Google Code Jam Archive — Round 1B 2011 problems
Overview
Round 1B was clearly easier than 1A. Only 10 minutes after the start, submissions for A-small started pouring in. Gennady.Korotkevich took an early lead with a lightning fast submission of A-large. Fifteen minutes later, he followed it up with a correct solution to problem B, taking the first place back from rng..58, who had briefly held it by solving problem B first.
After a long silence, three nearly simultaneous submissions for C-small arrived from RAVEman, Gennady.Korotkevich and vepifanov at the 50-minute mark, putting the three contestants into a dead heat for a shot at the first place. Five minutes later, emaxx joined the race with a correct C-small. We spent the next ten minutes in anticipation.
At the one hour mark almost exactly, three new contestants took a leap to the top with correct submissions on C-large -- rng..58, pieguy and bsod.
When the round ended, almost half of the submissions to B-large turned out to be incorrect, possibly because of overflow errors. rng..58 retained his top spot with six flawless submissions, followed by Zhukov Dmitry and winger. In order to advance to round 2, it was not enough to have solved only problem A.
Good luck to the top 1000 in round 2. Everyone else will have one more chance to advance in round 1C.
Cast
Problem A. RPI Written and prepared by David Arthur.
Problem B. Revenge of the Hot Dogs Written by David Arthur and prepared by Onufry Wojtaszczyk.
Problem C. House of Kittens Written and prepared by David Arthur.
Contest analysis presented by Jonathan Calhoun and David Arthur.
Solutions and other problem preparation by Jorge Bernadas Saragoza, Igor Naverniouk, Petr Mitrichev, Tomek Czajka, Sean Henderson, John Dethridge, Steve Thomas and Marcin Michalski.
A. RPI
Problem
In the United States, 350 schools compete every year for an invitation to the NCAA College Basketball Tournament. With so many schools, how do you decide who should be invited? Most teams never play each other, and some teams have a much more difficult schedule than others.
Here is an example schedule for 4 teams named A, B, C, D:
|ABCD -+---- A|.11. B|0.00 C|01.1 D|.10.
Each 1 in a team's row represents a win, and each 0 represents a loss. So team C has wins against B and D, and a loss against A. Team A has wins against B and C, but has not played D.
The NCAA tournament committee uses a formula called the RPI (Ratings Percentage Index) to help rank teams. Traditionally, it has been defined as follows:
RPI = 0.25 * WP + 0.50 * OWP + 0.25 * OOWPWP, OWP, and OOWP are defined for each team as follows:
- WP (Winning Percentage) is the fraction of your games that you have won.
In the example schedule, team A has WP = 1, team B has WP = 0, team C has WP = 2/3, and team D has WP = 0.5. - OWP (Opponents' Winning Percentage) is the average WP of all your opponents, after first throwing out the games they played against you.
For example, if you throw out games played against team D, then team B has WP = 0 and team C has WP = 0.5. Therefore team D has OWP = 0.5 * (0 + 0.5) = 0.25. Similarly, team A has OWP = 0.5, team B has OWP = 0.5, and team C has OWP = 2/3. - OOWP (Opponents' Opponents' Winning Percentage) is the average OWP of all your opponents. OWP is exactly the number computed in the previous step.
For example, team A has OOWP = 0.5 * (0.5 + 2/3) = 7/12.
Putting it all together, we see team A has RPI = (0.25 * 1) + (0.5 * 0.5) + (0.25 * 7 / 12) = 0.6458333...
There are some pretty interesting questions you can ask about the RPI. Is it a reasonable measure of team's ability? Is it more important for teams to win games, or to schedule strong opponents? These are all good questions, but for this problem, your task is more straightforward: given a schedule of games, can you calculate every team's RPI?
Input
The first line of the input gives the number of test cases, T. T test cases follow. Each test case begins with a single line containing the number of teams N.
The next N lines each contain exactly N characters (either '0', '1', or '.') representing a schedule in the same format as the example schedule above. A '1' in row i, column j indicates team i beat team j, a '0' in row i, column j indicates team i lost to team j, and a '.' in row i, column j indicates team i never played against team j.
Output
For each test case, output N + 1 lines. The first line should be "Case #x:" where x is the case number (starting from 1). The next N lines should contain the RPI of each team, one per line, in the same order as the schedule.
Answers with a relative or absolute error of at most 10-6 will be considered correct.
Limits
1 ≤ T ≤ 20.
If the schedule contains a '1' in row i, column j, then it contains a '0' in row j, column i.
If the schedule contains a '0' in row i, column j, then it contains a '1' in row j, column i.
If the schedule contains a '.' in row i, column j, then it contains a '.' in row j, column i.
Every team plays at least two other teams.
No two teams play each other twice.
No team plays itself.
Memory limit: 1GB.
Small dataset (Test set 1 - Visible)
3 ≤ N ≤ 10.
Time limit: 30 seconds.
Large dataset (Test set 2 - Hidden)
3 ≤ N ≤ 100.
Time limit: 60 seconds.
Sample
2 3 .10 0.1 10. 4 .11. 0.00 01.1 .10.
Case #1: 0.5 0.5 0.5 Case #2: 0.645833333333 0.368055555556 0.604166666667 0.395833333333
B. Revenge of the Hot Dogs
Problem
Last year, several hot dog vendors were lined up along a street, and they had a tricky algorithm to spread themselves out. Unfortunately, the algorithm was very slow and they are still going. All is not lost though! The hot dog vendors have a plan: time to try a new algorithm!
The problem is that multiple vendors might be selling too close to each other, and then they will take each other's business. The vendors can move along the street at 1 meter/second. To avoid interfering with each other, they want to stand so that every pair of them is separated by a distance of at least D meters.
Remember that the street is really long, so there is no danger of running out of space to move in either direction. Given the starting positions of all hot dog vendors, you should find the minimum time they need before all the vendors are separated (each two vendors are at least D meters apart from each other).
Input
Each point of the street is labeled with a number, positive, negative or zero. A point labeled p is |p| meters east of the point labeled 0 if p is positive, and |p| meters west of the point labeled 0 if p is negative. We will use this labeling system to describe the positions of the vendors in the input file.
The first line of the input file contains the number of cases, T. T test cases follow. Each case begins with a line containing the number of points C that have at least one hot dog vendor in the starting configuration and an integer D -- the minimum distance they want to spread out to. The next C lines each contain a pair of space-separated integers P, V, indicating that there are V vendors at the point labeled P.
Output
For each test case, output one line containing "Case #x: y", where x is the case number (starting from 1) and y is the minimum amount of time it will take for the vendors to spread out apart on the street. Answers with relative or absolute error of at most 10-6 will be accepted.
Limits
1 ≤ T ≤ 50.
All the values P are integers in the range [-105, 105].
Within each test case all P values are distinct and given in an increasing order. The limit on the sum of V values is listed below. All the V values are positive integers.
Memory limit: 1GB.
Small dataset (Test set 1 - Visible)
1 ≤ D ≤ 5
1 ≤ C ≤ 20.
The sum of all the V values in one test case does not exceed 100.
Time limit: 30 seconds.
Large dataset (Test set 2 - Hidden)
1 ≤ D ≤ 106
1 ≤ C ≤ 200.
The sum of all V values does not exceed 106
Time limit: 60 seconds.
Sample
2 3 2 0 1 3 2 6 1 2 2 0 3 1 1
Case #1: 1.0 Case #2: 2.5
C. House of Kittens
Problem
You have recently adopted some kittens, and now you want to make a house for them. On the outside, the house will be shaped like a convex polygon with N vertices. On the inside, it will be divided into several rooms by M interior walls connecting vertices along straight lines. No two walls will ever cross, but there might be multiple walls touching a single vertex.
So why is your house of kittens going to be so special? At every vertex, you are going to build a pillar entirely out of catnip! Kittens will be able to play with any pillar that touches the room they are in, giving them a true luxury home.
To make the house even more exciting, you want to use different flavors of catnip. A single pillar can only use one flavor, but different pillars can use different flavors. There is only one problem. If some room does not have access to all the catnip flavors in the house, then the kittens in that room will feel left out and be sad.
Your task is to choose what flavor of catnip to use for each vertex in such a way that (a) every flavor is accessible from every room, and (b) as many flavors as possible are used.
In the following example, three different flavors (represented by red, green, and blue dots) are distributed across an 8-sided house while keeping the kittens in every room happy:
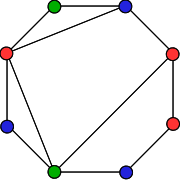
In the image above, starting at the left corner of the top wall and going clockwise, the colors here are: green, blue, red, red, blue, green, blue, red.
Input
The first line of the input gives the number of test cases, T. T test cases follow.
Each test case consists of three lines. The first line gives N and M, the number of vertices and interior walls in your cat house. The second lines gives space-separated integers U1, U2, ..., UM describing where each interior wall begins. The third lines gives space-separated integers V1, V2, ..., VM describing where each interior wall ends.
More precisely, if the vertices of your cat house are labeled 1, 2, ..., N in clockwise order, then the interior walls are between vertices U1 and V1, U2 and V2, etc.
Output
For each test case, output two lines. The first should be "Case #x: C", where x is the case number, and C is the maximum number of catnip flavors that can be used. The second line should contain N space-separated integers: "y1 y2 ... yN", where yi is an integer between 1 and C indicating which catnip flavor you assigned to vertex i.
If there are multiple assignments with C flavors, you may output any of them.
Limits
1 ≤ T ≤ 100.
1 ≤ M ≤ N - 3.
1 ≤ Ui < Vi ≤ N for all i.
Interior walls do not touch each other except at the N vertices.
Interior walls do not touch the outside of the house except at the N vertices.
Memory limit: 1GB.
Small dataset (Test set 1 - Visible)
4 ≤ N ≤ 8.
Time limit: 30 seconds.
Large dataset (Test set 2 - Hidden)
4 ≤ N ≤ 2000.
Time limit: 60 seconds.
Sample
2 4 1 2 4 8 3 1 1 4 3 7 7
Case #1: 3 1 2 1 3 Case #2: 3 1 2 3 1 1 3 2 3
Analysis — A. RPI
The problem statement explains exactly what to do here. You just need to follow the instructions and not get too confused! We wanted to give you something to warm up with before the next two problems, which are both quite tricky.
First the winning percentage (WP) of each team needs to be calculated. This is fairly straightforward since the WP of team i only depends on team i's record. To do this part, we need to know the total number of wins for each team, as well as the total number of games played. We can then calculate WP[i] = Wins[i] / Total[i].
Next the OWP of each team needs to be calculated, but the OWP requires a modified WP for each opponent. Let's consider WP'[i][j], the winning percentage of team i if you exclude games against team j. To calculate WP'[i][j], we have to examine three possible cases.
- If team i never played versus team j, then WP' has no relevance and can be ignored.
- If team i did play versus team j and won the game, then WP'[i][j] = (Wins[i]-1) / (Total[i]-1).
- If team i did play versus team j and lost the game, then WP'[i][j] = (Wins[i]) / (Total[i]-1).
All that is left to do to calculate WP' is to try all pairs of teams and calculate the value if the two teams played.
Now that we have WP' for every pair of teams, we can calculate the OWP values. Let S[i] be the set of teams that team i played against. Then we can calculate OWP[i] as follows:
OWPSum[i] = 0
for team j in S[i]:
OWPSum[i] += WP'[j][i]
OWP[i] = OWPSum[i] / size(S[i]).
Lastly, we need to calculate the OOWP for every team i. The OOWP uses the OWP which we already calculated:
OOWPSum[i] = 0
for team j in S[i]:
OOWPSum[i] += OWP[j]
OOWP[i] = OOWPSum[i] / size(S[i]).
Finally, we can combine everything with the formula:
RPI[i] = WP[i] * 0.25 + OWP[i] * 0.5 + OOWP[i] * 0.25.
By the way, this formula really is in use. It is not always very good at ranking teams though!
Analysis — B. Revenge of the Hot Dogs
This problem might look petty tough at first glance. There are lots of hot dog vendors, and each one has a very important choice to make. How can you account for all the possibilities at once?
It turns out there are at least two completely different solutions, one of which uses a classical algorithmic technique, and one of which is purely mathematical. We will present both approaches here.
An Algorithmic Solution
There are two key ideas that motivate the algorithmic solution.
- There is no reason to ever have one hot dog vendor walk past another. Instead of doing that, they could walk up to each other and then just go back the way they came. Since everyone moves at the same speed, this is completely equivalent to having the two people cross.
- Rather than trying to directly calculate the minimum time required, it suffices to ask the following slightly easier question: Given a time t and a distance D, is it possible to move all the hot dog vendors distance D apart in some fixed time t? If we can answer that question efficiently, we can use a binary search to find the minimum t:
lower_bound = 0 upper_bound = 1012 while upper_bound - lower_bound > 10-8 * upper_bound: t = (lower_bound + upper_bound) / 2 if t is high_enough: upper_bound = t else: lower_bound = t return lower_bound
So we need to decide if t seconds is enough to move all the hot dogs vendors apart. Let's think about the road as going from left (negative values) to right (positive values), and focus on the leftmost person A. By our first observation, he is still going to be leftmost when everyone is done moving. So we might as well just move him as far left as possible. That way, he will interfere as little as possible with the remaining people. Since we have fixed t, this tells us exactly where A will end up.
Now let's consider the second leftmost person B. He has to end up right of A by at least distance D. Subject to that limit, he should once again go as far left as possible. (Of course once you account for the first guy, "as far left as possible" might actually be to the right!) The reason for doing this is the same as before: the further left this person goes, the easier it will be to place all the remaining people. In fact, this same strategy works for everyone. Once the time is fixed, each person should always go as far left as possible without getting less than distance D from the previous person.
Using this greedy strategy, we can position every single person one by one. If we come up with a valid set of positions in this way, then we know t is enough time. If we do not, then there is nothing better we could have possibly done.
We can now just plug this into the binary search, and the problem is solved!
A Mathematical Solution
On the Google Code Jam, we would expect our contestants to try algorithmic approaches first. After all, you guys are algorithm experts! However, we would like to also present a mathematical solution to this problem. It avoids the binary search, and so it is more efficient than the previous solution if you implement it right.
As above, sort the people from left to right. Let Pi be the position of the ith person, and let xi,j = D*(j - i) - (Pj - Pi). Finally, define X = maxi < j xi,j. We claim max(0, X) / 2 is exactly the amount of time required.
Let's first show that you need at least this much time. Focus on two arbitrary people: i and j. Since nobody should ever cross (as argued above), there must still be j - i - 1 people between these two when everything is done. Therefore, they must end up separated by a distance of at least D*(j - i). They start off separated by only Pj - Pi, and this distance can go up by at most 2 every second, so we do in fact need at least [D*(j - i) - (Pj - Pi)] / 2 seconds altogether.
To prove this much time suffices, we show how X can always be decreased at a rate of 2 meters per second. Let's focus on some single person j. We will say he is "left-limited" if there exists i < j such that xi,j = X, and he is "right-limited" if there exists k > j such that xj,k = X. Suppose we can move every left-limited person to the left at maximum speed, and every right-limited person to the right at maximum speed. Then any term xi,j which is equal to X will be decreasing by the full 2 meters per second, and hence X will also be decreasing by 2 meters per second, as required.
So this strategy works as long as no single person is both left-limited and right-limited. (If that happened, he would not be able to go both left and right at the same time, and the strategy would be impossible.) So let's suppose xi,j = X = xj,k. If you just write down the equation, you'll see xi,k is exactly equal to xi,j + xj,k. But this means xi,k = 2X > X, and we have a contradiction. Therefore, no single person is ever both left-limited and right-limited, and the proof is complete!
Additional Comments
- It turns out the answer for this problem is always an integer or an integer plus 0.5. Do you see why? In particular, if you multiply all positions by 2 at the beginning, you can work only with integers. This allows you to avoid worrying about floating point rounding issues, which is always nice!
- At first, the mathematical solution looks like it is O(n2), since you are calculating the maximum of O(n2) different numbers. Do you see how to do it linear time?
Analysis — C. House of Kittens
There are three different tasks you need to work through in order to solve this problem:
- How do you transform the input into a more convenient format?
- How do you efficiently calculate C?
- How do you efficiently find a catnip assignment with exactly C flavors?
An implementation would certainly start with the first task, but when you're just thinking about the problem, it's better to focus on the high-level algorithm first. How could you know what data format is convenient until you know what you want to do with it?
Finding an Optimal Assignment
So let's start with C. The most important observation is also one of the simplest. Let m be the minimum number of vertices in a single room. Kittens in that room have access to at most m flavors of catnip, so it must be that C ≤ m.
In fact, it turns out that C is always equal to m. Proving this is pretty much equivalent to the third sub-task: we need to give a method for assigning flavors that always work with C = m. Here it is:
- Choose an arbitrary room. Assign flavors to its vertices in such a way that all C flavors are used, and no two adjacent vertices use the same flavor.
- Choose a room adjacent to the starting one. This will have two different flavors fixed for two adjacent vertices. Fill in the remaining vertices as before: all C flavors are used, and no two adjacent vertices use the same flavor.
- Choose another room adjacent to one of the rooms previously considered. Again, it will have two different flavors fixed for two adjacent vertices, and nothing else. Proceed as before.
- Continue in exactly the same way until all rooms are complete.
There are two keys that make this work.
Key 1: It really is possible to assign valid flavors to the vertices of a single room, even after fixing distinct flavors for two adjacent vertices. Start with those two adjacent vertices, assign the remaining flavors to the next C - 2 vertices, and then just avoid equal neighbors for the remaining vertices. This is always possible since C ≥ 3.
Key 2: When we get to a new room, only two adjacent vertices will ever be fixed. To see why, let's say you just got to a room R by crossing some wall W. Then, W divides the house into two disjoint parts, so this will be the first time you are touching any room on the same side of W as R. In particular, this means the only vertices that will be fixed are the ones that belong to W.
That's it. Just be glad we are asking for an arbitrary assignment of flavors, instead of the lexicographically first one, or something equally evil!
Handling the Input
The main technical challenge in implementing this algorithm is figuring out where all the rooms are in the first place, and how they are connected.
One approach is to maintain a list of lists, representing the vertices in each room. We start off with just a single room: [[1, 2, ..., N]]. For each wall inside the house, we scan through the rooms until we find the one that has both endpoints of the wall, and then split that room into two. We then have to be a little careful about what order we process the rooms in. One option would be to start with an arbitrary room, and then only process future rooms once they have two vertices set. This runs in O(N2) time.
There are also some fancier (almost) linear-time solutions. For each vertex, record the edges coming out of the vertex, sorted by the opposite endpoint. Now you can start with one face, trace along all of its edges, and then recursively proceed to the faces across each edge.
Either method works, so you can use whichever you prefer.