Google Code Jam Archive — Round 2 2017 problems
Overview
This year's Round 2 started off with another tasty treat: Fresh Chocolate, which asked contestants to work within rules set down by a miserly chocolate factory owner. Some greedy insights and case-based analysis were sufficient to solve the problem. Roller Coaster Scheduling also had a greedy solution, but it was much harder to get there! Beaming With Joy was about reducing a grid of laser beams to a satisfiability problem, and Shoot the Turrets was a challenging graph problem that involved an incremental series of matchings. As usual, there was a substantial jump in difficulty between the Round 1s and Round 2!
This round was tougher than even the typical Round 2. Quite a few former Round 3 advancers and finalists had trouble with the Large datasets of the A and B problems, and C and D certainly weren't any simpler than those! D in particular was quite tough, with only 19 correct Large solutions. Even the Smalls of B through D were tricky in their own right.
jsannemo was the first to obtain a perfect score, in just under 1 hour and 44 minutes, and six more contestants (EgorKulikov, shik, fagu, krijgertje, Endagorion, and matthew99) followed with their own 100s. Congratulations — that's no easy feat! The top 500 cutoff turned out to be 37 points plus some speed (usually A + B), and the top 1000 (T-shirt) cutoff was 25 points, or 23 points plus a lot of speed!
Our top 1000 contestants in this round win this year's edition of the coveted Code Jam T-shirt, and our top 500 advance to the even tougher Round 3 — the last online round before the World Finals! Even if you did not advance or win a shirt, it is still quite an accomplishment to make it to Round 2! And, of course, Distributed Round 1 will offer another T-shirt opportunity, plus the chance to advance along the parallel Distributed track. Don't miss it!
Cast
Problem A (Fresh Chocolate): Written and prepared by Pablo Heiber.
Problem B (Roller Coaster Scheduling): Written and prepared by Pablo Heiber.
Problem C (Beaming With Joy): Written by Pablo Heiber. Prepared by Pablo Heiber and Ian Tullis.
Problem D (Shoot the Turrets): Written by Onufry Wojtaszczyk. Prepared by Karol Pokorski.
Solutions and other problem preparation and review by Ahmed Aly, Shane Carr, John Dethridge, Minh Doan, Jackson Gatenby, Md Mahbubul Hasan, Brian Hirashiki, Andy Huang, Lalit Kundu, Zhusong Li, Wei Liu, Alex Meed, Petr Mitrichev, Trung Thanh Nguyen, and Josef Ziegler.
All analyses by Pablo Heiber.
A. Fresh Chocolate
Problem
You are the public relations manager for a chocolate manufacturer. Unfortunately, the company's image has suffered because customers think the owner is cheap and miserly. You hope to undo that impression by offering a free factory tour and chocolate tasting.
Soon after starting the new project, you realized that the company owner's reputation is well-deserved: he only agreed to give away free chocolate if you would minimize the cost. The chocolate to be given away comes in packs of P pieces. You would like to open new packs for each tour group, but the owner insists that if there are leftover pieces from one group, they must be used with the next tour group before opening up any new packs.
For instance, suppose that each pack contains P=3 pieces, and that a tour group with 5 people comes. You will open two packs to give one piece to each person, and you will have one piece left over. Suppose that after that, another tour group with 6 people comes. They will receive the leftover piece, and then you will open two more packs to finish giving them their samples, and so you will have one piece left over again. If two groups with 4 people each come right after, the first of those will get the leftover piece plus a full pack, and the last 4 person group will get their pieces from two newly opened packs. Notice that you cannot open new packs until all leftovers have been used up, even if you plan on using all of the newly opened pack immediately.
In the example above, 2 out of the 4 groups (the first and last groups) got all of their chocolate from freshly opened packs. The other 2 groups got some fresh chocolate and some leftovers. You know that giving out leftovers is not the best way to undo the owner's miserly image, but you had to accept this system in order to get your cheap boss to agree to the project. Despite the unfavorable context, you are committed to doing a good job.
You have requests from N groups, and each group has specified the number of people that will come into the factory. Groups will come in one at a time. You want to bring them in in an order that maximizes the number of groups that get only fresh chocolate and no leftovers. You cannot reject groups, nor have a group get chocolate more than once, and you need to give exactly one piece to each person in each group.
In the example above, if instead of 5, 6, 4, 4, the order were 4, 5, 6, 4, a total of 3 groups (all but the 5 person group) would get only fresh chocolate. For that set of groups, it is not possible to do better, as no arrangement would cause all groups to get only fresh chocolate.
Input
The first line of the input gives the number of test cases, T. T test cases follow. Each test case consists of two lines. The first line contains two integers N, the number of groups coming for a tour, and P, the number of pieces of chocolate per pack. The second line contains N integers G1, G2, ..., GN, the number of people in each of the groups.
Output
For each test case, output one line containing Case #x: y, where
x is the test case number (starting from 1) and y
is the number of groups that will receive only fresh chocolate if you bring
them in in an order that maximizes that number.
Limits
Memory limit: 1 GB.
1 ≤ T ≤ 100.
1 ≤ N ≤ 100.
1 ≤ Gi ≤ 100, for all i.
Small dataset (Test Set 1 - Visible)
Time limit: 20 seconds.
2 ≤ P ≤ 3.
Large dataset (Test Set 2 - Hidden)
Time limit: 40 seconds.
2 ≤ P ≤ 4.
Sample
3 4 3 4 5 6 4 4 2 4 5 6 4 3 3 1 1 1
Case #1: 3 Case #2: 4 Case #3: 1
Sample Case #1 is the one explained in the statement. Besides the possible optimal order given above, other orders like 6, 5, 4, 4 also maximize the number of groups with only fresh chocolate, although the groups that get the fresh chocolate are not necesarily the same. Notice that we only care about the number of groups that get the best experience, not the total number of people in them.
In Sample Case #2, the groups are the same as in Case #1, but the packs contain two pieces each. In this case, several ways of ordering them — for instance, 4, 4, 6, 5 — make all groups get only fresh chocolate.
In Sample Case #3, all groups are single individuals, and they will all eat from the same pack. Of course, only the first one to come in is going to get a freshly opened pack.
B. Roller Coaster Scheduling
Problem
You created a new roller coaster that is about to open. Its train consists of a single row of N seats numbered 1 through N from front to back. Of course, seats closer to the front are more valuable. Customers have already purchased opening-day tickets. Each ticket allows a specific customer to take one ride on the coaster in a particular seat. Some customers may have bought more than one ticket, and they expect to go on one ride for each ticket.
You need to decide how many roller coaster rides there will be on opening day. On each ride, one customer can sit in each seat; some seats on a ride might be left empty. You cannot assign a customer to more than one seat in the same ride, nor can you put two customers on the same seat in any given ride.
You wish to minimize the number of rides required to honor all tickets, to reduce operational costs. To reduce the required number of rides, you can promote any number of tickets. Promoting a ticket means taking a customer's ticket and giving that customer a new ticket for a seat closer to the front of the train (that is, a seat with a lower number). You would prefer to promote as few tickets as possible, since too many promotions might cause customers to get greedy and ask for more promotions in the future.
Given the positions and buyers of all the tickets that have been sold, what is the minimum number of rides needed to honor all tickets, using as many promotions as needed and scheduling the rides optimally? And what is the minimum number of ticket promotions necessary to attain that number of rides? Note that promoting a given customer on a given ride from seat 4 to seat 2, for example, counts as only one promotion, not two separate ones.
Input
The first line of the input gives the number of test cases, T. T test cases follow. Each test case starts with a single line with three integers N, the number of seats in the roller coaster, C, the number of potential customers, and M, the number of tickets sold. The customers are identified with numbers between 1 and C. Then, M lines follow, each containing two integers: Pi, the position in the roller coaster assigned to the i-th ticket, and Bi, the identifier of the buyer of that ticket.
Output
For each test case, output one line containing Case #x: y z,
where x is the test case number (starting from 1),
y is the minimum number of rides you need to honor all tickets
if you use the promotions and schedule the rides optimally, and
z is the minimum number of promotions you need to make be able
to honor all tickets with y rides.
Limits
Time limit: 20 seconds per test set.
Memory limit: 1 GB.
1 ≤ T ≤ 100.
2 ≤ N ≤ 1000.
1 ≤ M ≤ 1000.
1 ≤ Pi ≤ N.
1 ≤ Bi ≤ C.
Small dataset (Test Set 1 - Visible)
C = 2.
Large dataset (Test Set 2 - Hidden)
2 ≤ C ≤ 1000.
Sample
5 2 2 2 2 1 2 2 2 2 2 1 1 1 2 2 2 2 1 1 2 1 1000 1000 4 3 2 2 1 3 3 3 1 3 3 5 3 1 2 2 3 3 2 2 3 1
Case #1: 1 1 Case #2: 2 0 Case #3: 2 0 Case #4: 2 1 Case #5: 2 1
Note that the last two sample cases would not appear in the Small dataset.
In Case #1, both customers purchased a ticket for position 2. It is impossible to honor both tickets with a single ride, but promoting either ticket to position 1 allows you to accommodate both tickets on the same round.
Case #2 is a similar story, except both tickets are for position 1. Since you cannot promote those tickets or exchange them for inferior tickets, you are forced to run 2 separate rides, one per customer.
Case #3 features the same customer purchasing both positions. Since you are forced to have 2 rides for that customer, there is no reason to give out any promotions.
In Case #4, notice that there may be both customers and positions with no tickets assigned. In this case, there are three tickets sold for position three. If you promote customer 2 to position 2, for instance, you can have one ride with customer 1 sitting in position 2 and customer 3 sitting in position 3, and a second ride with customer 2 in position 2 and customer 1 in position 3. Additional promotions will not allow you to decrease the number of rides, because customer 1 has two tickets and you need to honor those in different rides, regardless of position.
In Case #5, one optimal solution is to promote one of the 3 1
tickets to 1 1.
C. Beaming With Joy
Problem
Joy is about to go on a long vacation, so she has hired technicians to install a security system based on infrared laser beams. The technicians have given her a diagram that represents her house as a grid of unit cells with R rows and C columns. Each cell in this grid contains one of the following:
/: A two-sided mirror that runs from the cell's lower left corner to its upper right corner.\: A two-sided mirror that runs from the cell's upper left corner to its lower right corner.-: A beam shooter that shoots horizontal beams out into the cells (if any) to the immediate left and right of this cell.|: A beam shooter that shoots vertical beams out into the cells (if any) immediately above and below this cell.#: A wall. (Note that the house is not necessarily surrounded by a border of walls; this is one reason why Joy needs a security system!).: Nothing; the cell is empty.
Beams travel in straight lines and continue on through empty cells. When a
beam hits a mirror, it bounces 90 degrees off the mirror's surface and
continues. When a beam traveling to the right hits a / mirror,
it bounces off the mirror and starts traveling up; beams traveling up, left,
or down that hit a / mirror bounce off and travel right, down,
or left, respectively. The \ mirror behaves similarly: when a
beam traveling right, up, left or down hits it, it bounces off and starts
traveling down, left, up or right, respectively. When a beam hits a wall or
goes out of the bounds of the grid, it stops. It is fine for beams to cross
other beams, but if a beam hits any beam shooter (including, perhaps, the
beam shooter that originated the beam), that beam shooter will be destroyed!
Joy wants to make sure that every empty cell in the house has at least one
beam passing through it, and that no beam shooters are destroyed, since that
would just be wasting money! Unfortunately, the technicians have already
installed the system, so the most Joy can do is rotate some of the existing
beam shooters 90 degrees. That is, for any number (including zero) of beam
shooters, she can turn - into | or vice versa.
Can you find any way for Joy to achieve her goal, or determine that it is impossible? Note that it is not required to minimize the number of rotations of beam shooters.
Input
The first line of the input gives the number of test cases, T.
T test cases follow. Each case begins with one line with two integers
R and C: the number of rows and columns in the grid
representing the house. Then, R lines of C characters each
follow; each character is /, \, -,
|, #, or ., as described in the
statement.
Output
For each test case, output one line containing Case #x: y, where
x is the test case number (starting from 1) and y
is IMPOSSIBLE if Joy cannot accomplish her goal, or
POSSIBLE if she can. Then, if the case is possible, output the
same R lines of C characters each from the input grid, with
zero or more instances of - replaced by | or vice
versa.
If there are multiple possible answers, you may output any of them.
Limits
Time limit: 20 seconds per test set.
Memory limit: 1 GB.
1 ≤ T ≤ 100.
1 ≤ C ≤ 50.
Each character in the grid is one of /, \,
-, |, #, or ..
The number of - characters plus the number of |
characters (that is, the number of beam shooters) in the grid is between 1
and 100, inclusive.
There is at least 1 . character (that is, empty space) in the
grid.
Small dataset (Test Set 1 - Visible)
1 ≤ R ≤ 5.
There are no / or \ characters (that is, no
mirrors) in the grid.
Large dataset (Test Set 2 - Hidden)
1 ≤ R ≤ 50.
Sample
5 1 3 -.- 3 4 #.## #--# #### 2 2 -. #| 4 3 .|. -// .-. #\/ 3 3 /|\ \\/ ./#
Case #1: IMPOSSIBLE Case #2: POSSIBLE #.## #||# #### Case #3: POSSIBLE |. #| Case #4: POSSIBLE .-. |// .|. #\/ Case #5: IMPOSSIBLE
Note that the last 2 sample cases would not appear in the Small dataset.
In Sample Case #1, if a beam shooter is positioned to shoot its beam into
the empty cell, it will necessarily destroy the other beam shooter. So the
case is IMPOSSIBLE.
In Sample Case #2, the leftmost beam shooter must be rotated to cover the empty cell. The rightmost beam shooter must also be rotated to avoid destroying the leftmost beam shooter.
In Sample Case #3, the existing beam shooters already cover all empty cells with their beams and do not destroy each other, so outputting the grid from the input would be acceptable. However, notice that the output that we have given is also correct.
In Sample Case #4, one acceptable solution is to rotate all three of the beam shooters. However, note that the following would also be acceptable:
.-.
|//
.-.
#\/
since it is not necessary for cells with mirrors to have a beam pass through them. (Who would steal giant diagonal mirrors, anyway?)
In Sample Case #5, the beam shooter would destroy itself no matter which
orientation Joy chooses for it, so the case is IMPOSSIBLE.
D. Shoot the Turrets
Problem
The fight to free the city from extraterrestrial invaders is over! People are happy that love and peace have returned.
The city is represented as a grid with R rows and C columns. Some cells on the grid are buildings (through which nobody can see, nobody can shoot, and nobody can walk), and some are streets (through which everybody can see, shoot and walk). Unfortunately, during the war, the now-defeated invaders set up automatic security turrets in the city. These turrets are only in streets (not in buildings). They pose a threat to the citizens, but fortunately, there are also some soldiers on the streets (not in buildings). Initially, no soldier is in the same place as a turret.
The invader turrets do not move. They are small, so they don't block sight and shooting. A soldier cannot walk through an active turret's cell, but can walk through it once it is destroyed. A turret can only see soldiers in the cells for which it has a horizontal or vertical line of sight. If a soldier enters such a cell, the turret does not fire. If a soldier attempts to exit such a cell (after entering it, or after starting in that cell), the turret fires. Luckily, a soldier can still shoot from that cell, and the turret will not detect that as movement. It means that none of your soldiers will actually die, because in the worst case they can always wait, motionless, for help (perhaps for a long time). Maybe you will have a chance to rescue them later.
Each soldier can make a total of M unit moves. Each of these moves must be one cell in a horizontal or vertical direction. Soldiers can walk through each other and do not block the lines of sight of other soldiers or turrets. Each soldier also has one bullet. If a soldier has a turret in her horizontal or vertical line of sight, the soldier can shoot and destroy it. Each shot can only destroy one turret, but the soldiers are such excellent shooters that they can even shoot past one or several turrets or soldiers in their line of sight and hit another turret farther away!
You are given a map (with the soldier and turret positions marked). What is the largest number of turrets that the soldiers can destroy?
Input
The first line of the input gives the number of test
cases, T. T test cases follow. Each test case begins with a
line containing the integer C (the width of the map), R (the
height of the map) and M (the number of unit moves each soldier can
make). The next R lines contain C characters each,
with . representing a street, # representing a
building, S representing a soldier and T
representing a turret.
Output
For each test case, output one line containing Case #x: y,
where x is the test case number (starting from 1)
and y is the maximum number of turrets that it is possible to
destroy. Then y lines should follow: each should contain two
integers s_i and t_i denoting that the ith thing that
happens should be soldier s_i destroying turret t_i (you don't
need to specify exactly how the soldier has to move). If multiple valid
strategies exist, you may output any one of them.
Soldiers are numbered from 1, reading from left to right along the top row, then left to right along the next row down from the top, and so on, from top to bottom.
Turrets use their own independent numbers, and are numbered starting from 1, in the same way.
Limits
Memory limit: 1 GB.
1 ≤ T ≤ 100.
0 ≤ M < C × R.
Small dataset (Test Set 1 - Visible)
Time limit: 30 seconds.
1 ≤ C ≤ 30.
1 ≤ R ≤ 30.
The number of S symbols is between 1 and 10.
The number of T symbols is between 1 and 10.
Large dataset (Test Set 2 - Hidden)
Time limit: 60 seconds.
1 ≤ C ≤ 100.
1 ≤ R ≤ 100.
The number of S symbols is between 1 and 100.
The number of T symbols is between 1 and 100.
Sample
4 2 2 1 #S T. 2 6 4 .T .T .T S# S# S# 5 5 4 ..... SS#.T SS#TT SS#.T ..... 3 3 8 S.# .#. #.T
Case #1: 1 1 1 Case #2: 3 3 3 1 1 2 2 Case #3: 3 1 2 2 1 6 3 Case #4: 0
In Case #2, one of the possible solutions is to move soldier 3 up three cells and shoot turret 3. Then soldier 1 can move up one cell and right one cell (to where turret 3 was) and shoot past turret 2 to destroy turret 1. Finally, soldier 2 can move up three cells and shoot turret 2.
In Case #3, soldier 1 can move up one cell, then right three cells and shoot turret 2. Then soldier 2 can move up one cell, then right three cells and shoot turret 1. Finally, soldier 6 can move down one cell, then right three cells and shoot turret 3. Other soldiers have insufficient move range to shoot any other turrets.
In Case #4, the soldier cannot move to within the same row or column as the turret, so the turret cannot be destroyed.
Analysis — A. Fresh Chocolate
Fresh Chocolate: Analysis
The main initial observation to have is that the group sizes are only important modulo P. Then, we can just take the smallest possible equivalent size for each group, and further assume that all of them are within the range [1,P]. Moreover, you may find it easier to map them all to the range [0,P-1], using the modulo operation, as long as you don't mind working with 0, which is not a real group size.
We can see now that a test case with P=2 can be described by 2 integers: the number of groups with odd size, and the number of groups with even size. Similarly, each test case can be described by a tuple of exactly P integers a0, a1, ..., aP-1, where ai is the number of groups of size equal to i modulo P.
The groups counted in a0, i.e., those with a group size multiple of P, are the simplest. No matter when they are brought in for the tour, the number of leftovers after they are given chocolate is the same as before. Therefore, their position won't change how many of the other groups get all fresh chocolate. This implies that it's always optimal to greedily choose a position for them where they get all fresh chocolate, and that we can accomplish that by putting them all at the beginning. Since the starting group gets fresh chocolate, a stream of groups with sizes that are multiples of P will all get fresh chocolate and will leave no leftovers for the next group. That is, we can solve the problem disregarding a0, and then add a0 to the result. After this simplification, there are only P-1 numbers left to consider.
Small dataset
For the Small dataset, there are only two possible values for P, so we can consider them separately.
For P=2, there is only one number to consider: a1. Since all groups are equivalent, there are no decisions to be made. All odd-sized groups will alternate between getting all fresh chocolate and getting a leftover piece. Since the last group will get fresh chocolate if there is an odd number of such groups, the number of groups that get fresh chocolate is ceiling(a1 / 2).
For P=3, there are two numbers to consider: a1 and a2. Intuitively, we should pair each 1-person group with a 2-person group to go back to having no leftovers as soon as possible, and that's indeed optimal: start with an alternation of min(a1, a2) pairs, where we get min(a1, a2) added to our result, and then add pairs, of which min(a1, a2) will get all fresh chocolate. Then add all the remaining M = |a1 - a2| groups (all of size 1 or 2 modulo P, depending on which type had more to begin with). Of those, ceiling(M / 3) will get all fresh chocolate. This last calculation is similar to what we saw for odd-sized groups for P = 2. We will prove the optimality of this strategy below.
Large dataset
The remaining P=4 case is a bit more complicated than just combining our insights from the P=2 and P=3 cases. To formalize our discussion, and to prove the correctness of our Small algorithm, we will introduce some names. Let us call a group fresh if it is given all fresh chocolate, and not fresh if it gets at least one leftover piece. Also, we will call a group with a number of people equal to k modulo P a "k-group".
Given some fixed arrival order, let us partition it into blocks, where each block is an interval of consecutive groups that starts with a fresh group and doesn't contain any other fresh groups. That is, we start a new block right before each fresh group. The problem is now equivalent to finding the order that maximizes the number of blocks. A group is fresh if and only if the sum of all people in the groups that preceded it is a multiple of P. This implies that reordering within a block won't make any other blocks invalid, so it won't make a solution worse (although it could improve it by partitioning a block into more than one block). Also notice that, with the possible exception of the last block, reordering blocks also doesn't alter the optimality of a solution.
Suppose we have an optimal ordering of the groups, disregarding 0-groups as we mentioned above. First, we can see that if a block contains a k-group and a different (P-k)-group, then it only contains those two: otherwise, we can reorder the block putting the two named groups first, and since the sum of people of the two groups is a multiple of P, that partitions the block further, which means the original solution is not optimal. Second, let us show that it is always optimal to pair a k-group with a (P-k)-group into a block. Assume an optimal order with a maximal number of blocks consisting of a k-group and a (P-k)-group. Then, suppose there is a k-group in a block A with no (P-k)-group and a (P-k)-group in a block B with no k-group. We can build another solution by making a new block C consisting of the k-group from block A and the (P-k)-group from block B, and another block D consisting of the union of the remaining elements of blocks A and B. If D doesn't sum up to a multiple of P, that implies that either A or B didn't to begin with, so we can just place D at the end in place of the one that didn't. C can be placed anywhere in the solution. This makes a solution with an additional pair that is also optimal, which contradicts the assumption that a k-group and a (P-k)-group existed in separate blocks. This proves that, for P=3, it is always optimal to pair 1-groups and 2-groups as we explained above.
For P=4, the consequence of the above theorem is that we should pair 2-groups with themselves as much as possible and 1-groups with 3-groups as much as possible. This leaves at most one 2-group left, and possibly some 1-groups or 3-groups left over, but not both. Since we need four 1-groups or four 3-groups to form a non-ending block, and we can use a 2-group to form a non-ending block with only two additional groups of either type, it is always optimal to place the 2-group first, and then whatever 1-groups or 3-groups may be left. Overall, the solution for P=4 is a0 as usual (singleton blocks of 0-groups), plus floor(a2 / 2) (blocks of two 2-groups), plus min(a1, a3) (blocks of a 1-group and a 3-group), plus ceiling((2 × (a2 mod 2) + |a1 - a3|) / 4) (the leftover blocks at the end).
Notice that even though the formality of this analysis may be daunting, it is reasonable to arrive at the solution by intuition, and the code is really short. If you have a candidate solution but you find it hard to prove, you can always compare it against a brute force solution for small values of N to get a little extra assurance. Or there is also ...
A dynamic programming solution
The insight that a case is represented by a P-uple is enough to enable a standard dynamic programming solution for this problem. Use P-uples and an additional integer with the number of leftovers as current state, and recursively try which type of group to place next (there are only P alternatives). Memoizing this recursion is fast enough, as the domain is just the product of all integers in the initial tuple, times P. When the group types' sizes are as close to one another as possible, we get the largest possible domain size, which is (N/P)P × P. Considering the additional iteration over P possibilities to compute each value, the overall time complexity of this approach is O((N/P)P × P2). Even for the largest case, this is almost instant in a fast language, and gives plenty of wiggle room to memoize with dictionaries and use slower languages. A purposefully non-optimized implementation in Python takes at most half a second to solve a case in a modern machine, so it finishes 100 cases with a lot of time to spare. Moreover, just noticing that groups of size multiple of P can optimally be placed first makes the effective value of P be one less, which greatly improves speed and makes the solution solve every test case instantly.
Analysis — B. Roller Coaster Scheduling
Roller Coaster Scheduling: Analysis
Small dataset
There are various ways to solve the Small dataset; for instance, it can be reduced to a flow problem. It is also possible to find a greedy strategy or even a formula: the number of rides needed is max(number of tickets for customer 1, number of tickets for customer 2, number of tickets with seat 1), and the number of promotions needed is max(0, (maximum among counts of i-th seat among all tickets) - number of rides needed). However, these strategies are tricky to prove. The rest of our analysis will shed some light on why they work.
Large dataset
To solve the Large dataset, we can start with observations similar to those in the Small case: the number of tickets held by any one person is a lower bound on the number of total rides, and so is the number of tickets for position 1. This is because the set of tickets held by any one person, and the set of tickets for position 1, share the property that no two tickets in the set can be honored in the same ride, even with promotions. An extension of this is that for the set of all tickets for positions 1, 2, ..., K, at most K of them can be honored by a single ride (possibly using promotions). This means that, if SK is the number of tickets for positions up to and including K, ceil(SK / K) is also a lower bound on the final number of rides.
It is not difficult to see this when there is only one ticket per customer: if the maximum of all those lower bounds is R, for as long as there is some position P such that there are more than R tickets for position P, we can promote any ticket for position P to some previous position that has less than R tickets assigned, which is guaranteed to exist due to the R ≥ ceiling(SP / P). After that, no position is assigned more than R tickets. Since there are no repeated customers, we can just grab one ticket for each position that has tickets remaining and assign them to a ride until there are no more left. This will yield an assignment with exactly R rides, and we proved above that there can't be less than R.
When there are customers holding more than one ticket, our greedy assignment in the last step above might fail. We can still prove that there is an assignment that works with a bit of mathematical modeling. Consider a fixed ride plan. Let us define the ride plan matrix as a square matrix of side S = max(N,C). The first C rows represent customers and the first N columns represent positions. The remaining rows or columns represent fake customers or positions, whose role will be clear in a moment. For each ride in the plan, we construct a one-to-one assignment of customers and positions. Customers that participate in the ride are assigned to their position on it. Customers that do not are assigned to empty positions or fake positions. If there are more positions than customers, each empty position is assigned a fake customer. Then, the value of a given cell of the ride plan matrix is the number of times the represented customer was assigned to the represented position. Notice that the value is an upper bound on the number of times a customer actually rode in the position, but not the exact number.
Notice that for any ride plan consisting of R rides, its ride plan matrix will have rows and columns that sum up to R. This is because for each ride, there is exactly one cell per row and one cell per column that gets a 1 added to it. The most interesting realization is that we can go the other way: for any matrix M such that all its rows and columns add up to R, there is a ride plan consisting of R rides such that M is a ride plan matrix for it. The proof is a simple variation on the Birkhoff–von Neumann theorem, which implies a matrix with that property can be expressed as a sum of permutation matrices, and each permutation matrix corresponds to a possible ride.
A given set of tickets can also be represented by a matrix of side S by having a cell contain the number of tickets a given cusotmer holds for a given position. Let us say that a matrix M is less than or equal to another matrix M', if and only if the cell at row i and column j in M is less than or equal to that the value of the cell at row i and column j in M'. After promotions, we need the matrix representing the tickets to be less than or equal to the ride plan matrix.
Notice now that the greedy promotion algorithm presented in the second paragraph of this section, actually yields a ticket matrix such that no row or column exceeds the established lower bound R, even if there is more than one ticket per customer. The proof is exactly the proof above. What was missing before was a way to know that set of tickets could be turned into an actual ride plan in the case where there is more than one ticket per customer. We now have such a way, which means the originally naive solution is actually a full solution for the problem. Moreover, since we need to report the minimum number of promotions and not the promotions themselves, we can just add SP - R for each position P such that SP > R, and we are done.
Analysis — C. Beaming With Joy
Beaming With Joy: Analysis
Small dataset
There are a lot of ways to solve the Small dataset. The most straightforward way is to use dynamic programming. Since the input contains no mirrors, each laser beam covers a set of non-wall cells that are either horizontally or vertically consecutive. Let us process the columns from left to right. For each row, we will keep track of its current status, which must be one of the following:
- It has an incoming beam, which originated in this row in a previously processed column and was not yet blocked by a wall.
- It needs a beam — that is, there is at least one cell in this row from a previously processed column that has not yet been covered by a beam, but could be (i.e. there is not a wall in the way).
- It does not have nor it can receive a beam, because this would destroy a beam shooter pointing vertically that we saw in this row in a previously processed column.
- None of the above. This means that all previous consecutive non-wall cells, if any, are covered with vertical beams, so we can shoot horizontally on this row, but there is no obligation yet to do so.
There are some ways to refine this to fewer combinations, but it's not necessary. Then, we can try all combinations of orientations for the beam shooters in the current column and see if that produces a valid status for the next column (there are more efficient ways to do this part, but this will do). This requires a bit of casework: for each row, we have to combine its incoming status with the current cell. The current cell can be one of five things: a covered or uncovered empty cell, a vertical or horizontal beam shooter, or a wall. Then, since there are 4 possible states for each row, the domain of our recursive function is of size 4R × C and the calculation of each value in that domain requires checking up to 2R combinations of beam shooters' orientations. Each such check requires a linear pass over the R cells, making the overall time complexity bounded by O(8R × C × R). It's not hard to come up with even smaller bounds, given that many combinations of statuses are actually impossible.
There is also a greedy Small solution that relies only on the absence of mirrors:
- If a beam shooter can possibly destroy another, then point it the other way. If both directions would destroy another beam shooter, then the case is impossible.
- If there are uncovered cells that can only be covered by a single non-yet-fixed shooter, then point that shooter in its direction. If any remaining cells are impossible to cover (because any beam shooters that may have pointed at it had to be fixed in the other direction), then the case is impossible.
- Make all beam shooters that are not fixed yet shoot horizontally (or all vertically, which also works).
This works because if any cell remains uncovered after the first two steps, it can only be because there are exactly two remaining non-fixed beam shooters potentially pointing at it: one horizontally, and one vertically. If there had been two or more beam shooters pointing at it in the same direction, we would have already fixed all of them in step 1; if there had been only one beam shooter in total, we would have fixed it in step 2. Then, choosing the same direction for all beam shooters ensures that for all those cells, (exactly) one of the beam shooters is pointed in the correct direction to cover that cell.
Large dataset
The second solution presented above for the Small dataset hints at a possible generalization that solves the Large dataset.
In the Small, each cell is at an intersection of a horizontal line of consecutive non-wall cells, and a vertical line of consecutive non-wall cells. These lines of cells run between walls, between opposite grid boundaries, or between one wall and one grid boundary. Each of these lines of cells is characterized by having either no beam shooter (which forces each cell to be covered from the other direction in step 2), one beam shooter (which leaves the cell on hold until step 3), or more than one (which forces all beam shooters on the line to point in the direction opposite to the line of cells in step 1). In the Large, something similar happens, but instead of simple lines of cells, we have the more complicated notion of paths. A path is a set of pairs (c, d) where c is any cell that is empty or contains a beam shooter and d is either horizontal or vertical. A pair (c, d) and a different pair (c', d') are part of the same path if and only if a beam shooter placed on cell c and pointing in direction d would produce a beam that, ignoring all other beam shooters, would pass through cell c' in direction d'. As an example, the following picture illustrates a grid with 9 paths.
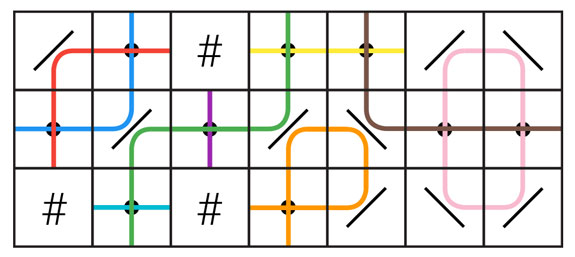
Notice that the red and blue paths pass through the same set of empty cells, although the (cell, direction) pairs that make up those paths are different. Also notice there is an orange path that passes through the same cell twice; that is, the path contains the pair (c, horizontal) and the pair (c, vertical) where c is the rightmost empty cell in the bottom row. Also notice how some paths may contain a single pair, like the turquoise, purple, and brown paths in the picture. Finally, some paths loop onto themselves, like the pink path in the picture, while other paths start and end at a wall or grid boundary. We call the former loop paths.
Paths that go through a number of beam shooters other than one have similar immediate consequences to lines of consecutive non-wall cells in the Small dataset. For convenience, let us define the opposite function o given by o(horizontal) = vertical and o(vertical) = horizontal.
- If a path contains two pairs (c, d) and (c, o(d)) where c is a cell that contains a beam shooter, the case is impossible, because that means that beam shooter will destroy itself when pointed in either direction.
- If a loop path contains a pair (c, d) where c is a cell that contains a beam shooter, the beam shooter must be fixed in direction o(d).
- If a path contains two or more pairs (ci, di) where ci contains a beam shooter, then beam shooter ci must be fixed in direction o(di).
- If there is no beam shooter on a path that contains two pairs (c, d) and (c, o(d)) where c is an empty cell, the case is impossible (as c cannot be covered).
- If there is no beam shooter on a path, then for each pair (ci, di) it contains: let p be the path containing (ci, o(di)). If p contains a single pair (c, d) where c contains a beam shooter, then fix that beam shooter in direction d. If p contains a number of beam shooters other than one, the case is impossible.
If a beam shooter is required to be fixed in two different directions, by the same or different steps, the case is impossible. This is the generalization of steps 1 and 2 in the Small greedy solution. After applying these, some cells may be left uncovered. As before, those cells are always in the intersection of two different paths, and those paths contain a single pair where the cell contains a beam shooter each. Unfortunately, the way to set the remaining beam shooters so that every cell is covered is not as simple as step 3 for the Small. This might start to look like a (non-bipartite) matching problem, but it is not one!
In the Small, after all the cases that directly fixed the direction of some beam shooter, each empty cell that remained uncovered could possibly be covered by two beam shooters, one on each direction. The same is true in this case: for each empty cell c that remains uncovered there are two different paths that contain the pairs (c, horizontal) and (c, vertical), and each of them passes through exactly one pair that contains a non-yet fixed beam shooter. Say those two pairs containing shooters are (s1, d1) and (s2, d2). Then, covering cell c requires us to either set s1 in direction d1 or s2 in direction d2, or both. If it happens to be s1 = s2, then it must be d1 ≠ d2, and the requirement is fullfilled by any assignment.
If we assign logical variables to the shooters with the logical values true and false corresponding to the two directions, each of these restrictions is a disjunction of two literals. Making all such disjunctions simulatenously true is, then, making their conjunction true. Finding a truth assignment to variables to make a conjunction of disjunctions of up to two literals each true is a problem known as the 2-satisfiability problem or 2SAT. We can use known 2SAT algorithms to solve that problem and get an assignment for the variables, and then translate that assignment back into an assignment of directions for the beam shooters.
The greedy Small-only solution we presented is even simpler to prove correct under this logic model: without mirrors, every disjunction has exactly one literal negated (because the cell requirement is for one beam shooter to be horizontal and/or some other beam shooter to be vertical), so assigning all variables a true value makes all disjunctions true thanks to the non-negated literal, and also assigning them all a false value makes all disjunctions true thanks to the negated literal.
This analysis is written in the order in which one might reason this problem step by step, without any huge leap at any single step. However, for some people it might be faster to have an aha moment and notice that each cell yields a requirement on up to two beam shooters directly: cells without shooters imply a requirement on up to two shooters, one of each direction, to be true. If there is only one of those, that can be encoded as a single-literal disjunction, or made it a two-literal disjunction by simply taking literal L and writing (L ∨ L). Then, beam shooters that possibly point at another beam shooter yield another single-literal disjunction forcing them to point the other way. This makes the first pass unnecessary and encodes all requirements into the 2SAT instance, making the solution more concise.
This problem lends itself to many greedy heuristics plus some kind of bruteforce or backtracking. Notice that 2SAT itself can be solved in polynomial time by some backtrackings and by a graph-theoretical algorithm that has many greedy decisions underneath (both approaches are mentioned in the Wikipedia article). So, many algorithms that don't explicitly use an algorithm for the 2SAT problem are actually correct because they are basically doing the same thing without going through the modeling.
Analysis — D. Shoot the Turrets
Shoot the Turrets: Analysis
Small dataset
The first thing to notice is that, if a given soldier s is not the first to perform her task, there is no reason for s to move at all until all soldiers that are to shoot a turret before s have finished.
Let us call the output a strategy: a pairing between some soldiers and all turrets, in a specific order. Given a fixed strategy, we can check if it's viable with one BFS per soldier, in order. We stop with the first soldier that can't reach its assigned turret, if any, and report the number shot so far. Any strategy that shoots a maximum number of turrets can be extended to a pairing of all soldiers to turrets, so this covers all possibilities. Besides the usual empty spaces and walls, we need to consider some empty spaces enterable but not exitable: the spaces that are in the line of sight of turrets that are to be destroyed by a soldier after the current one. Each check takes time linear in the size of the map, so O(RC) per soldier.
Unfortunately, there can be too many strategies to bruteforce them. There can be up to 10! possible pairings and 10! orderings, which means 10!2 strategies, which is way too big, so we need to do better. We will use precomputing to optimize the check and dynamic programming to optimize the strategy generation.
Let S be the number of soldiers and T the number of turrets. To make the check faster, we can compute, for each soldier and each possible subset of still-alive turrets, the set of reachable turrets to shoot. That requires at most 2T × S BFSes like the ones mentioned above, for a total complexity of O(2T × SRC), which is fine for the Small limits.
Now on to the dynamic programming: consider the function f(s, t) which finds a strategy that shoots a maximum number of turrets for a given set of remaining soldiers s and a given set of remaining turrets t, or decides that there isn't one. Each of s and t can be represented with a binary string of up to S and T digits, respectively. The domain of the function, then, is of size up to 2S+T. To compute the function, we can check every soldier against every reachable turret. Since that list is precomputed, this takes at most S iterations over lists of length up to T. The overall computation of f, if memoized, has a complexity of O(2S+T × ST), which again, finishes comfortably in time under the Small limts.
Large dataset
For the Large dataset, anything with exponential complexity seems doomed to fail, so we need to go a different route. We will reuse the the BFS idea (to check out whether turrets are reachable) from the Small, but there are a lot of additional insights.
Let us build a bipartite graph G with a node for each soldier and turret. G has an edge from soldier s to turret t if and only if soldier s can destroy turret t after all other turrets have been destroyed. A single BFS starting from each soldier can build this graph. We state the following: destroying R turrets is possible if and only if there is a matching in G that covers R turrets. The only if part is trivial, as the conditions for edges in the graph are a relaxation of the conditions for the pairing we need to construct as solution. We concentrate on proving the if part. Moreover, we provide here a computably constructive proof, for which there is an efficient enough algorithm, meaning the proof is also an algorithm that solves the problem.
First, if G is empty, the problem is solvable trivially by vacuity. For non-empty G, we can use the Ford-Fulkerson algorithm to find an initial maximum matching M of G of size R. We will further consider only the soldiers present in M and ignore the others. From now on, we refer only to soldiers matched by M, and we remove the unmatched soldier nodes from G. Let us define the graph G' with the same nodes as G, but an edge between soldier s and turret t only exists in G' if s can destroy t with the other turrets active. Clearly, G' is a subgraph of G. The outdegree of each soldier node in M is at least 1. If an edge (s, t) in G does not exist in G', it is because some other turret t' is reachable by s and blocking the path to t. But then, (s, t') is in G'. Therefore, the outdegree of each soldier not in G' is at least 1.
Consider the graph H that is the union of G' plus the edges in M reversed. If H contains an edge (s, t') where t' is a turret node not covered by M, let M' be equal to M, but replacing (s, t) by (s, t'), where (s, t) was the edge covering s present in M. Of course, M' is a maximum matching of G of the same size as M. If there is no such edge in H, do the following: since H is a supergraph of G', the outdegree of each soldier node in H is at least 1. The inclusion of the reversed edges of M in H means the outdegree of all turret nodes matched in M in H is at least 1. Therefore, starting at any soldier and moving through edges in H, we will always encounter nodes with outdegree 1 of soldiers and turrets covered by M, and eventually find a cycle of them. Let us call this cycle C. Notice that the edges going out of turrets in H are only the reversed edges from M, so C is necesarily an alternation of reversed edges from M and edges from G'. Consider a new matching M' of G consisting of the edges of M whose reverse is not in C, plus the edges in C whose reverse is not in M. That is, M' is M but exchanging the edges present in C in some direction. M' in this case is also a matching of G of the same size as M. If the cycle is of length 2, then M' ends up being exactly the same as M.
In both cases, we constructed a new matching M' of the same size as M with the additional property that at least one edge of M' is present in G'. Therefore, there are some edges in the matching that represent a number A > 1 of actions that we can take now. So, we can just take those A actions, remove all A used soldier nodes and A destroyed turret nodes, and we are left with a smaller graph which also has a maximum matching of size R - A (whatever is left of M'). Rinse and repeat until the graph is empty.
Complexity analysis. Building the original G takes time O(SRC) for S BFSes, and the original matching takes time O((S+T)3) (there are faster algorithms for matching, but Ford-Fulkerson is more widely known, simpler to code, and sufficient for this task). After that, we have at most T steps of altering the matching and removing some parts of it. Each of this steps requires building G', which takes time O(SRC) for S BFSes, and after that, all steps are linear in the size of the graphs G, G' or H, which are all bounded by O((S+T)2). Notice that building G' is by far the slowest step, so you can use less efficient implementations to manipulate the graphs without altering the time complexity. This gives an overall complexity of O(TSRC + (S+T)3). This is enough to solve the problem, but it can be further refined by noticing each time we build G', the BFSes will reach the same places or farther than in the previous step, so, if instead of restarting from scratch we remember the BFSes and continue from where we were stopped before, we can reduce the total time to build G' by a factor of T, down to O(SRC), reducing the final complexity to O(SRC + (S+T)3).