Google Code Jam Archive — Round 2 2013 problems
Overview
In this round, rng..58 took an early lead by solving problem B while most other contestants were working on A. Soon after, fellow Japanese contestants hos.lyric and komaki jumped to the top with problems B and C solved, also skipping problem A.
One hour into the contest, over 100 contestants had correctly solved problem A or B, with very few solutions for C, and no attempts on D. At that point, it looked as if solving both A and B might be enough to guarantee a ticket to round 3. In another half an hour, there were just over 20 correct solutions for problem C, but still no correct attempts for problem D, not even for D-small.
The top 3 spots remained unchanged for over an hour -- hos.lyric, Gennady.Korotkevich, and fanhqme -- each with problems A, B and C. This remained the case until the very last minute, when bmerry came in with an impressive solution for both parts of problem D, earning him the top spot on the scoreboard. He submitted his D-large solution with only 6 seconds left on the clock!
Cast
Problem A. Ticket Swapping written by Onufry Wojtaszczyk. Prepared by Tomek Czajka.
Problem B. Many Prizes written by Bartholomew Furrow. Prepared by Tomek Czajka.
Problem C. Erdős–Szekeres written and prepared by David Arthur.
Problem D. Multiplayer Pong written and prepared by Onufry Wojtaszczyk.
Contest analysis presented by Onufry Wojtaszczyk. Solutions and other problem preparation by Ahmed Aly, Igor Naverniouk, Tomek Kulczynski, John Dethridge, Tiancheng Lou, Steve Thomas, Jan Kuipers, and Tomek Czajka.
A. Ticket Swapping
Problem
The city has built its first subway line, with a grand total of N stations, and introduced a new way of paying for travel. Instead of just paying for one ticket and making an arbitrary journey, the price you pay is now based on entry cards.
When entering the subway, each passenger collects an entry card, which specifies the station the passenger entered at. When leaving the subway, the passenger has to give up the entry card, and is charged depending on the distance (in stations traveled) between the entry station specified on the entry card, and the exit station on which the entry card is surrendered. The payment depends on the distance between these stations as follows:
- if they are the same station, you don't pay;
- if they are adjacent stations, you pay N pounds;
- if the distance is two stations, you pay 2N - 1: a charge N for the first stop and N - 1 for the second;
- the third station costs N-2 (so you pay 3N - 3 for a three-station-long trip), the fourth stop N-3, and the ith stop N + 1-i;
- thus, if you travel from one end of the subway to the other (a distance of N-1 stations), you pay 2 pounds for the last station traveled, and a grand total of (N2 + N - 2) / 2 in total.
After introducing this system the city noticed their gains are not as big as they expected. They figured out this might be due to people swapping their entry cards — so, for instance, if one person enters at station A, travels two stations to B and exits, while another person enters at B, travels three stations to C and exits, they would normally pay (in total) 2N - 1 + 3N - 3 = 5N - 4. But if the two people swapped their entry cards at station B, then the first one would travel for free (as he would surrender an entry card specifying the station B while exiting a station B, and so register a distance of zero); while the second person will exit at station C and surrender an entry card specifying station A, which is 5 stations away, and pays 5N - 10, at a net loss of six pounds to the city!
The city now wants to learn how much they can possibly lose if this practice becomes widespread. We will consider only one direction (from station 1 to station N, passing through all the stations in order) of the subway, and only one train on this line. We assume a passenger travelling from o to e obtains an entry card at o, can swap her entry card any number of times with any other passengers anywhere between o and e, including swapping with people who leave at o or those who enter at e, and then exit the train at e with some entry card (it is necessary to surrender some entry card to exit the subway). We also assume the passenger will not exit the train in the meantime (that is, will not surrender the currently held card and obtain a new one).
You are given a map of traffic (specifying how many passengers travel this train from which station to which), and you should calculate the city's financial loss, assuming passengers swap their cards to maximize this loss.
Input
The first line of the input gives the number of test cases, T. T test cases follow. Each test case contains the number N of stops (the stops are numbered 1 to N), and the number M of origin-endpoint pairs given. The next M lines contain three numbers each: the origin stop oi, the end stop ei and pi: the number of passengers that make this journey.
Output
For each test case, output one line containing "Case #x: y", where x is the case number (starting from 1) and y is the total loss the city can observe due to ticket swapping, modulo 1000002013.
Limits
Time limit: 30 seconds per test set.
Memory limit: 1GB.
1 ≤ T ≤ 20.
1 ≤ oi < ei ≤ N
Small dataset (Test set 1 - Visible)
2 ≤ N ≤ 100.
1 ≤ M ≤ 100.
1 ≤ pi ≤ 100.
Large dataset (Test set 2 - Hidden)
2 ≤ N ≤ 109.
1 ≤ M ≤ 1000.
1 ≤ pi ≤ 109.
Sample
3 6 2 1 3 1 3 6 1 6 2 1 3 2 4 6 1 10 2 1 7 2 6 9 1
Case #1: 6 Case #2: 0 Case #3: 10
The first test case is the case described in the problem statement - two passengers meet at station 3 and swap tickets. In the second test case the two passengers don't meet at all, so they can't swap tickets (and so the city incurs no loss). In the third case, only one of the early passengers can swap tickets with the later passenger.
B. Many Prizes
Problem
We're going to run a tournament with 2N teams, and give out P identical prizes to the teams with ranks 0..P-1.
The teams are numbered 0 through 2N-1. When team i and team j play against each other in a game, team i will win iff i<j.
The teams for a tournament are organized in some order, called the tournament's tournament list, which contains all 2N teams in the tournament. The tournament list will affect which teams play each other, and in what order.
Your job will be to find the largest-numbered team that is guaranteed to win a prize, independent of how the tournament list is ordered; and to find the largest-numbered team that could win a prize, depending on how the tournament list is ordered.
Tournament Resolution
The tournament is conducted in N rounds.
Each team has a record: the list of the results of the games it has played so far. For example, if a team has played three games, and won the first, lost the second and won the third, its record is [W, L, W]. If a team has played zero games, its record is [].
In each round, every team plays a game against a team with the same record. The first team in the tournament list with a particular record will play against the second team with that record; the third team with the same record will play against the fourth; and so on.
After N rounds, each team has a different record. The teams are ranked in reverse lexicographical order of their records; so [W, W, W] > [W, W, L] > [W, L, W] ... > [L, L, L].
Here is an example of a tournament with N=3, and the tournament list [2, 4, 5, 3, 6, 7, 1, 0], where the columns represent different rounds, and the teams are grouped by their records. The winner of each game in the example has been marked with a *.
Round 1 Round 2 Round 3 Final Result
(best rank at top)
[] [W] [W,W]
2 * 2 * 2 0 [W,W,W]
4 3 0 * 2 [W,W,L]
[W,L]
5 6 3 * 3 [W,L,W]
3 * 0 * 6 6 [W,L,L]
[L] [L,W]
6 * 4 * 4 1 [L,W,W]
7 5 1 * 4 [L,W,L]
[L,L]
1 7 5 * 5 [L,L,W]
0 * 1 * 7 7 [L,L,L]
If we give out 4 prizes (N=3, P=4), the prizes will go to teams 0, 2, 3 and 6.
The largest-numbered team that was guaranteed to win a prize with N=3, P=4, independent of the order of the tournament list, was team 0: this tournament list demonstrated that it's possible for team 1 not to win a prize, and it turns out that team 0 will always win one, regardless of the order of the tournament list.
The largest-numbered team that could win a prize with N=3, P=4, depending on how the tournament list was ordered, was team 6: this tournament list demonstrated that it's possible for team 6 to win a prize, and it turns out that team 7 will never win one, regardless of the order of the tournament list.
Input
The first line of the input gives the number of test cases, T. T test cases follow. Each test case consists of two space-separated integers: N, which indicates the tournament has 2N teams, and P, the number of prizes.
Output
For each test case, output one line containing "Case #x: y z", where x is the case number (starting from 1), y is the largest-numbered team that is guaranteed to win a prize, independent of how the tournament list is ordered; and z is the largest-numbered team that could win a prize, depending on how the tournament list is ordered.
Limits
Time limit: 30 seconds per test set.
Memory limit: 1GB.
1 ≤ T ≤ 100.
1 ≤ P ≤ 2N.
Small dataset (Test set 1 - Visible)
1 ≤ N ≤ 10.
Large dataset (Test set 2 - Hidden)
1 ≤ N ≤ 50.
Sample
3 3 4 3 5 3 3
Case #1: 0 6 Case #2: 2 6 Case #3: 0 4
C. Erdős–Szekeres
Problem
Given a list X, consisting of the numbers (1, 2, ..., N), an increasing subsequence is a subset of these numbers which appears in increasing order, and a decreasing subsequence is a subset of those numbers which appears in decreasing order. For example, (5, 7, 8) is an increasing subsequence of (4, 5, 3, 7, 6, 2, 8, 1).
Nearly 80 years ago, two mathematicians, Paul Erdős and George Szekeres proved a famous result: X is guaranteed to have either an increasing subsequence of length at least sqrt(N) or a decreasing subsequence of length of at least sqrt(N). For example, (4, 5, 3, 7, 6, 2, 8, 1) has a decreasing subsequence of length 4: (5, 3, 2, 1).
I am teaching a combinatorics class, and I want to "prove" this theorem to my class by example. For every number X[i] in the sequence, I will calculate two values:
- A[i]: The length of the longest increasing subsequence of X that includes X[i] as its largest number.
- B[i]: The length of the longest decreasing subsequence of X that includes X[i] as its largest number.
i | X[i] | A[i] | B[i] -----+--------+--------+-------- 0 | 4 | 1 | 4 1 | 5 | 2 | 4 2 | 3 | 1 | 3 3 | 7 | 3 | 4 4 | 6 | 3 | 3 5 | 2 | 1 | 2 6 | 8 | 4 | 2 7 | 1 | 1 | 1
I came up with a really interesting sequence to demonstrate this fact with, and I calculated A[i] and B[i] for every i, but then I forgot what my original sequence was. Given A[i] and B[i], can you help me reconstruct X?
X should consist of the numbers (1, 2, ..., N) in some order, and if there are multiple sequences possible, you should choose the one that is lexicographically smallest. This means that X[0] should be as small as possible, and if there are still multiple solutions, then X[1] should be as small as possible, and so on.
Input
The first line of the input gives the number of test cases, T. T test cases follow, each consisting of three lines.
The first line of each test case contains a single integer N. The second line contains N positive integers separated by spaces, representing A[0], A[1], ..., A[N-1]. The third line also contains N positive integers separated by spaces, representing B[0], B[1], ..., B[N-1].
Output
For each test case, output one line containing "Case #x: ", followed by X[0], X[1], ... X[N-1] in order, and separated by spaces.
Limits
Time limit: 30 seconds per test set.
Memory limit: 1GB.
1 ≤ T ≤ 30.
It is guaranteed that there is at least one possible solution for X.
Small dataset (Test set 1 - Visible)
1 ≤ N ≤ 20.
Large dataset (Test set 2 - Hidden)
1 ≤ N ≤ 2000.
Sample
2 1 1 1 8 1 2 1 3 3 1 4 1 4 4 3 4 3 2 2 1
Case #1: 1 Case #2: 4 5 3 7 6 2 8 1
D. Multiplayer Pong
Problem
Two teams of players play pong. Pong is a simple computer game, where each player controls a paddle (which we assume to be a point), and a little ball bounces back and forth. The players in one team are required to bounce the ball in a fixed cyclic order (so in a three-player team, the first one to touch the ball would be P1, then P2, then P3 and only then P1 again), until one of the players doesn't manage to bounce it, at which point the ball leaves the playing field and this player's team loses.
To be more precise: the playing field is a rectangle of size AxB. On each vertical wall (of length A) there are a number of paddles, one for each player of the team guarding this wall. Each paddle is a point. All the paddles of the players on one team move vertically at the same speed (in units per second), and can pass each other freely. There is also a ball, for which we are given its initial position (horizontal and vertical, counted from the lower-left corner) and initial speed (horizontal and vertical, again in units per second). The players are allowed to choose the initial positioning of their paddles on their vertical walls knowing the initial position of the ball. Whenever the ball reaches a horizontal wall, it bounces off (with the angle of incidence equal to the angle of reflection). Whenever it reaches a vertical end of the field, if the paddle of the player who is supposed to touch the ball now is there, it bounces off, while if there isn't, the team of the player whose paddle was supposed to be there loses.
The game can take quite a long time, with the players bouncing the ball back and forth. Your goal is to determine the final result (assuming all players play optimally).
Input
The first line of the input gives the number of test cases, T. T test cases follow. Each test case consists of four lines. The first line contains two integers, A and B, describing the height and width of the playing field. The second line contains two integers, N and M, describing the sizes of the two teams: N is the number of players on the team with paddles on the X = 0 wall, and M is the number of players on the team with paddles on X = B wall. The third line contains two integers, V and W, describing the speed of the paddles of players in the first and second team, respectively. The fourth line contains four integers: Y, X, VY and VX, describing the initial position (vertical and horizontal) and initial speed of the ball (the ball moves by VY units up and VX to the right each second, until it bounces).
Output
For each test case, output one line containing "Case #x: y", where x is the case number (starting from 1) and y is one of the three possible outputs: "DRAW" (if the game can proceed forever), "LEFT z", if the team with paddles on x = 0 wins, and the opposing team can bounce the ball at most z times, or "RIGHT z" if the team with paddles on X = B wins and the opposing team can bounce the ball at most z times.
Limits
Time limit: 30 seconds per test set.
Memory limit: 1GB.
1 ≤ T ≤ 100.
0 < X < B
0 < Y < A
Small dataset (Test set 1 - Visible)
1 ≤ N, M ≤ 106
1 ≤ V, W ≤ 1012
-1012 ≤ VY ≤ 1012
-106 ≤ VX ≤ 106
2 ≤ A, B ≤ 106
Large dataset (Test set 2 - Hidden)
1 ≤ N, M ≤ 10100
1 ≤ V, W ≤ 10100
-10100 ≤ VY, VX ≤ 10100
2 ≤ A, B ≤ 10100
Sample
4 6 4 1 2 3 1 5 1 4 8 12 3 3 1 2 3 1 1 2 4 12 3 1 3 3 1 1 1 2 4 12 2 1 2 10 2 3 1 13 4
Case #1: LEFT 2 Case #2: DRAW Case #3: LEFT 3 Case #4: RIGHT 11
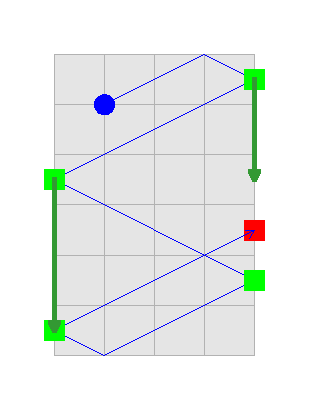
The picture depicts the gameplay in the first sample case. The ball bounces off the right wall at time 0.375 (the first RIGHT player intercepts it, for instance by beginning with her paddle there and not moving it), then off the left wall at 0.875 (the LEFT player bounces it), again on the right at time 1.375 (the second RIGHT player can position his paddle at the bounce point), again on the left (where the LEFT player gets just in time to catch it — she covers the three units of distance exactly in one second in which she needs to get there) and then hits the right wall too far for the first RIGHT player to get there. Note the second RIGHT player could catch the ball, but is not allowed by the rules to do so. Also note that if RIGHT team had one player more, she could bounce the ball, and then LEFT would lose — the ball would come too far up for the single LEFT player to get there in time.
Analysis — A. Ticket Swapping
The small dataset
Note that in this problem we treat the passengers as one "player" in a game, and assume they all cooperate to pay as little as possible in total to the city. This means it doesn't matter who actually pays for a given entry card. In particular, when the train leaves a station, the charge on each entry card in the train increases (by N - i, where i is the number of stations this card traveled so far). Since all passengers want to exit the subway eventually, all entry cards will have to be paid — so we might just as well immediately subtract this cash from the passenger "total" and move on.
As long as nobody exists the train, there's no need to exchange entry cards. Only once someone needs to exits, the passengers (along with the ones who just entered) need to gather and figure out which entry cards do the passengers who are just leaving take with them. They should choose the entry cards that have been on the train for the shortest amount of time so far, since on each subsequent stop the price for such an entry card will be larger than the price for any card that has been on the train longer (as the price is N - i, where i is the number of stations the card traveled so far). This means that at every station, the passengers should pool all the cards together, and then whoever wants to exit takes the entry cards with the smallest distance.
For the small dataset, a naive implementation of this algorithm will work. We can process station by station, holding a priority queue (or even just any collection) of the entry cards present. When anyone wants to exit, we iterate over the collection to find the card that has been on the train for the shortest amount, add its cost to the total passengers cost and remove it from the set. We also need to figure out how much the passengers should pay, but fortunately that's easy.
The large dataset
The large data set needs a bit more subtlety. With the insane amounts of passengers and stations we will need to avoid processing unnecessary events. First of all, we should process only the stations at which someone wants to enter or exit. This will make us process only O(M) stations, much less than the N we would process otherwise. Moreover, we should avoid processing passengers one by one.
To this end, notice that the order in which we want to give exit cards to passengers is actually a LIFO stack — whichever card came in last will go out first. So, we can keep the information about entry cards present in the train in a stack. Whenever a new group of passengers comes in, we take their entry cards and put them onto the stack (as one entry, storing the number of cards and the entry station). Whenever any group wants to leave, we go through the stack. If the topmost group of cards is big enough, we simply decrease its size, pay for what we took, and continue. If not, we take the whole group of cards, pay for it, decrease the amount of cards we need by the size of the group, and proceed through the stack.
This algorithm will take only O(M) time in total to process all the passengers — we will put on the stack at most M times, so we will take a whole group from the stack at most M times, and each group of passengers will decrease a group size (not take the whole group of cards) at most once, so in total — at most M such operations in the whole algorithm. Additionally, we need to sort all the events (a group of passengers entering or leaving) up front, so we are able to solve the whole problem in O(M logM).
Finally, when implementing, one needs to be careful. Due to the large amounts of stations and passengers involved, we have to use modular arithmetic carefully, because — as always with modular arithmetic — we risk overflow. In particular, whenever we multiply three numbers (which we do when calculating how much to pay for a group of tickets), we need to take care to apply the modulo after multiplying the first two.
Analysis — B. Many Prizes
Let's begin by an observation that will make our life a bit easier: if we reverse all the team numbers (that is, team 0 becomes team 2N-1, team 1 becomes team 2N-2, etc.), without changing the tournament list. This will result in the final ranks of the teams also being reversed, since it's relatively easy to see that all the records will be reversed (wins becoming losses and vice versa). This means that the problem of having a team rank as low as possible to get into the first P is equivalent to the problem of a team ranked as high as possible to get into the bottom P (or, in other words, not get into the top 2N - P). Thus, if we are able to answer the question what is the lowest rank that can possibly get into the top P, we can run the same code to see what's the lowest rank that can possibly be in the top 2N - P, subtract one, and reverse, and this will be the lowest rank that will always get a prize. This means we only have to solve one problem — lowest ranked team guaranteed to be in the top P
For the small dataset we have at most 1024 teams, which means we can try to figure out the tournament tree that will give a given team the best position, do this for all teams, and see which team was the lowest-ranked one to get a prize. Let's skip this, however, and jump straight to the solution for the large dataset, where 250 teams clearly disallow any direct approaches.
The key observation we can make here is that if we have a team we want to be as high as possible, we can do it with a record that includes a string of wins followed by a string of losses, and nothing else. This sounds surprising, but is actually true. Imagine, to the contrary, that the team (let's call them A) has a loss (against some team B) followed by a win against C, who played D in the previous round. Note that up to the round where A plays B the records of the four teams were identical. Also note that all the tournament trees of the four teams so far are disjoint, and so we can swap them around. In particular, we can swap team C and all its tree with team B and all its tree. Since we swap whole trees, the records of teams don't change, so now team A will play C in the first match and win — and so its record is going to be strictly better than it was, no matter what happens next. Thus, any ordering in which team A has a loss followed by a win is suboptimal.
This allows us to solve the problem of getting the highest possible rank for a given team. We simply need to greedily win as much as we can. If we're the worst team, we can't win anything. If we're not, we can certainly win the first match. The second match will be played against the winner of some match, so in order to win it we need to be better than three teams. To win two matches, we need to be better than seven teams, and so on.
We can also reverse the reasoning to get the lowest-ranked team that can win the prize. First, let's ask how many matches does one need to win in order to win a prize. If you win no matches, you are in the top 2N (not a huge achievement!). If you win one, you are in the top 2N - 1. And so on. Once we know how many matches you need to win, you directly know how many teams you need to be better than. Simple python code follows:
def LowRankCanWin(N, P):
if P == 0:
return -1
matches_won = 0
size_of_group = 2 ** N
while size_of_group > P:
matches_won += 1
size_of_group /= 2
return 2 ** N - 2 ** matches_won
def ManyPrizes(N, P):
print 2 ** N - LowRankCanWin(N, 2 ** N - P) - 2, LowRankCanWin(N, P)
Analysis — C. Erdős–Szekeres
Get the information
The real trick to this problem is squeezing as much information as possible from the sequences A[i] and B[i]. We will get information out in the form of inequalities between various elements of the sequence X.
First notice that if we have two indices i < j, and A[i] ≥ A[j], then X[i] > X[j]. Indeed, if it were otherwise, then the increasing sequence of length A[i] with X[i] as its largest element could be extended by adding X[j] at the end to obtain an increasing sequence with X[j] at the end, and we would have A[j] ≥ A[i] + 1. This allows us to add some inequalities X has to satisfy. We can add symmetric ones for B — if i < j and B[i] ≤ B[j], then X[i] < X[j].
These inequalities are not enough, however, to reconstruct X. Indeed, if we take A[i] = i + 1 and B[i] = N - i, we get no inequalities to consider, but at the same time not all permutations X are going to work. The problem is that while we know what we need to do with X so that no longer subsequences exist, we still need to guarantee that long enough sequences exist.
This is relatively simple to accomplish, though. If A[i] > 1, then the increasing subsequence ending at X[i] is formed by the extension of some sequence of length A[i] - 1. This means that X[i] has to be larger than X[j] for some j < i with A[j] = A[i] - 1. The previous set of inequalities guarantees that of the set of all such j (that is, j which are smaller than i and have A[j] = A[i] - 1) the one with the smallest X[j] is the largest j. Thus, it is enough to find the largest j with j < i and A[j] = A[i]-1 and add X[j] < X[i] to our set of inequalities. We again do the symmetric thing for B.
Use the information
Notice that the inequalities we have are indeed enough to guarantee that any sequence X satisfying them will lead to the A and B we want. It's relatively easy to check the first set of inequalities guarantees the numbers A and B will not be larger than we want, while the second set of inequalities guarantee they will be large enough.
We now reduced the problem to finding the lexicographically smaller permutation satisfying a given set of inequalities. To find the lexicographically smallest result we are foremost interested in minimizing the first value in X. To this end, we will simply traverse all the inequalities that the first value in X has to satisfy (that is, iterate over all the elements we know to be smaller, then all elements we know to be smaller than these elements, etc.). We can do this, e.g., through a DFS. After learning how many elements of X have to be smaller than X[1], we can assign the smallest possible value (this number + 1) to X[1]. Now we need to assign numbers smaller than X[1] to all these elements, in the lexicographically smallest way.
Note that how we do this assignment will not affect the other elements (since they are all going to be larger than X[1], and so also larger than everything we assign right now). Thus, we can assign this set of elements so that it is lexicographically smallest. This means taking the earliest of these elements, and repeating the same procedure recursively (find all elements smaller than it, assign the appropriate value, recurse). Note that once some values have been assigned, we need to take that into account when assigning new values (so, if we already assigned 1, 3 and 10; and now we know that an element we're looking at is larger than 4 others, the smallest value we can assign to it is 7).
Such a recursive procedure will allow us to solve the problem. For each element, we are going to traverse the graph of inequalities to find all the elements smaller than it is (O(M time if we do a DFS, where M is the number of inequalities we have), then see what's the smallest value we can assign (O(N) with a linear search, we can also go down to O(logN), but don't need to), and recurse. This gives us, pessimistically, O(N3) time — easily good enough for the small testcase, but risky for the large.
Compress the information
Following the exact procedure above we can end up with O(N2) inequalities. This will be too much for us (at least for the large dataset), so we will compress a bit.
The problem is with inequalities of the first type — for indices smaller than a given i there can be many with A larger or equal to A[i]. A trick we can use, though, is to take only one inequality — find the largest j < i with A[j] = A[i], and insert only the inequality X[j] > X[i].
Any other k < j with A[k] = A[i] will follow from transitivity — there will be a sequence of indices with A equal to A[i] connecting k to i. Any k with A[k] > A[i] will also follow, since X[k] will have to be greater than some X[l] for A[l] = A[i] and l < k (and thus < i). This means we can reduce our set of inequalities down to a set of O(N), which means that each DFS traversal step will take only O(N) time, and the solution to the whole problem will run in O(N2).
Interesting fact: It is also possible to solve this problem in O(N logN). Can you figure it out?
Analysis — D. Multiplayer Pong
Preliminaries
We hope you took our Fair Warning, which we fairly repeated in Fair and Square this year — we consider Big Integers to be fair game, so if your language doesn't natively support them, you'd better have a library to handle them ready.
This problem seems to be about fractions initially, since the ball can hit the walls at fractional positions. There's a way to move it to integers (man, Big Fractions would be too much). The way to go about it is to scale things. Let's scale the time, so now there are VX units to a second, and scale vertical distances, so that there are VX units to the old unit. This means the vertical speeds stay the same, horizontal speeds get VX times smaller, horizontal distances stay the same, and vertical distances grow VX times larger. In implementation terms, this means we shrink VX to 1 and grow A times VX — and now suddenly the ball moves a integral number of units upwards and one unit to the side in each unit of time (and so will hit the vertical walls in integral moments of time).
The above assumes VX is positive. If it's zero, then the ball will never hit the walls, and so the game ends in a draw. If it's negative, we can flip the whole board across the Y axis and swap the teams to make VX change signs. Similarly, we can assume VY positive — if it's zero, putting all paddles in the single impact point will guarantee a draw, and if it's negative, we can flip the board vertically.
So now the ball will hit a given vertical wall every 2B units of time. It's also relatively easy to figure out what is the position of the impact. If there were no vertical walls, the ball would hit at the initial hit position (Y + (B - X) VY), and then at 2BVY intervals from there. To calculate the positions in real life, notice that every 2A upwards the ball is in the same position again (so we can take impact points module 2A), and if that number is larger than A, the ball goes in the other direction, and the impact position is 2A minus whatever we calculated.
Many bounces
So now we know how to calculate hit positions, so we can just simulate and see who loses first, right? Well, wrong, because the ball can bounce very many times. Even in the small dataset, the number of bounces can go up to 1011, too much for simulation.
Notice that the positions of the paddles are pretty much predetermined. The paddle of a given player has to be exactly at the point of impact when it is the player's turn to bounce it, and then the only question is whether the player will have enough time to reach the next point of impact before the ball. With N paddles on a team, and V being the speed of the paddle, the player can move the paddle by 2BVN before the next impact. The ball, in the same time, will move by 2BVYN, but while the paddle moves in absolute numbers, the ball moves "modulo 2A with wrapping", as described above.
If the distance the ball moves (modulo A) is smaller or equal to the distance the paddle moves, the paddle will always be there in time. The interesting case is when it is not so. In this case, there is still a chance for the paddle to be in the right place on time due to the "wrapping effect". For instance, if the ball moves by A+1 with each bounce, and the first bounce happens at A / 2, the next one will happen at A / 2 - 1, the next one at A / 2 + 2, and so on — so the initial bounces will be pretty close by. We can calculate exactly the set of positions where the ball hitting the wall will allow the paddle to catch up, and it turns out that it is two intervals modulo 2A.
So now the question becomes "how long can the ball bounce without hitting a prohibited set of two intervals", which is easy to reduce to "without hitting the given interval". This is a pure number-theoretic question: we have an arithmetic sequence I + KS, modulo 2A, and we are interested in the first element of this sequence to fall into a given interval.
Euclid strikes again
There is a number of approaches one can take to solving this problem. We will take an approach similar to the Euclidean algorithm. First, we can shift everything modulo 2A so that I is zero, and we are dealing with the sequence KS. Also, we can shift the problem so that S ≤ A — if not, we can (once again) flip the problem vertically. Thus, the ball will bounce at least twice before wrapping around the edge of 2A.
We can calculate when is the first time the ball will pass the beginning of the forbidden interval (by integral division). If at this point the ball hits the forbidden interval, we are done. Otherwise, the ball will travel all the way to 2A, and then wrap around and hit the wall again at some position P smaller than S. Notice that in this case the interval obviously is shorter than S.
Now, the crucial question is what P is. It's relatively easy to calculate for what values of P will the next iteration land in the interval (if the interval is [kS + a, kS + b] for some k, a, b, then the interesting set of values of P is [a, b]). If P happens to be in this interval, we can again calculate the answer fast. If not, however, we will do another cycle, and then hit the wall (after cycling) at the point 2P, mod S. Notice that this is very similar to the original problem! We operate modulo S, we increment by P with each iteration, and we are interested in when we enter the interval [a,b].
Thus, we can apply recursion to learn after how many cycles will we finally be in a position to fall into the original interval we were interested in. So we make that many full cycles, and then we finish with a part of the last cycle to finally hit the interval.
Complexity analysis
All the numbers we will be operating on will have at most D = 200 digits in the large dataset, so operations on them will take at most O(D2 logD) time (assuming a quadratic multiplication implementation and a binary-search implementation of division). Each recursion step involves a constant number of arithmetic operations plus a recursive call, for which the number A (the modulo) decreases at least twice. This means we make at most O(D) recursion steps — so the whole algorithm will run in O(D3 logD) time, fast enough allowing even some room for inefficiency.