Google Code Jam Archive — World Finals 2015 problems
Overview
Our 2015 finals problems were tough enough that no contestant attempted all six. The scoreboard was a churning battlefield, and we saw all kinds of solution approaches, such as simulated annealing, in play! Problems C, D, and E in particular posed a race of insight rather than coding speed, and few contestants were able to attempt the Large dataset for more than one of them.
At the end of the contest, bmerry was the only contestant who had attempted the Large dataset of the very challenging Crane Truck problem, and he appeared to be in the lead... but when the dust settled, it was Gennady.Korotkevich who emerged on top for the second year in a row. rng..58 came in second; he had reached the same number of points as Gennady (but with a higher time penalty) five minutes before the end of the contest, only to have Gennady pull even farther away less than a minute later! bmerry took third place with the only other triple-digit score.
Congratulations to all of our finalists and to everyone who participated in the 2015 Code Jam!
Cast
Problem A (Costly Binary Search): Written by Petr Mitrichev. Prepared by Ahmed Aly.
Problem B (Campinatorics): Written by David Gómez Cermeño. Prepared by John Dethridge.
Problem C (Pretty Good Proportion): Written by David Arthur. Prepared by Igor Naverniouk.
Problem D (Taking Over The World): Written by David Arthur. Prepared by Igor Naverniouk.
Problem E (Merlin QA): Written by David Arthur. Prepared by Ahmed Aly.
Problem F (Crane Truck): Written and prepared by John Dethridge.
Solutions and other problem preparation and review by Ahmed Aly, John Dethridge, Sumudu Fernando, Jonathan Gunawan, Felix Halim, Adrian Kuegel, Petr Mitrichev, Igor Naverniouk, Anton Raichuk, Jonathan Shen, Ian Tullis, Jonathan Wills, and Onufry Wojtaszczyk.
Analyses by John Dethridge, Jonathan Gunawan, Felix Halim, Pablo Heiber, Risan, and Onufry Wojtaszczyk.
A. Costly Binary Search
Problem
You were asked to implement arguably the most important algorithm of all: binary search. More precisely, you have a sorted array of objects, and a new object that you want to insert into the array. In order to find the insertion position, you can compare your object with the objects in the array. Each comparison can return either "greater", meaning that your object should be inserted to the right of the compared object, or "less", meaning that your object should be inserted to the left of the compared object. For simplicity, comparisons never return "equal" in this problem. It is guaranteed that when your object is greater than some object in the array, it is also greater than all objects to the left of that object; similarly, when your object is less than some object of the array, it is also less than all objects to the right of that object. If the array has n elements, there are n+1 possible outcomes for your algorithm.
In this problem, not all comparisons have the same cost. More precisely, comparing your object with i-th object in the array costs ai, an integer between 1 and 9, inclusive.
What will be the total cost, in the worst case, of your binary search? Assume you follow an optimal strategy and try to minimize the total cost in the worst case.
Input
The first line of the input gives the number of test cases, T. T lines follow. Each of those lines contains one sequence of digits describing the comparison costs ai for one testcase. The size of the array n is given by the length of this sequence.
Output
For each test case, output one line containing "Case #x: y", where x is the test case number (starting from 1) and y is the total binary search cost in the worst case.
Limits
Memory limit: 1 GB.
1 ≤ T ≤ 50.
All digits are between 1 and 9, inclusive.
There are no spaces between digits on one line.
Small dataset
Time limit: 240 seconds.
1 ≤ n ≤ 104.
Large dataset
Time limit: 480 seconds.
1 ≤ n ≤ 106.
Sample
4 111 1111 1111111 1111119
Case #1: 2 Case #2: 3 Case #3: 3 Case #4: 10
B. Campinatorics
Problem
"Summer is finally here: time to relax, have some fun, go outside and enjoy the
nice weather!" says Alice, a very dedicated Ranger working in a popular National Park. During the summer, lots of families take some time
off to camp there and have a good time, and it is Alice's job to accommodate
the visitors.
Alice is in charge of one of the many camps around the park. The camp can be
described as a matrix of size N x N, where each cell has
enough space for at most one tent. In order to arrange the families in the camp,
there are several regulations that Alice needs to follow:
- Only families with 1, 2 or 3 members are allowed in the camp. Also, each tent can contain members of only one family, and families cannot be split across multiple tents.
- For security reasons, Alice doesn't want the rows or columns to be too crowded or too empty, so she wants exactly 3 members in each row and column.
- Also, according to the park's safety policies, there shouldn't be more than 2 tents in any row or column.
Additionally, Alice knows in advance that at least X three-member families will be visiting the camp, and that there will be enough one- or two-member families to fill the rest of the camp.
For example, these are valid arrangements for N = 3 and X = 0:
1 2 0 | 3 0 0 0 1 2 | 0 1 2 2 0 1 | 0 2 1These are not valid arrangements for N = 3 and X = 1:
1 2 0 | 0 3 0 | 1 2 0 | 1 1 1 0 1 2 | 3 0 0 | 0 2 0 | 1 1 1 2 0 1 | 0 0 0 | 2 0 1 | 1 1 1
- The first one is not valid because there should be at least one three-member family.
- The second example is not valid because the number of persons in the third row (and column) is not three.
- The third one is invalid because there are more than three members in the second column (and fewer than three in the second row).
- The last example contains more than two tents per row or column.
Two arrangements A and B are considered different, if a cell in one arrangement contains a tent, but the same cell in the other arrangement doesn't; or if there is a tent in the same cell of both arrangements, but the number of members in that cell in A is different than the number of members in the same cell in B.
Input
The first line of the input contains T, the number of test cases. T test cases follow. Each test case consists of exactly one line with two integers N and X corresponding to the number of rows (and columns) in Alice's camp and the minimum number of three-member families, respectively.
Output
For each test case, output one line containing "Case #X: Y", where X is the test case number (starting from 1) and Y is the number of possible arrangements.
The answer may be huge, so output the answer modulo 109 + 7.
Limits
Memory limit: 1 GB.
1 ≤ T ≤ 200.
0 ≤ X ≤ N.
Small dataset
Time limit: 240 seconds.1 ≤ N ≤ 20.
Large dataset
Time limit: 480 seconds.1 ≤ N ≤ 106.
Sample
3 2 2 3 1 15 0
Case #1: 2 Case #2: 24 Case #3: 738721209
0 3 | 3 0 3 0 | 0 3
C. Pretty Good Proportion
Problem
I have a sequence of N binary digits. I am looking for a substring with just the right proportion of 0s and 1s, but it may not exist, so I will settle for something that's just pretty good.
Can you find a substring where the fraction of 1s is as close as possible to the given fraction F? Output the earliest possible index at which such a substring starts.
Input
The first line of the input gives the number of test cases, T. T test cases follow. Each one starts with a line containing N and F. F will be a decimal fraction between 0 and 1 inclusive, with exactly 6 digits after the decimal point. The next line contains N digits, each being either 0 or 1.
Output
For each test case, output one line containing "Case #x: y", where x is the test case number (starting from 1) and y is the 0-based index of the start of the substring with the fraction of 1s that is as close as possible to F. If there are multiple possible answers, output the smallest correct value.
Limits
Memory limit: 1 GB.
1 ≤ T ≤ 100.
0 ≤ F ≤ 1
F will have exactly 6 digits after the decimal point.
Small dataset
Time limit: 240 seconds.
1 ≤ N ≤ 1000.
Large dataset
Time limit: 480 seconds.
1 ≤ N ≤ 500,000.
Sample
5 12 0.666667 001001010111 11 0.400000 10000100011 9 0.000000 111110111 5 1.000000 00000 15 0.333333 000000000011000
Case #1: 5 Case #2: 5 Case #3: 5 Case #4: 0 Case #5: 6
In Case #1, there is no substring that has exactly a 1-proportion of exactly
D. Taking Over The World
Problem
You and your friend Pinky have a plan to take over the world. But first you need to disable a certain secret weapon.
It is hidden inside a twisted maze of passages (a graph) with one entrance. Pinky is going to be at the vertex with the secret weapon, disabling it. Meanwhile, a security team at the graph entrance will be alerted, and will run through the graph to try to get to Pinky in time to stop him. You are going to be slowing down the security team to give Pinky as much time as possible. It takes one unit of time to traverse any edge of the graph, but you can additionally "obstruct" up to K vertices. It takes one additional unit of time to traverse an obstructed vertex. You will choose to obstruct a set of vertices that slows down the security team by as much as possible.
If the security team will be starting at the graph entrance and is trying to get to the secret weapon vertex, how much time will it take them to get there? Note that you have to commit all your obstructions before the security guards start their journey, and the security guards will know which vertices you have obstructed and will choose an optimal path based on that information.
Obstructing the secret weapon vertex is not useful because that will not delay the guards any further after they have already caught Pinky. Obstructing the entrance, on the other hand, is obviously a good idea.
Input
The first line of the input gives the number of test cases, T. T test cases follow. Each one starts with a line containing N, M, and K. The next M lines each contain a pair of vertices connected by an edge. Vertices are numbered from 0 (the entrance) to
Output
For each test case, output one line containing "Case #x: y", where x is the test case number (starting from 1) and y is the time it will take the security guards to get from the entrance to the secret weapon room.
Limits
Memory limit: 1 GB.
1 ≤ T ≤ 100.
2 ≤ N ≤ 100.
1 ≤ M ≤ N * (N - 1) / 2.
1 ≤ K ≤ N.
There will always be a path from room 0 to room
Small dataset
Time limit: 240 seconds.
It will not be possible to delay the guards by more than 2 time units, compared to the shortest unobstructed path length (using the given K).
Large dataset
Time limit: 480 seconds.
No extra restrictions.
Sample
5 3 2 1 0 1 1 2 3 2 2 0 1 1 2 3 2 3 0 1 1 2 4 4 2 0 1 0 2 1 3 2 3 7 11 3 0 1 0 2 0 3 1 4 1 5 2 4 2 5 3 4 3 5 4 6 5 6
Case #1: 3 Case #2: 4 Case #3: 4 Case #4: 3 Case #5: 5
E. Merlin QA
Problem
Edythe is a young sorceress working in the quality assurance department of Merlin, Inc. -- a magic spell factory. Her job is to test the magic spells that Merlin himself invents. Each spell requires precise amounts of certain ingredients and transforms them into other amounts of other ingredients. Edythe's job is to cast each spell exactly once in order to verify that the spell works correctly.
She can cast a spell only if she has the required amount of each ingredient. If she has already created ingredients of the right type from previous spells, Edythe must use those first. However, if she still needs more ingredients, she is allowed to take them from Merlin's storehouse. She has no ingredients to start with, but at the end, she gets to keep all the extra ingredients that she created and didn't use.
Edythe wants to make as much profit as possible from her apprenticeship! She has to cast each of the N given spells exactly once, but she is free to do so in any order. Assuming that each spell works as expected, which ordering lets her earn the most money in the end?
For example, imagine that the test plan contains the following 3 spells:
- Inputs: $7 worth of gold. Outputs: $5 worth of sulfur.
- Inputs: nothing. Outputs: $10 worth of gold, $10 worth of sulfur.
- Inputs: $3 worth of gold, $20 worth of sulfur. Outputs: $2 worth of toads.
If Edythe were to cast these spells in the order 1, 2, 3, then she would start by fetching $7 worth of gold from the storehouse for spell #1. That would let her cast spells #1 and #2, giving her $10 worth of gold and $15 worth of sulfur. For the final spell, she would need $3 worth of gold and $20 worth of sulfur. She would have to use all of the sulfur she created so far, $3 worth of gold, and $5 more worth of sulfur that she fetched from the storehouse. This would leave her with $9 worth of ingredients at the end ($7 worth of gold and $2 worth of toads).
But there is a better plan. If she cast the spells in the order 3, 1, 2, she would have $27 worth of ingredients at the end ($10 worth of gold, $15 worth of sulfur, and $2 worth of toads).
Input
The first line of the input gives the number of test cases, T. T test cases follow. Each one starts with a line containing N and M. M is the number of kinds of ingredients in the world. Each of the next N lines contains M integers describing a spell. Each integer is the value (or cost) of the corresponding ingredient. Negative integers are the dollar costs of the input ingredients; positive integers are the dollar values of the output ingredients; and zeros denote ingredients that are neither produced nor consumed by the spell. This also implies that no spell can simultaneously consume and produce the same ingredient.
Output
For each test case, output one line containing "Case #x: y", where x is the test case number (starting from 1) and y is the largest value of ingredients Edythe can have at the end.
Limits
Memory limit: 1 GB.
1 ≤ T ≤ 100.
1 ≤ N ≤ 100.
-100 ≤ Each integer in each spell ≤ 100.
Small dataset
Time limit: 240 seconds.
1 ≤ M ≤ 2.
Large dataset
Time limit: 480 seconds.
1 ≤ M ≤ 8.
Sample
2 3 1 1 0 -1 3 3 -7 5 0 10 10 0 3 -20 2
Case #1: 1 Case #2: 27
F. Crane Truck
Problem
You are in a large storage facility, with 240 storage locations arranged in a circle.
A truck with a crane on it moves along the circle of storage locations, picking up or putting down crates according to a program. (The truck has an unlimited supply of crates on board, so it can always put more crates down.)
The program consists of a sequence of these instructions:
b: move back one locationf: move forward one locationu: pick up one crate at the current locationd: put down one crate at the current location(: do nothing): if there is more than one crate at the current location, move back to the most recent ( in the sequence of instructions, and continue the program from there. (This doesn't move the truck.)
- no ( or ) instructions;
- one ( instruction somewhere in the program, followed later by one ) instruction;
- a ( instruction, followed later by a ) instruction, followed later by another (, and again later by another ).
The sample cases contain examples of each of these.
Each storage location begins with one crate, before the crane truck starts running its program.
Mysteriously, if the truck picks up the last crate at a location, another truck instantly comes along and puts down 256 crates there! Similarly, if the truck puts down a crate at a location, and that location then has 257 crates, another truck instantly drives past and picks up 256 of the crates, leaving one behind! So every location always has between 1 and 256 crates.
How many times will the truck move forward or backward before reaching the end of its program?
Input
One line containing an integer T, the number of test cases in the program.
T lines, each containing a crane truck program with up to 2000 characters.
Output
T lines, one for each test case, containing "Case #X: Y" where X is the test case number, and Y is the number of times the truck moves.
Limits
Memory limit: 1 GB.
1 ≤ T ≤ 20.
1 ≤ the length of the program ≤ 2000.
The program is guaranteed to terminate.
Small dataset
Time limit: 240 seconds.
The program will contain at most one pair of ( and ) instructions.
Large dataset
Time limit: 480 seconds.
The program will contain at most two pairs of ( and ) instructions.
Sample
4 ufffdddbbbdd dddd(fdbu)fff dddd(fdddddbu)f(fdddddbu) bf
Case #1: 6 Case #2: 11 Case #3: 49 Case #4: 2
Analysis — A. Costly Binary Search
Let us call the length of the input sequence N. There are N+1 possible "slots" in which the new element can end up — we number them from 0 to N, where 0 is the slot before the first element of a, and N is the slot after the last element of a.
At any point in our search, we will have narrowed down the possible location of the correct slot to an interval of possible slots. We then want to find out which slot in that interval is the correct one; we call this "solving" the interval.
For a given cost C and position X, we want to compute the largest possible interval of slots, beginning at X, which we can solve in cost C or less. Call the rightmost slot of that interval f(C,X). We will compute f using dynamic programming.
Clearly if C=0, then f(C,X)=X and the interval is empty. (Since each comparison costs at least 1, we cannot make any comparisons.)
Otherwise, assume we have an interval [X,Y], where X < Y, that we can solve at a cost no greater than C. The solution must involve an initial comparison at an index i, where i is in [X,Y-1], which costs ai. Then we will have narrowed down the correct slot to either the interval of slots to the left of index i, which is [X,i]; or the interval of slots to the right of index i, which is [i+1,Y].
Each of these intervals must be solvable with a cost no greater than C-ai, i.e., f(C-ai, X) ≥ i, and f(C-ai, i+1) ≥ Y.
We want to find the largest Y for which the above statements hold. To limit the number of possible choices for i and Y, we always use Y=f(C-ai, i+1), since by definition this is the largest possible Y for a given choice of X and i. Also, instead of trying every value of i in [X, f(C-ai, X)], we iterate through each possible value of ai from 1 to 9, and try the largest index i in [X, f(C-ai, X)] with that value. (Smaller indices i with the same value of ai could not produce a larger Y). If there are no usable values of i (because C is too small, or X=N) then f(C,X)=X.
We compute f(C,X) in this way for increasing values of C, until we find the minimal C such that f(C,0)=N. This C is the answer.
The maximum value for the resulting C occurs when every array value is 9, in which case we can't do better than a standard binary search, which takes O(log N) comparisons of cost 9 each. That means computing f(C,X) over a domain of size 9 log N × N. Since the computation at each position takes constant time (we try 9 things), the overall algorithm takes O(N log N) time, with a somewhat large constant because of the two factors of 9 mentioned previously.
Analysis — B. Campinatorics
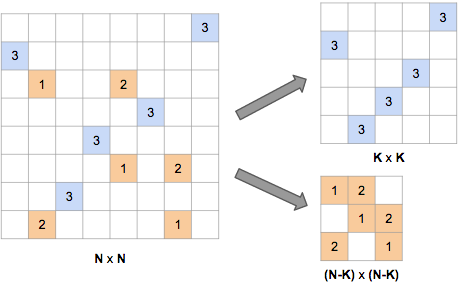
Let N be the size of the grid, and K be the number of 3-family tents. We can decompose the problem of counting the number of arrangements for given values of N and K by noting that we can first choose a set of K rows and K columns to contain the 3-family tents, and the remaining set of N-K rows and N-K columns will contain the 2-family and 1-family tents. (See the diagram above.) The number of arrangements is then the product of the following:
- The number of ways to choose the sets of rows and columns. There are C(N,K)^2 ways of choosing the K rows and columns, where C(N,K) is a binomial coefficient.
- The number of ways to assign the 3-family tents to (row, column) pairs. We can do this assignment by taking a permutation of the columns, and assigning the ith column in the permutation to the ith row in the set of K rows. There are K! such permutations.
- The number of ways to assign the 2-family tents to (row, column) pairs. Similarly to the 3-family tents, there are (N-K)! ways to do this.
- The number of ways to assign the 1-family tents to (row, column) pairs. Not all of the (N-K)! permutations of columns can be used, since we have the additional requirement that we can't use a (row, column) pair in which we've already placed a 2-family tent. To deal with this, we reformulate what we need to do here: for each row X in the set of N-K rows, we need to choose a unique row Y from the same set, find the column C such that there is a 2-family tent at (Y,C), and place a 1-family tent at (X,C). The space at row X, column C is guaranteed not to already have a tent. So we need a permutation of the N-K rows, with the additional requirement that no row is unchanged by the permutation – that is, for each row X, we choose a row different to X as the corresponding row Y in the permutation. Such a permutation is called a derangement. The number of derangements of size N-K is written !(N-K).
Now, the product of all these terms is:
C(N,K)^2 × K! × (N-K)! × !(N-K) = N!^2 / (K! × (N-K)!) × !(N-K).
We get the answer to the problem by summing this value (mod 10^9 + 7) for all values of K from X to N.
We can do that efficiently by precomputing K!, 1/K!, and !K mod 10^9 + 7 for all values of K up to N. Factorials can be computed with the obvious recurrence. 1/K! mod 10^9+7 can be computed from K! with the extended Euclidean algorithm or using Fermat's little theorem. !K can be computed with the recurrence:
!1 = 0, !2 = 1, !X=(X-1)(!(X-1)+!(X-2)).
Analysis — C. Pretty Good Proportion
A brute force O(N2) strategy will work for the Small dataset: for each position, compute the cumulative number of ones seen so far, and then check every possible pair of start and end points in the sequence. But N can be up to half a million in the Large dataset!
We will read the string from left to right and keep track of the number of ones Oi seen after reading the first i digits. We will examine each i between 0 and N, inclusive, so that we consider both the empty prefix and the full string. We will maintain an initially empty set of points, and for each i, we will add pi = (i, F × i - Oi) to the set. Notice that the fraction of ones in the substring starting at position i+1 and ending at position j is (Oj - Oi) / (j - i), and the difference from F is F - (Oj - Oi) / (j - i) = (F(j - i) - Oj + Oi) / (j - i), which is the slope between pi and pj. Finding the pi and pj that minimize the absolute value of this slope is equivalent to solving the problem.
It is hard to see (but easy to prove) that the slope with minimal absolute value occurs between two points that are consecutive in sorted order by y coordinate: if there is a point r that has a y coordinate between the y coordinates of two other points p and q, the slope between p and q (call it s) is the weighted average of the slope between p and r and the slope between q and r; either those two slopes are equal to s, or one of them must be less than s. A more visual way to see this is to draw the segment p-q and place r on it. That makes all three slopes equal. Moving r horizontally clearly makes the slope of one of the segments pr and qr increase and the slope of the other one decrease.
This insight saves us from checking all pairs of points, and reduces the time complexity of the problem to O(N log N), which is imposed by the single sorting operation.
Analysis — D. Taking Over The World
Let G be the graph, s be the entrance node, and t be the node with the secret weapon.
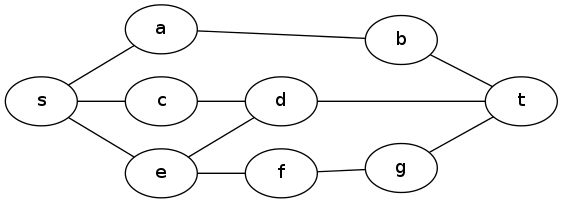
For the small input, we start by finding the shortest distance through the graph from s to t using, e.g., Dijkstra’s algorithm. Call this distance L. If K=0, we cannot obstruct anything, so the answer is simply L.
Now assume K > 0. It is always advantageous to obstruct s, so let’s begin by doing this: reduce K by one, and increase L by 1. Next we want to find if we can increase L one more by obstructing other nodes. This means that every shortest path from s to t must have another obstructed node in it (other than s). We can turn this into a standard graph problem in the following way -- take the subgraph of G which contains all the edges and nodes in a shortest path from s to t. Make each edge directed, pointing in the direction of the path it belongs to.
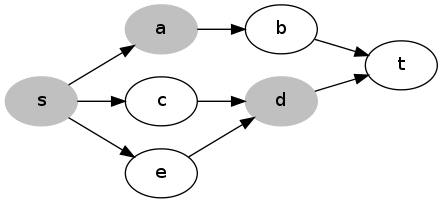
Now, if there is a set of up to K nodes we can obstruct that covers all the paths, for example a and d in the diagram above, then removing those nodes cuts the graph, separating s and t. So we need to solve the minimum vertex cut problem on this graph and check if the cut has size at most K. To do this, we convert it to an edge cut problem by changing the graph so that each vertex except s and t is split into two nodes, with an edge of capacity 1 between them. The original edges are converted to infinite-capacity edges, as in the diagram below:
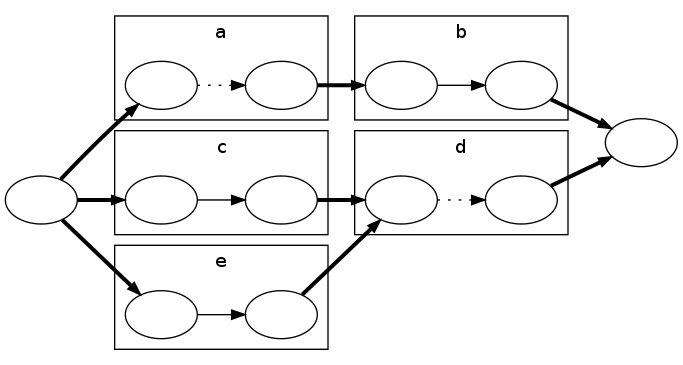
A vertex cut of K vertices in the earlier graph will correspond to an edge cut of capacity K in this new graph. In the example above, cutting the edges between the pairs of nodes for a and d cuts the graph. Now we have a minimum edge cut problem, and we can apply the max flow / min cut theorem — the size of the minimum edge cut is the size of the maximum flow — and use one of the standard algorithms for finding the maximum flow. If there exists a flow that is larger than K, then the answer is L, otherwise the answer is L+1.
Now for the large input. We will check, for successive values of X starting at 1, whether it is possible to obstruct up to K nodes in order to stop the guards traveling from node s to node t in time ≤ X. We call this proposition P(X). The first value of X where P(X) is false is the answer.
To determine the truth of P(X) for a specific X, we construct a new graph G', which has a node for each triplet (v, x, b) where v is a vertex in G, x is an integer between 0 and X, and b is true or false. Node (v, x, b) represents that the guards can reach node v in time x if b is false, or reach node v and surpass the obstruction in time x, if b is true. We add the following edges:
- (v, x, false) to (v, x, true), for each v and x. (This means a free pass through an obstruction; removing one of these is equivalent to not adding an obstruction at v, if you remove the one for the appropriate x.)
- (v, x, false) to (v, x+1, true), for each v and x < X-1. (a non-free pass through an obstruction) (v, x, false) to (v, x+1, false), for each v and x < X; (Stay put for 1 time unit.)
- (v, x, true) to (w, x+1, false), for each x < X and each edge vw in G. (Transverse an edge in 1 time unit).
Let σ be the node (s, 0, false), and τ be the node (t, X, false). Assuming no nodes are obstructed, we can see that the following properties hold for G':
- There is a path from σ to (v, x, false) if and only if the guards can arrive at node v at a time ≤x.
- There is a path from σ to (v, x, true) if and only if the guards can leave node v at a time ≤x.
- There is a path from σ to τ if and only if it is possible for the guards to travel from s to t in G in time ≤ X.
If some nodes in G are obstructed, the properties above still hold if we delete all the edges in set 1 of the four sets above, where the corresponding v is one of the obstructed nodes. So P(X) is equivalent to a graph cut problem -- determining whether we can disconnect σ and τ by cutting the set 1 edges for up to K nodes of G.
In G, after we choose the nodes to obstruct, for each node v, all of the optimal paths from s to t that pass through v do so at the same time, so the ability to obstruct v was only "useful" at a given time time. So if our ability to obstruct a node were changed to an ability to obstruct a node at just one particular time, the result would be no different. Similarly, in G', after removing a set of edges, for each v, there will only be at most one x for which it was "useful" to cut the edge from (v, x, false) to (v, x, true).
We can prove this more formally: let A be a set of edges from set 1 that have been removed to disconnect σ and τ, and say that it contains the edges from (v, x0, false) to (v, x0, true) and from (v, x1, false) to (v, x1, true) for some v and x0 < x1. If both edges are necessary, then there must be paths from σ to (v, x0, false) and (v, x1, false), and paths from (v, x0, true) and (v, x1, true) to τ. But now there is a path from σ to τ via (v, t0, false), (v, t1-1, false), and (v, t1, true), so σ and τ are not disconnected at all! So for any set of edges A which disconnect σ and τ, there is a subset of A which disconnects σ and τ and has at most one edge cut for any node in G.
This means that P(X) is equivalent to being able to disconnect σ and τ by cutting up to K edges from set 1. As with the small input, this is equivalent to a max flow problem, with unit capacity on the set 1 edges and infinite capacity on the others.
We can solve all these flow problems quite quickly, since we do not need to recompute the maximum flow from scratch each time we increase X — we just add one more "layer" of nodes and edges for the new X value, and update the flow.
Analysis — E. Merlin QA
Every spell in the spell-testing procedure can be interpreted as an M-dimensional vector, and the current state of Edythe’s inventory is also an M-dimensional vector (initially an all-zero vector). Casting a spell is equivalent to adding the vector describing the spell to the vector describing Edythe’s inventory, and then changing all the negative values in Edythe’s inventory to zero (this corresponds to retrieving the exact necessary amount from Merlin’s storehouse). Edythe is aiming to maximize the sum of all the coordinates at the end.
Note that even if we allowed Edythe to zero a coordinate of the vector describing her inventory at any time, it would never be advantageous to zero it when it is positive, and it would never be disadvantageous to zero it when it is negative - so the final answer will not change if we give Edythe full freedom over when and which coordinates of her inventory get zeroed. We will solve this less constrained problem from now on.
Notice that it never makes sense to zero a given coordinate more than once, since the last zeroing will make the previous ones irrelevant anyway. So from now on, we will solve an equivalent problem — given a list of spells, and the opportunity to zero each coordinate of the accumulated sum exactly once, at any point of the summation, maximize the final sum of all the coordinates. Thus, a solution candidate can be equivalently described as a permutation of the N spells, plus the moments in time at which we zero each coordinate.
Let’s fix the order in which coordinates get zeroed (we will later iterate over all M! possible orderings), and look at one particular spell. We will try to figure out the best time to cast it. If we cast it before any coordinate is zeroed, then the result will be the same as if we had not cast it at all — every coordinate will eventually be reset to zero after casting the spell anyway. Now assume we cast it when k coordinates have already been zeroed, and the others have not. Compared to the situation when we don’t cast it at all, the end result is that the values of the spell on the k already-zeroed coordinates will be added to the final values of these coordinates, and so the sum of these values will be added to Edythe’s final result. So, for every spell, we check each of the M+1 possibilities for k, and choose the one which will give the largest contribution to the final result.
So a solution can work as follows: take every possible ordering P of the M dimensions. For each ordering P, iterate over all the spells, and for each spell find which of the M+1 values for k will cause the spell to contribute the most to the final result. The sum of all these contributions for all the spells is the best possible score for this ordering P; the maximum score over all orderings is the answer. The runtime is O((M+1)! N), which will easily run in time for N = 100 and M = 8.
Analysis — F. Crane Truck
In this problem, we are given a version of a small programming language, and we are required to track the number of operations executed as a program runs. The memory is a circular array of 240 positions, and all values are considered modulo 256 (for convenience, we shift values one position to make them go [0,255]). The program can run for a really long time, so our approach is to simulate it efficiently by bundling together many of those operations. The actual code is long and complicated — this is the last problem in a finals round, after all — so we just present an overview of the main idea.
The program can be factorized into 5 parts: A(B)C(D)E. Some of these may be empty; in particular, in the Small dataset, D and E are always empty. Each sequence of simple instructions can be translated, via simulation, into a complex instruction of the form:
- Let i be the current position of the truck.
- Add some xj to position i+j for j in [-2000, 2000]. (2000 is the maximum length of each part.)
- Move the current position to i+k, where k is also in [-2000, 2000].
Running A
After executing A, only values within 2000 of the starting position can be modified. Let us call the area within 2000 of the starting position the "red" area.
Running (B)
After running B several times, we can either finish or move out of the red area. After several more runs outside, the memory outside the red area will start to look periodic with period |k| and we are going to keep moving the current position according to B's k in the 3rd step until we come back to the red area on the other side, completing a full circle. So, we bundle together all the instructions required to complete the circle and we represent the non-red area as a repetition of a period with length at most 4001 (the range of j's in step 2). We can keep doing this in this way until the loop finishes (which is guaranteed). Notice that after at most 4001 complete circles around the memory, we are going to repeat the initial positions inside the red area. And once we've done that, we are going to start repeating the values there, so we can't do more than 4001 × 256 loops without it being an infinite loop (which is forbidden by input constraints).
Running C
After that, we can simulate C, which can modify the range [-4000, 4000] because the previous loop finished within 2000 of the starting point. Let us call that the "green" area.
Running (D)
When running D, something similar to running B happens, but the memory outside the green area is now the sum of two periodic things with period of size at most 4001, so it can have a period of up to 40012. Luckily, this is still small enough to simulate, and other than that, we can proceed with the same idea as we did for B.
Running E
For E, we proceed again in the same fashion. In this case, the non-periodic area's size can increase to a couple of millions due to the quadratic size of the last period, but that is still well under the memory limits.