one. Also notice that the towers are not necessarily all distinct.
In Sample Case #6, no matter how you stack the towers, the two As cannot
be contiguous.
B. Squary
Problem
Addition and squaring do not commute. That is, the square of the sum of all elements of a list of integers is not necessarily equal to the sum of the squares of those same elements. However, this is true for some lists; one example is $$$[3, -2, 6]$$$, because $$$(3 + (-2) + 6)^2 = 49 = 3^2 + (-2)^2 + 6^2$$$. Let us call these lists squary.
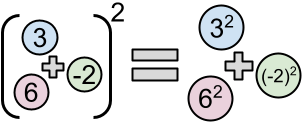
Given a (not necessarily squary) list of relatively small integers, we want to know whether it is possible to add at least $$$1$$$ and at most $$$\mathbf{K}$$$ more elements such that the final list is squary. Each added element must be an integer between $$$-10^{18}$$$ and $$$10^{18}$$$, inclusive, and these do not have to be distinct from each other or from the initial list's elements.
Input
The first line of the input gives the number of test cases, $$$\mathbf{T}$$$. $$$\mathbf{T}$$$ test cases follow. Each test case is described in two lines. The first line contains two integers $$$\mathbf{N}$$$ and $$$\mathbf{K}$$$, the number of elements of the initial list and the maximum number of elements you may add, respectively. The second line contains $$$\mathbf{N}$$$ integers $$$\mathbf{E_1}, \mathbf{E_2}, \dots, \mathbf{E_N}$$$, representing the $$$\mathbf{N}$$$ elements of the initial list.
Output
For each test case, output one line containing Case #$$$x$$$: $$$y$$$,
where $$$x$$$ is the test case number (starting from 1). If it is possible to add at least $$$1$$$
and at most $$$\mathbf{K}$$$ elements (each an integer between $$$-10^{18}$$$ and $$$10^{18}$$$, inclusive) to
the initial list such that the square of the sum of its elements equals the sum of the squares of
its elements, $$$y$$$ should be $$$z_1~z_2~\dots~z_r$$$, where $$$1 \le r \le \mathbf{K}$$$ and the
$$$z_i$$$ values are the additional elements. If there is no way to accomplish this, $$$y$$$ should
be IMPOSSIBLE.
Limits
Memory limit: 1 GB.
$$$1 \le \mathbf{T} \le 100$$$.
$$$1 \le \mathbf{N} \le 1000$$$.
$$$-1000 \le \mathbf{E_i} \le 1000$$$, for all $$$i$$$.
Test Set 1 (Visible Verdict)
Time limit: 5 seconds.
$$$\mathbf{K} = 1$$$.
Test Set 2 (Visible Verdict)
Time limit: 10 seconds.
$$$2 \le \mathbf{K} \le 1000$$$.
Sample
Note: there are additional samples that are not run on submissions down below.4 2 1 -2 6 2 1 -10 10 1 1 0 3 1 2 -2 2
Case #1: 3 Case #2: IMPOSSIBLE Case #3: -1000000000000000000 Case #4: 2
In Sample Case #1, we can end up with the example list given in the problem statement.
In Sample Case #2, we have to add exactly one element. If we call that element $$$x$$$, the sum of the entire list is $$$x$$$ and its square is $$$x^2$$$. The sum of the squares of all elements, on the other hand, is $$$x^2 + 10^2 + (-10)^2 = x^2 + 200 \neq x^2$$$, so the case is impossible.
In Sample Case #3, any integer in the $$$[-10^{18}, 10^{18}]$$$ range is a valid answer.
In Sample Case #4, notice that the input might contain duplicate elements, and that it is valid to create even more duplicates with the elements you choose to add.
Additional Sample - Test Set 2
The following additional sample fits the limits of Test Set 2. It will not be run against your submitted solutions.3 3 10 -2 3 6 6 2 -2 2 1 -2 4 -1 1 12 -5
Case #1: 0 Case #2: -1 15 Case #3: 1 1 1 1 1 1 1 1 1 1 1
In Case #1 of the additional samples, we are given the example list from the problem statement, which is already squary, but we need to add at least one element to it. Adding a $$$0$$$ keeps the list squary.
In Case #3 of the additional samples, we present one of multiple possible valid answers. Notice that it is permissible to add fewer than $$$\mathbf{K}$$$ elements; here $$$\mathbf{K}$$$ is $$$12$$$ but we have only added $$$11$$$ elements.
C. Intranets
Problem
Apricot Rules LLC is developing a new simplified networking protocol and wants to show off their routing algorithm. In their design, a network consists of $$$\mathbf{M}$$$ machines numbered from $$$1$$$ to $$$\mathbf{M}$$$, and each pair of machines is connected by a direct link. Each of the links is given a unique integer priority value between $$$1$$$ and $$$(\mathbf{M} \times (\mathbf{M} - 1) / 2)$$$ and each machine routes traffic according to those priorities.
Unfortunately, the routing algorithm is too aggressive and will route all traffic from a machine through the highest priority link connected to it. This may make some groups of machines isolated from others.
Formally, we say that a machine $$$m$$$ uses a link $$$\ell$$$ if (and only if) $$$\ell$$$ is the highest priority link connected to $$$m$$$. We also say that a link is active if it is used by at least one of the two machines it connects. Given the link priorities, the original network becomes partitioned into disjoint intranets. Two machines belong to the same intranet if and only if there is some path between them using only active links.
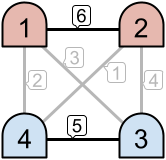
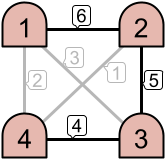
For example, as seen in the left image above, only the links with priorities $$$6$$$ and $$$5$$$ are active. This creates two disjoint intranets. However, in the example on the right, three links are active, which results in one intranet consisting of all $$$4$$$ machines.
As part of the quality assurance team at Apricot Rules LLC, you are investigating the extent of the problem. You are interested in knowing the probability of there being exactly $$$\mathbf{K}$$$ intranets if the priorities are assigned uniformly at random from among the $$$(\mathbf{M} \times (\mathbf{M} - 1) / 2)!$$$ ways of doing so.
Input
The first line of the input gives the number of test cases, $$$\mathbf{T}$$$. $$$\mathbf{T}$$$ test cases follow. Each test case is described in a single line containing two integers $$$\mathbf{M}$$$ and $$$\mathbf{K}$$$: the number of machines and the target number of intranets, respectively.
Output
For each test case, output one line containing Case #$$$x$$$: $$$y$$$,
where $$$x$$$ is the test case number (starting from 1) and $$$y$$$ is the sought probability
computed modulo the prime $$$10^9+7$$$ ($$$1000000007$$$), which is defined precisely as follows.
Represent the probability as as an irreducible fraction $$$p/q$$$ (with $$$p$$$ and $$$q$$$ being
non-negative integers that minimize $$$p+q$$$). Then, $$$y$$$ must equal
$$$p \cdot q^{-1} \bmod {10^9+7}$$$, where $$$q^{-1}$$$ is the
modular multiplicative inverse
of $$$q$$$ with respect to the modulus $$$10^9+7$$$. It can be shown that under the constraints of
this problem, such a number $$$y$$$ always exists and is unique.
Limits
Memory limit: 1 GB.
$$$1 \le \mathbf{T} \le 50$$$.
$$$1 \le \mathbf{K} \le \mathbf{M} / 2$$$.
Test Set 1 (Visible Verdict)
Time limit: 20 seconds.
$$$2 \le \mathbf{M} \le 50$$$.
Test Set 2 (Hidden Verdict)
Time limit: 60 seconds.
$$$2 \le \mathbf{M} \le 5 \times 10^5$$$.
Sample
3 5 2 5 1 6 3
Case #1: 428571432 Case #2: 571428576 Case #3: 47619048
In Sample Case #1, consider the following situation. Let's call $$$\mathbf{M} = 5$$$ machines $$$1, 2, 3, 4, 5$$$ and denote the link connecting machine $$$a$$$ and machine $$$b$$$ by $$$(a, b)$$$. Assume that the priorities of links $$$(1, 2), (1, 3), (1, 4), (1, 5), (2, 3), (2, 4), (2, 5), (3, 4), (3, 5), (4, 5)$$$ are $$$9, 8, 7, 6, 5, 4, 3, 2, 1, 10$$$, respectively. Then machines $$$1$$$ and $$$2$$$ use link $$$(1, 2)$$$, machine $$$3$$$ uses link $$$(1, 3)$$$, and machines $$$4$$$ and $$$5$$$ use link $$$(4, 5)$$$. Thus three links $$$(1, 2), (1, 3), (4, 5)$$$ are active, and there are two intranets $$$\{1, 2, 3\}$$$ and $$$\{4, 5\}$$$. Since $$$\mathbf{K} = 2$$$, this situation counts the answer.
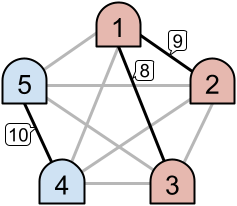
We can find that there are $$$1555200$$$ ways to assign the priorities to have exactly $$$2$$$ intranets among $$$10! = 3628800$$$ ways, so the probability is $$$3/7$$$.
In Sample Case #2, the probability is $$$4/7$$$.
In Sample Case #3, the probability is $$$1/21$$$.
Analysis — A. Letter Blocks
Let us first notice that this problem is equivalent to finding an order in which partial strings should be concatanted such that occurrences of the same letter appear together.
Test Set 1
Since $$$\mathbf{N}$$$ is at most $$$6$$$, the number of permutations of these strings is at most $$$6! = 720$$$.
We can therefore generate all permutations and for each of them we need to verify the final string which results of concatenating the input strings in that particular order.
Let us take a look at the string CCCABDAEEF. To verify the string it is enough to:
"CABDAEF"
If for at least one permutation the size matches, we can print out this string. Otherwise, it's impossible.
The time complexity of this solution is $$$O(\mathbf{N!}\times\sum_{i=1}^N |\mathbf{S_i}|)$$$, which means $$$\mathbf{N!}$$$ times the sum of the lengths of the input strings, because there are $$$\mathbf{N!}$$$ permutations and the verification of the final string takes linear time.
Test Set 2
In this test set $$$\mathbf{N}$$$ can be $$$100$$$, so $$$\mathbf{N!}$$$ is too large to enumerate all permutations.
First of all, we can verify that each of the strings $$$\mathbf{S_i}$$$ meets the requirements from the task.
This can be done by applying the verification method described in the section above for each $$$\mathbf{S_i}$$$
individually. If the verification fails for one of the input strings, then it will certainly fail
for any permutation of them and therefore we output IMPOSSIBLE.
Let us call middle letters all letters other than the first and last consecutive segment of letters. Next, let us notice that if the string $$$\mathbf{S_i}$$$ has more than $$$2$$$ distinct letters, then:
IMPOSSIBLE.
Since we also verified each string already, we know that each letter appears only in $$$1$$$ block inside each $$$\mathbf{S_i}$$$.
After this step the problem is now simplified into strings of two forms:
IMPOSSIBLE if $$$X_1 = X_2$$$
(due to $$$Y_1$$$) or $$$Y_1 = Y_2$$$ (due to $$$X_2$$$), because it means that in any ordering,
there would be at least one block of a different letter between letters $$$X_1$$$ and $$$Y_1$$$.
Therefore for each string $$$\mathbf{S_i}$$$, we can create the following mappings using sets:
IMPOSSIBLE.
Starting string
Let us consider starting string as the input string which is not forced by any previous strings in the final answer. When can the given string $$$\mathbf{S_i}$$$ be a starting string?
Extending the block
Let us consider we already built the partial answer $$$A$$$ which ends with letter $$$c$$$. If there exists a string at $$$single[c]$$$, it is the last chance to append it, because otherwise it would be separated by at least one block of another letter. Similarly, if there exists a string at $$$starts[c]$$$, we must extend it now for the same reason.
How to choose the starting string?
It turns out that for starting a new block, we can choose an arbitrary candidate from the candidates set.
$$$Proof$$$: Let us assume that we picked string $$$\mathbf{S_i}$$$ as the starting string but the optimal solution started the block with $$$\mathbf{S_j}$$$. Let us consider the swapped optimal solution in which we swap these blocks.
Let $$$\mathbf{S_i}$$$ start with letter $$$a$$$ and $$$\mathbf{S_j}$$$ with letter $$$b$$$. Then:
Let us consider what happens after swapping:
Final solution
Repeat:
IMPOSSIBLE.
Time complexity: $$$O(\mathbf{N}\times\sum_{i=1}^N |\mathbf{S_i}|)$$$, since we are touching each candidate only once.
Analysis — B. Squary
The multinomial expansion for the power of 2 is the key to solving this problem. The expansion of the square of the sum of elements $$$X_1, X_2, \ldots, X_n$$$ in the list $$$X$$$ looks like:
$$$$\begin{align} \text{square of sum} &= (X_1 + X_2 + X_3 + \ldots + X_N)^2 \\ &= X_1^2 + X_2^2 + X_3^2 + \ldots + X_N^2 + 2 \cdot X_1 \cdot X_2 + 2 \cdot X_2 \cdot X_3 + 2 \cdot X_1 \cdot X_3 + \ldots + 2 \cdot X_{N-1} \cdot X_N \\ &= \text{sum of squares} + 2 \cdot \text{sum of pairwise products} \end{align}$$$$
Let $$$S(X)$$$ be the sum of elements, $$$SQ(X)$$$ be the sum of squares of elements, and $$$SP(X)$$$ be the sum of all pairwise products of elements of the list $$$X$$$. We can now rewrite the above equation as:
$$$$ S(X)^2 = SQ(X) + 2 \cdot SP(X) $$$$
We can also observe the following about how the above values change when an additional element $$$n$$$ is added to the list $$$X$$$: $$$$\begin{align} S(X + [n]) &= S(X) + n \\ SQ(X + [n]) &= SQ(X) + n^2 \\ SP(X + [n]) &= SP(X) + n \cdot S(X) \end{align}$$$$
Our task is to achieve $$$S(E')^2 = SQ(E')$$$, where $$$E'$$$ is the extended list that we get by adding extra elements to $$$\mathbf{E}$$$. In other words, we want to make $$$SP(E') = 0$$$.
Test Set 1: $$$\mathbf{K} = 1$$$
If we are allowed only a single addition, we must choose an element $$$n$$$ such that $$$SP(\mathbf{E} + [n]) = 0$$$. $$$$\begin{align} SP(\mathbf{E} + [n]) = 0 \\ \implies SP(\mathbf{E}) + n \cdot S(\mathbf{E}) = 0 \\ \implies n \cdot S(\mathbf{E}) = -SP(\mathbf{E}) \end{align}$$$$ If $$$S(\mathbf{E}) \neq 0$$$, we can get a squary list whenever $$$-SP(\mathbf{E}) / S(\mathbf{E})$$$ is an integer, which happens if and only if $$$S(\mathbf{E})$$$ divides $$$SP(\mathbf{E})$$$. In that case, $$$-SP(\mathbf{E}) / S(\mathbf{E})$$$ is our answer.
If $$$S(\mathbf{E}) = 0$$$, then $$$S(\mathbf{E} + [n]) = n$$$. Since we want $$$S(\mathbf{E} + [n])^2 = SQ(\mathbf{E} + [n])$$$, we need $$$SQ(\mathbf{E} + [n]) = n^2$$$. This is possible only if $$$SQ(\mathbf{E}) = 0$$$, that is, if all elements in $$$\mathbf{E}$$$ are zeros. In this case, we can choose any value as our answer. But if any element in $$$\mathbf{E}$$$ is not zero, it is impossible to get a squary list with only one addition.
Test Set 2: $$$\mathbf{K} > 1$$$
At first, the search space might seem hopelessly broad here. But we can observe (or surmise and then confirm) that it is always possible to get a squary list by adding only two elements:
- $$$n_1 = 1 - S(\mathbf{E})$$$
- $$$n_2 = -SP(\mathbf{E} + [n_1])$$$
After adding $$$n_1$$$, we have $$$$\begin{align} S(\mathbf{E} + [n_1]) = 1 \end{align}$$$$ After adding $$$n_2$$$, we have $$$$\begin{align} SP(\mathbf{E} + [n_1, n_2]) &= SP(\mathbf{E} + [n_1]) + n_2 \cdot S(\mathbf{E} + [n_1]) \\ &= SP(\mathbf{E} + [n_1]) + (-SP(\mathbf{E} + [n_1])) \cdot 1 \\ &= 0 \end{align}$$$$ Thus, the two numbers satisfy the condition $$$SP(E') = 0$$$. We can also see that since the numbers in the original list are each of magnitude no greater than $$$10^3$$$, $$$|n_1| \leq 10^6 + 1$$$, and $$$|n_2| \leq 2 \cdot 10^{12}$$$, both well within the limits.
Analysis — C. Intranets
We use terminology for graphs. The vertices are the $$$\mathbf{M}$$$ machines and the edges are the $$$\binom{\mathbf{M}}{2}$$$ links.
Test Set 1
Let's consider the process of assigning priorities to the edges one by one, from the highest priority to the lowest. For simpicity, we number the $$$i$$$-th highest priority as priority $$$i$$$ so that the smaller the number, the higher the priority.
Suppose we have assigned the highest $$$i$$$ priorities to $$$i$$$ edges, and we need to assign the priority $$$(i+1)$$$ to a new edge. How can we do?
We have three types of choices. Suppose the new edge with the priority $$$(i+1)$$$ is $$$(u,v)$$$. Let $$$S_i$$$ be the set of vertices that the edges with highest $$$i$$$ priorities connect with.
- If the vertices $$$u$$$ and $$$v$$$ don't occur in the previously assigned edges. I.e. $$$u\notin S_i, v\notin S_i$$$, the number of such edges is $$$\binom{\mathbf{M}-|S_i|}{2}$$$. In this case, $$$u$$$ and $$$v$$$ form a new intranet. So, the number of intranets increase by $$$1$$$, and $$$|S_{i+1}|$$$ equals $$$|S_i|+2$$$.
- If $$$u\in S_i, v\notin S_i$$$, the number of such edges is $$$|S_i|\cdot (\mathbf{M}-|S_i|)$$$. In this case, $$$v$$$ joins the intranet in which $$$u$$$ is located. So, the number of intranets does not change, and $$$|S_{i+1}|$$$ equals $$$|S_i|+1$$$.
- If $$$u\in S_i, v\in S_i$$$, the number of such edges is $$$\binom{|S_i|}{2}-i$$$. In this case, the edge is not activated. So, the number of intranets do not change, and $$$|S_{i+1}|$$$ equals $$$|S_i|$$$.
Then, we can use a dynamic programming approach to solve Test Set 1. Let $$$\text{dp}(i,j,k)$$$ denote the probability that we assign the highest $$$i$$$ priorities to the edges, the set of vertices introduced by these $$$i$$$ edges has the size of $$$j$$$, and $$$k$$$ intranets have been formed. The transition function can be deduced from the discussion above. The time complexity is $$$O(\mathbf{M}^4)$$$ and it is enough to pass Test Set 1.
We can speed this up to $$$O(\mathbf{M}^2)$$$ by dropping $$$i$$$ from the keys. Let $$$\text{dp}(j,k)$$$ denote the probability that after assigning the highest $$$i$$$ priorities for some $$$i$$$, the set of vertices introduced by these $$$i$$$ edges has the size of $$$j$$$, and $$$k$$$ intranets have been formed. The transition is to assign the highest priority among the edges of the types 1 and 2 above. The probability of there being a new intranet is $$$\frac{\binom{\mathbf{M}-|S_i|}{2}}{\binom{\mathbf{M}-|S_i|}{2} + |S_i|\cdot (\mathbf{M}-|S_i|)}$$$ as we are no longer interested in priorities of the edges of the type 3 above.
Observing the graph
From the solution for Test Set 1, we see that each intranet corresponds to a pair of vertices $$$(u, v)$$$ such that both $$$u$$$ and $$$v$$$ activate the edge $$$(u, v)$$$. This fact can also be proved directly, and we describe here.
Let's fix an assignment of priorities and consider the directed graph where the vertices are the machines and the edges are $$$(u, v)$$$ such that machine $$$u$$$ uses the links connecting machines $$$u$$$ and $$$v$$$. Since this graph is a functional graph (each vertex has outdegree $$$1$$$), each connected component contains exactly one cycle (and possibly some chains of nodes leading into the cycle).
A crucial observation is that the length of a cycle cannot be $$$3$$$ or more. Assume the contrary: that vertices $$$u_1, \ldots, u_c$$$ ($$$c \ge 3$$$) form a cycle in this order, and let the priority of the link connecting $$$u_i$$$ and $$$u_{i+1}$$$ be $$$p_i$$$ (indices are modulo $$$c$$$). Note that those links are distinct. Since machine $$$u_i$$$ uses the link with highest priority, we have $$$p_i \lt p_{i-1}$$$. This gives us $$$p_1 \gt p_2 \gt \cdots \gt p_c \gt p_1$$$, a contradiction. As a self loop is also impossible, we conclude that every cycle in the graph has length $$$2$$$.
Test Set 2
Let's call the set of edges activated by both of their endpoints an active matching as they form a matching. Now the problem is to compute the probability that the size of the active matching is exactly $$$\mathbf{K}$$$.
For a matching $$$X$$$, let $$$f(X)$$$ be the probability that the active matching is $$$X$$$. Since it is not easy to compute $$$f(X)$$$ directly, we apply inclusion‐exclusion principle technique and so let $$$g(X)$$$ be the probability that the active matching contains $$$X$$$, that is, $$$g(X) = \sum_{Y \supseteq X} f(Y)$$$. By inverting this, we have $$$f(X) = \sum_{Y \supseteq X} (-1)^{\lvert Y \rvert - \lvert X \lvert} g(Y)$$$. Our answer is then calculated as follows: $$$$\sum_{\lvert X \rvert = \mathbf{K}} f(X) = \sum_{\lvert X \rvert = \mathbf{K}} \sum_{Y \supseteq X} (-1)^{\lvert Y \rvert - \lvert X \lvert} g(Y) = \sum_{\lvert Y \rvert \ge \mathbf{K}} \binom{\lvert Y \rvert}{\mathbf{K}} (-1)^{\lvert Y \rvert - \mathbf{K}} g(Y) = \sum_{i \ge \mathbf{K}} \binom{i}{\mathbf{K}} (-1)^{i-\mathbf{K}} \sum_{\lvert X \rvert = i} g(X)$$$$
All that remains is to compute $$$g(X)$$$. Of course, this depends only on $$$\lvert X \rvert$$$, and we want to compute it when $$$\lvert X \rvert = i$$$, for each $$$i = \mathbf{K}, \mathbf{K} + 1, \ldots, \mathbf{M}$$$. There are $$$i!$$$ possible orders of priorities assigned to $$$X$$$. Let's fix one of them and let the edges in $$$X$$$ be $$$(u_1, v_1), (u_2, v_2), \ldots, (u_i, v_i)$$$ from the lowest priority to the highest. Then the condition that the active matching contains $$$X$$$ is equivalent to, for each $$$j = 1, 2, \ldots, i$$$, edge $$$(u_j, v_j)$$$ has the highest priority among edges touching at least one of $$$u_1, v_1, \ldots, u_j, v_j$$$. Hence we have $$$$g(X) = i! \prod_{j=1}^i \frac{1}{\binom{\mathbf{M}}{2} - \binom{\mathbf{M}-2j}{2}}.$$$$
Here we note that the denominators can be factorized to see that they are not divisible by $$$10^9+7$$$. The number matchings of size $$$i$$$ is $$$\frac{1}{i! 2^i} \frac{\mathbf{M}!}{(\mathbf{M}-2i)!}$$$, and this completes the $$$O(\mathbf{M})$$$ time solution (the divisions can be done efficient by using the factorization, though this is not necessary).
In fact, we can find the answers for $$$K = 1, \ldots, \lfloor \frac{\mathbf{M}}{2}\rfloor$$$ at the same time in $$$O(\mathbf{M} \log \mathbf{M})$$$ time: The transformation from $$$g$$$ to $$$f$$$ can be represented by a convolution and we can use FFT.