Google Code Jam Archive — Round 3 2015 problems
Overview
Round 3 was very tough! The highest score was 73, which four coders reached by solving problems A through D. The lowest score of any of the advancers was only 50!
Problems A and B, Fairland and Smoothing Window, were both relatively easy optimization problems. The problems got much harder from there. Runaway Quail was a dynamic programming problem, where it was not at all easy to find a polynomial-time solution. Log Set required some math and some more dynamic programming. And for a change of topic, River Flow was a signal processing problem.
Congratulations to all our finalists! We're looking forward to the finals in Seattle this August!
Problem A. Fairland written by Brian Nachbar. Prepared by Carlos Guía.
Problem B. Smoothing Window written by Igor Naverniouk. Prepared by Steve Thomas.
Problem C. Runaway Quail written by Ian Tullis. Prepared by Steve Thomas.
Problem D. Log Set written by David Arthur. Prepared by Yiming Li.
Problem E. River Flow written by Steve Thomas. Prepared by Yiming Li.
Solutions and other preparation by Petr Mitrichev, John Dethridge, Yiming Li, Jonathan Wills, Ahmed Aly, Ian Tullis, David Arthur, Igor Naverniouk, Jonathan Gunawan, Steve Thomas, and Carlos Guia.
A. Fairland
Problem
The country of Fairland has very strict laws governing how companies organize and pay their employees:
- Each company must have exactly one CEO, who has no manager.
- Every employee except for the CEO must have exactly one manager. (This means that the org chart showing all of the employees in a company is a tree, without cycles.)
- As long as an employee is working for the company, their manager must never change. This means that if a manager leaves, then all of the employees reporting to that manager must also leave.
- The CEO must never leave the company.
- Every employee receives a salary -- some amount of Fairland dollars per year. An employee's salary must never change.
- Different employees may have different salaries, and an employee's salary is not necessarily correlated with where in the org chart that employee is.
- The difference between the largest salary and the smallest salary in the whole company must be at most D Fairland dollars.
Marie is the CEO of the Fairland General Stuff Corporation, and she has to ensure that her company complies with the new law. This may require laying off some employees. She has the list of the company's employees, their managers, and their salaries. What is the largest number of employees she can keep, including herself?
Input
The first line of the input gives the number of test cases, T. T test cases follow. Each case begins with one line containing two space-separated integers N (the number of employees) and D (the maximum allowed salary difference). This is followed by one line with four space-separated integers (S0, As, Cs, Rs) and then another line with four more space-separated integers (M0, Am, Cm and Rm). These last eight integers define the following sequences:- Si+1 = (Si * As + Cs) mod Rs
- Mi+1 = (Mi * Am + Cm) mod Rm
Output
For each test case, output one line containing "Case #x: y", where x is the test case number (starting from 1) and y is the largest number of employees Marie can keep at the company, including herself, such that all of laws 1-7 are obeyed.
Limits
Memory limit: 1 GB.
0 ≤ S0 < Rs.
0 ≤ M0 < Rm.
0 ≤ As, Am ≤ 1000.
0 ≤ Cs, Cm ≤ 109.
Small dataset
Time limit: 240 seconds.
1 ≤ N ≤ 1000.
1 ≤ D ≤ 1000.
1 ≤ Rs, Rm ≤ 1000.
Large dataset
Time limit: 480 seconds.
1 ≤ N ≤ 106.
1 ≤ D ≤ 106.
1 ≤ Rs, Rm ≤ 106.
Sample
3 1 395 18 246 615815 60 73 228 14618 195 6 5 10 1 3 17 5 2 7 19 10 13 28 931 601463 36 231 539 556432 258
Case #1: 1 Case #2: 3 Case #3: 5
Here is the org chart for Case #2:
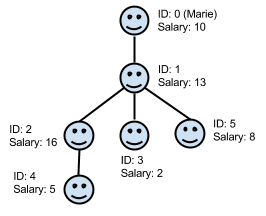
The optimal strategy is to save employees 0, 1, and 5 (who have salaries of 10, 13, and 8, respectively). It is not possible to save employee 2, for example, because her salary is more than 5 away from employee 0's salary of 10; since employee 0 cannot be laid off, employee 2 must be laid off (along with all employees who report to her).
If you want to check your sequences for employees 1 through 5, they are:
S: 13, 16, 2, 5, 8
M: 17, 3, 13, 14, 16
Manager numbers: 17 % 1 = 0, 3 % 2 = 1, 13 % 3 = 1, 14 % 4 = 2, 16 % 5 = 1
B. Smoothing Window
Problem
Adamma is a climate scientist interested in temperature. Every minute, she records the current temperature as an integer, creating a long list of integers:
This morning, she decided to compute a sliding average of this list in order to get a smoother plot. She used a smoothing window of size K, which means that she converted the sequence of N temperatures into a sequence of
Unfortunately, Adamma forgot to save the original sequence of temperatures! And now she wants to answer a different question -- what was the difference between the largest temperature and the smallest temperature? In other words, she needs to compute
After some thinking, Adamma has realized that this might be impossible because there may be several valid answers. In that case, she wants to know the smallest possible answer among all of the possible original sequences that could have produced her smoothed sequence with the given values of N and K.
Input
The first line of the input gives the number of test cases, T. T test cases follow; each test case consists of two lines. The first line contains integers N and K separated by a space character. The second line contains integer values
Output
For each test case, output one line containing "Case #x: y", where x is the test case number (starting from 1) and y is the smallest possible difference between the largest and smallest temperature.
Limits
Memory limit: 1 GB.
1 ≤ T ≤ 100.
2 ≤ K ≤ N.
The sumi will be integers between -10000 and 10000, inclusive.
Small dataset
Time limit: 240 seconds.
2 ≤ N ≤ 100.
Large dataset
Time limit: 480 seconds.
2 ≤ N ≤ 1000.
2 ≤ K ≤ 100.
Sample
3 10 2 1 2 3 4 5 6 7 8 9 100 100 -100 7 3 0 12 0 12 0
Case #1: 5 Case #2: 0 Case #3: 12
0.5, 1.0, 1.5, 2.0, 2.5, 3.0, 3.5, 4.0, 4.5
The integer sequence that gives the smallest difference is:
0, 1, 1, 2, 2, 3, 3, 4, 4, 5
Note that the sequence:
0.5, 0.5, 1.5, 1.5, 2.5, 2.5, 3.5, 3.5, 4.5, 4.5
Would give the same smoothed sequence with a maximum difference of 4, but this is not a valid answer because the original temperatures are known to have been integers.
In Case #2, all we know is that the sum of the 100 original values was -100. It's possible that all of the original values were exactly -1, in which case the difference between the largest and smallest temperatures would be 0, which is as small as differences get!
In Case #3, the original sequence could have been:
-4, 8, -4, 8, -4, 8, -4
C. Runaway Quail
Problem
Oh no -- your N pet quail have all gotten loose! You are currently at position 0 on a line; the ith quail starts off at some nonzero integer (positive or negative) position Pi on that line, in meters, and will continuously run away from you at a constant integer speed of Si meters per second. You can run at a constant integer speed of Y meters per second, and can change direction instantaneously whenever you want. Note that quail constantly run away from you even if you are not running toward them at the time. Whenever you occupy the same point as a quail, that quail is caught (this takes no additional time).
What is the minimum number of seconds it will take you to catch all of the quail?
Input
The first line of the input gives the number of test cases, T. T test cases follow. Each begins with one line with two space-separated integers Y, your speed, and N, the number of quail, and is followed by two more lines with N space-separated integers each. The first of these gives the positions Pi of the quail, and the second gives the speeds Si.
Output
For each test case, output one line containing "Case #x: y", where x is the test case number (starting from 1) and y is the minimum number of seconds needed to catch all the quail.
y will be considered correct if it is within an absolute or relative error of 10-6 of the correct answer. See the FAQ for an explanation of what that means, and what formats of real numbers we accept.
Limits
Memory limit: 1 GB.
1 ≤ T ≤ 100.
2 ≤ Y ≤ 1000.
-107 ≤ Pi ≤ 107; no Pi is 0.
1 ≤ Si < Y.
Small dataset
Time limit: 240 seconds.
1 ≤ N ≤ 25.
Large dataset
Time limit: 480 seconds.
1 ≤ N ≤ 500.
Sample
2 4 3 -3 -6 -9 3 2 1 2 2 1 -1 1 1
Case #1: 3.000000 Case #2: 5.000000
In Case #2, one optimal strategy is to run to the left until the second quail is caught at -2 m, which takes one second, and then run to the right in pursuit of the first quail, which you will catch at 6 m, taking four more seconds.
D. Log Set
Problem
The power set of a set S is the set of all subsets of S (including the empty set and S itself). It's easy to go from a set to a power set, but in this problem, we'll go in the other direction!
We've started with a set of (not necessarily unique) integers S, found its power set, and then replaced every element in the power set with the sum of elements of that element, forming a new set S'. For example, if S = {-1, 1}, then the power set of S is {{}, {-1}, {1}, {-1, 1}}, and so S' = {0, -1, 1, 0}. S' is allowed to contain duplicates, so if S has N elements, then S' always has exactly 2N elements.
Given a description of the elements in S' and their frequencies, can you determine our original S? It is guaranteed that S exists. If there are multiple possible sets S that could have produced S', we guarantee that our original set S was the earliest one of those possibilities. To determine whether a set S1 is earlier than a different set S2 of the same length, sort each set into nondecreasing order and then examine the leftmost position at which the sets differ. S1 is earlier iff the element at that position in S1 is smaller than the element at that position in S2.
Input
The first line of the input gives the number of test cases, T. T test cases follow. Each consists of one line with an integer P, followed by two more lines, each of which has P space-separated integers. The first of those lines will have all of the different elements E1, E2, ..., EP that appear in S', sorted in ascending order. The second of those lines will have the number of times F1, F2, ..., FP that each of those values appears in S'. That is, for any i, the element Ei appears Fi times in S'.
Output
For each test case, output one line containing "Case #x: ", where x is the test case number (starting from 1), followed by the elements of our original set S, separated by spaces, in nondecreasing order. (You will be listing the elements of S directly, and not providing two lists of elements and frequencies as we do for S'.)
Limits
Memory limit: 1 GB.
1 ≤ T ≤ 100.
1 ≤ P ≤ 10000.
Fi ≥ 1.
Small dataset
Time limit: 240 seconds.
S will contain between 1 and 20 elements.
0 ≤ each Ei ≤ 108.
Large dataset
Time limit: 480 seconds.
S will contain between 1 and 60 elements.
-1010 ≤ each Ei ≤ 1010.
Sample
5 8 0 1 2 3 4 5 6 7 1 1 1 1 1 1 1 1 4 0 1 2 3 1 3 3 1 4 0 1 3 4 4 4 4 4 3 -1 0 1 1 2 1 5 -2 -1 0 1 2 1 2 2 2 1
Case #1: 1 2 4 Case #2: 1 1 1 Case #3: 0 0 1 3 Case #4: -1 1 Case #5: -2 1 1
In Case #4, S = {-1, 1} is the only possible set that satisfies the conditions. (Its subsets are {}, {-1}, {1}, and {-1, 1}. Those have sums 0, -1, 1, and 0, respectively, so S' has one copy of -1, two copies of 0, and one copy of 1, which matches the specifications in the input.)
For Case #5, note that S = {-1, -1, 2} also produces the same S' = {-2, -1, -1, 0, 0, 1, 1, 2}, but S = {-2, 1, 1} is earlier than {-1, -1, 2}, since at the first point of difference, -2 < -1. So
-1 -1 2 would not be an acceptable answer. 1 -2 1 would also be unacceptable, even though it is the correct set, because the elements are not listed in nondecreasing order.
E. River Flow
Problem
The city you live in lies on the banks of the spectacular Binary river. The water in the river comes from some tributary streams that start way up in the mountains. Unfortunately for your city, there are farmers who live in the mountains who need to use up some of the water in the tributary streams for their crops.
Long ago, the city struck a deal with the farmers to allow them to farm while keeping the river flowing: each farmer was allowed to use the water for her crops exactly half the time. The farmers would alternately divert water for their crops for a day and leave the water to run down the river for a day. The result was a disaster! Because the farmers' water usage was synchronized, with everyone either diverting or not diverting water at the same time, the river would run dry every other day and then flood the city the next.
To solve this problem, the city went back to the farmers and asked each one to choose some integer power of 2 (this is the Binary River after all) between 1 and D, inclusive, and toggle her water usage (either start or stop collecting water) every time that number of days has elapsed. (Not every power of 2 between 1 and D was necessarily represented, and multiple farmers may have selected the same integer. 1 counts as a power of 2.) The idea was that this would make the water usage more even overall, and so the droughts and flooding would become less frequent.
This all happened a long time ago, and you and the other citizens have recently become suspicious that the farmers aren't sticking to the agreement. (You're not even sure how many farmers there are right now!) However, the only data you have is N days' history of the amount of water flowing through the city. Can you tell if the farmers are being honest?
Each tributary stream has flow 1 and the flow through the main river is the sum of all the tributary streams that are not being diverted for farming. (Before looking at the records, you don't know how many tributary streams there are.) At most 1 farmer will divert the water from each tributary stream, but there may be some tributary streams from which no farmers ever divert water. Note that the farmers started their water diversion cycles long before the city started recording the water flow, but there is no guarantee that they all started on the same day.
Input
The first line of the input gives the number of test cases, T. T test cases follow. Each test case starts with a line containing two space-separated integers N and D. The next line contains N space-separated integers, with the ith integer di giving the river flow on the ith day.
Output
For each case, output one line containing "Case #x: M", where x is the test case number (starting from 1) and M is the smallest number of farmers who could be diverting water from the streams according to the described model, consistent with the observed flow through the river.
If you are sure that at least one farmer is active, but there is no way that the supplied input could be explained by farmers obeying the rules, then output CHEATERS! instead of a number.
Limits
Memory limit: 1 GB.
1 ≤ T ≤ 50.
D will be a power of 2.
1 ≤ D ≤ floor(N / 2).
Small dataset
Time limit: 240 seconds.
1 ≤ N ≤ 50.
0 ≤ di ≤ 5.
Large dataset
Time limit: 480 seconds.
1 ≤ N ≤ 5000.
0 ≤ di ≤ 1000.
Sample
4 5 2 2 2 2 2 2 6 2 1 1 1 0 0 0 8 4 2 1 1 0 0 1 1 2 8 4 0 1 1 3 1 2 2 2
Case #1: 0 Case #2: CHEATERS! Case #3: 2 Case #4: 3
Explanation
Case #1 is consistent with two tributary streams with no farmers drawing from them.
Case #2 could a single tributary stream being diverted every 4 days. However, D is 2 in this case, so this farmer is breaking the agreement.
Case #3 could be two farmers each with a diversion cycle of 4 days.
Case #4 could be three farmers with diversion cycles of 1, 2 and 4 days.
Analysis — A. Fairland
We need to find a salary X such that all salaries at the company are between X and X+D, and the number of remaining employees is maximized.
If employee i is kept, then X must be in the interval [Si-D, Si]. Not only that, but X must be in the interval [Sj-D, Sj] for each employee j who is the manager of employee i, or the manager of the manager of employee i, and so forth. So for each employee, we want to find the intersection of all those intervals. This is easily done using a preorder traversal of the tree, computing the intersection of all the intervals in the path from the root node to the current node. (If the intersection is empty, we can't keep that employee.)
Now we want to find the maximum number of intervals that overlap at any point. Let the interval we get for employee i be [Ai, Bi]. Create an array of pairs of integers, with two pairs for each employee: one containing (Ai, +1) and the other containing (Bi, -1). Sort this array by the first numbers of the pairs, breaking ties using the second number, by putting entries with +1 before those with -1. Then we start a counter at zero, and iterate through the array in sorted order. Add the second number of each pair to the counter. The maximum value of the counter is the answer to the problem.
Analysis — B. Smoothing Window
One approach towards a solution is to construct the temperature sequence that begins with K-1 zeroes, followed by a single pass through all the N-K+1 smoothing window sums to fill in the rest of the sequence. For example, running this construction for the sum array “0 12 0 12 0” with K = 3 (from the third sample case) produces the sequence “0 0 0 12 -12 12 0”, where the difference between the maximum and minimum temperatures is 24. To reach a sequence that minimizes this difference, we tweak some values in the sequence as explained below.
Let’s define GROUP(i) where (0 ≤ i < K) as the group containing the (i % K)-th temperatures in the sequence. The sequence “0 0 0 12 -12 12 0” above is grouped as follows:
- “0 12 0” from the first, fourth, and seventh temperatures
- “0 -12” from the second and fifth temperatures
- “0 12” from the third and sixth temperatures
Changing the i-th temperature by Z degrees means that we need to compensate for this addition with other temperatures in the sequence. One way is by adding Z to the other temperatures in the same group, and subtracting Z from all the temperatures in another group. For example, to increase the first temperature reading by 3 degrees, we also increase the fourth and seventh temperature readings by 3, and reduce the temperatures in the second (or third) group by 3. The resulting sequence is “3 -3 0 15 -15 12 3”. Notice that its sum array stays the same: “0 12 0 12 0”.
Now let’s define:
- lo(i) as the minimum element in GROUP(i)
- hi(i) as the maximum element in GROUP(i)
- interval(i) as a range [lo(i), hi(i)]
- SHIFT(i, y) as an operation that adds y to each member of GROUP(i).
We can remodel the original problem as follows:
You are given K intervals, where the i-th interval spans from lo(i) to hi(i). You can perform any number of interval adjustments by choosing i, j, and y (0 ≤ i, j < K), shifting the i-th interval by y (i.e., SHIFT(i, y)), and shifting the j-th interval by -y (i.e., SHIFT(i, -y)). Find a sequence of adjustments (where order doesn’t matter) that minimizes the covering range of all intervals, where the covering range of the intervals is max{hi(i)} - min{lo(j)} for all 0 ≤ i, j < K. The minimum covering range is equivalent to the smallest possible difference between the minimum and maximum temperatures in the original problem.
Another important insight is that the shifting can be done independently and can be aggregated. That is, we can accumulate all positive shifts and do it in bulk, similarly with the negative shifts. Therefore, we can “normalize” all intervals by shifting them such that the lower bound of all intervals becomes 0. Denote Q to be the total sum of shifts, which is the sum of all lo(i) where 0 ≤ i < K. For example, if we have two intervals [-10, -8] and [333, 777], after normalization they become [0, 2] and [0, 444] with Q = -10 + 333 = 323. Finally, we have to shift back the normalized intervals by Q degrees, but with the flexibility to distribute the shifts such that the covering range of all intervals is minimized.
Notice that if we increment (or decrement) all the intervals by one, the relative positioning of each interval to one another won't change and thus it does not change the covering range of the intervals. Using this insight, we can reduce Q to Q % K by distributing the excess shifts Q evenly among the intervals without affecting the final answer. When Q is negative we can keep adding K to Q until it is non-negative.
Suppose we have three normalized intervals [0, 4], [0, 9], and [0, 7], and the total sum of shifts Q is 40. We can distribute back 39 shifts evenly to all three intervals where each interval is shifted by 13, ending with [13, 17], [13, 22], and [13, 20]. Then, we can shift all of them down back to [0, 4], [0, 9], [0, 7] without changing their relative positioning and and we are left with Q = 1.
Finally, we must distribute back the remaining shifts to the intervals and minimize the covering range of all intervals.
Suppose that L is the size of the largest interval. If Q = 0, then there is no excess shift to distribute, and the minimum covering range is L. Otherwise, we can assign L - (hi(i) - lo(i)) excess shifts to interval i without changing the answer. Using the previous example, the current minimum difference is L = 9. Without changing the minimum covering range, we can assign 1 excess shift to interval [0, 4], and get [1, 5].
If there are still some excess shifts remaining, it means we cannot distribute any more excess shifts without increasing the minimum covering range. Increasing the minimum covering range by 1 will make room for distributing K more excess shifts, which is enough for the remaining Q (since Q = sum of shifts % K, and thus it is less than K).
The complexity of this solution is O(N).
Analysis — C. Runaway Quail
The optimal strategy will consist of running either to the left or right until we catch a particular quail, changing direction, then running until we catch a particular quail on the other side, changing direction again, etc., until we have caught every quail. Changing direction at a time other than when catching a quail would be wasteful.
Consider a partial solution where we have caught some of the quail on each side, and returned to the origin. For each side, let Q be the fastest quail we have not caught. (To simplify the analysis, if there is more than one quail on the same side with the same speed, we ignore all but the farthest one.) Each other quail R on that side must fall into one of these categories:
- R is faster than Q. In this case, R has already been caught.
- R is slower than Q, and is farther away. R cannot have been caught in this case, because we would have had to run past Q to get to R.
- R is slower than Q, and is not farther away. In this case, we might have already caught R, or we might not. But it doesn't affect our solution — if we have not yet caught R, we will run past R when we go to catch Q anyway.
So we can solve this problem with dynamic programming, where the states only need to include the identity of the fastest uncaught quail in each direction. We will keep the fastest time at which we can achieve each state we generate.
For each state, starting from the initial state where we have caught nothing, we try running in either direction until we catch the fastest uncaught quail in that direction, and then run back to the origin. We also try running to catch each quail farther than the fastest uncaught quail in each direction, and then running back. For each of these options, we compute the new fastest uncaught quail in the direction we ran, which will tell us what the new state is when we return to the origin. If we have achieved the new state with a faster time than we had for it before, we update the time for that state.
Whenever we generate the state where every quail has been caught, we check the time at which we caught the last quail. The fastest of these times is the answer.
Analysis — D. Log Set
Let x be the largest element of S'. Then x is the sum of all of the positive elements of S, and none of its negative elements.
Let y be the second-largest element of S'. Either this is the sum of all but the smallest of the non-negative elements, or it is the sum of all of the non-negative elements and the smallest negative element. So if d = x-y, then the smallest magnitude of any element in S is d — either d ∈ S or -d ∈ S.
These two cases are basically identical. Consider the process of building every subset of S, and finding the sum of each of those subsets. To build a subset, we consider each element of S, and either include it in the subset or not. If we include it, the sum increases by the value of the element. If we don't include it, the sum increases by zero. So in the case where d is an element of S, we will be choosing between adding 0 and adding d to the sum. If -d is an element of S, we will be choosing between adding -d and adding 0. These situations are equivalent, except that every element of S' is offset by a constant depending on whether d or -d is in S.
We can now scan through S' and match elements into pairs that are d apart, and keep only the smallest of each pair. Then we can recursively apply this procedure to get the magnitudes of all the other elements of S.
When we are done, we have the magnitudes of the elements of S. Next we need to figure out which elements are positive and which are negative. First, make them all negative. The largest element of S' will be zero in this case. Then we need to choose which elements to change from negative to positive in order to make the largest element of S' equal to x. This is a Subset Sum problem, with required sum x, and elements equal to the magnitudes. This is easily solvable with dynamic programming — the number of unique sums, and hence the number of states in the dynamic program, is guaranteed to be small because the number of unique values in S' is small.
Analysis — E. River Flow
Assume the farmers are not cheating. The river flow data is periodic, with period 2D.
Let xi be di - di-1 when i>1, and x1 = d1 - d2D. xi represents the difference in flow between day i and the previous day in the 2D-day cycle.
Each farmer's actions change xi in the following way. Let the first time a farmer changes between diverting water and allowing it to flow, or vice-versa, be T, and let the number of days for which that farmer performs the same action be P. At times T, T+P, T+2P, etc., the farmer will alternate between adding 1 to xi and subtracting 1 from xi. (Whether it adds 1 or subtracts 1 first depends on whether the farmer is diverting water or allowing it to flow at the start of the 2D-day cycle). For example, a farmer that starts diverting water at time 3, and changes every 8 days, contributes -1 to x3, +1 to x11, -1 to x19, +1 to x27, etc.
We can assume that if two farmers share the same T and P, they either both start the cycle diverting water or both start the cycle allowing it to flow. If they were performing different actions, we could remove the two farmers and their tributaries, and get the same data.
Now consider the quantity F(T,P) = xT - xT+P + xT+2P - xT+3P + XT+4P - ... for some T and P. Any farmers with those values of T and P will each contribute 2D/P or -2D/P to F(T,P), depending on which action they perform first. Any farmers with a different value of T or P will contribute zero to F(T,P). So the number of farmers for T and P is |F(T,P)| * P / 2D, and the sign of F(T,P) tells us their initial action.
We can try every valid value of T and P to find out how many farmers of each type there are. Once we know this information, we can check that the original data matches it for some number of tributaries. If it does not, we output "CHEATERS!", otherwise we output the number of farmers.