Google Code Jam Archive — Round 1A 2010 problems
Overview
The problems in Round 1A were a collection of simulation, dynamic programming and game theory. After we had selected problem B as the medium, David Arthur came up with a clever solution that was 256 times faster than the original solution, but we decided to keep the input limits as-is. You can see a description of both algorithms in the analysis write-up of problem B.
The winner, rng..58, finished all 3 problems in just under 41 minutes, followed by Pipi and cgy4ever. Last year's winner, ACRush, made mistakes on problems A and B, but still managed to finish in the top 10.
Cast
Problem A. Rotate Written and prepared by David Arthur.
Problem B. Make it Smooth Written by Xiaomin Chen. Prepared by Xiaomin Chen and Bartholomew Furrow.
Problem C. Number Game Written by David Arthur. Prepared by Petr Mitrichev and David Arthur.
Contest analysis presented by David Arthur, Xiaomin Chen, and Igor Naverniouk.
Solutions and other problem preparation provided by Ante Derek, John Dethridge, Igor Naverniouk, and Cosmin Negruseri.
A. Rotate
Problem
In the exciting game of Join-K, red and blue pieces are dropped into an N-by-N table. The table stands up vertically so that pieces drop down to the bottom-most empty slots in their column. For example, consider the following two configurations:
- Legal Position -
.......
.......
.......
....R..
...RB..
..BRB..
.RBBR..
|
- Illegal Position -
.......
.......
.......
.......
Bad -> ..BR...
...R...
.RBBR..
|
In these pictures, each '.' represents an empty slot, each 'R' represents a slot filled with a red piece, and each 'B' represents a slot filled with a blue piece. The left configuration is legal, but the right one is not. This is because one of the pieces in the third column (marked with the arrow) has not fallen down to the empty slot below it.
A player wins if they can place at least K pieces of their color in a row, either horizontally, vertically, or diagonally. The four possible orientations are shown below:
- Four in a row -
R RRRR R R
R R R
R R R
R R R
|
As it turns out, you are right now playing a very exciting game of Join-K, and you have a tricky plan to ensure victory! When your opponent is not looking, you are going to rotate the board 90 degrees clockwise onto its side. Gravity will then cause the pieces to fall down into a new position as shown below:
- Start -
.......
.......
.......
...R...
...RB..
..BRB..
.RBBR..
|
- Rotate -
.......
R......
BB.....
BRRR...
RBB....
.......
.......
|
- Gravity -
.......
.......
.......
R......
BB.....
BRR....
RBBR...
|
All that remains is picking the right time to make your move. Given a board position, you should determine which player (or players!) will have K pieces in a row after you rotate the board clockwise and gravity takes effect in the new direction.
Notes
- You can rotate the board only once.
- Assume that gravity only takes effect after the board has been rotated completely.
- Only check for winners after gravity has finished taking effect.
Input
The first line of the input gives the number of test cases, T. T test cases follow, each beginning with a line containing the integers N and K. The next N lines will each be exactly N characters long, showing the initial position of the board, using the same format as the diagrams above.
The initial position in each test case will be a legal position that can occur during a game of Join-K. In particular, neither player will have already formed K pieces in a row.
Output
For each test case, output one line containing "Case #x: y", where x is the case number (starting from 1), and y is one of "Red", "Blue", "Neither", or "Both". Here, y indicates which player or players will have K pieces in a row after you rotate the board.
Limits
Time limit: 30 seconds per test set.
Memory limit: 1GB.
1 ≤ T ≤ 100.
3 ≤ K ≤ N.
Small dataset (Test set 1 - Visible)
3 ≤ N ≤ 7.
Large dataset (Test set 2 - Hidden)
3 ≤ N ≤ 50.
Sample
4 7 3 ....... ....... ....... ...R... ...BB.. ..BRB.. .RRBR.. 6 4 ...... ...... .R...R .R..BB .R.RBR RB.BBB 4 4 R... BR.. BR.. BR.. 3 3 B.. RB. RB.
Case #1: Neither Case #2: Both Case #3: Red Case #4: Blue
B. Make it Smooth
Problem
You have a one-dimensional array of N pixels. Each pixel has a value, represented by a number between 0 and 255, inclusive. The distance between two pixels is the absolute difference of their numbers.
You can perform each of the following operations zero or more times:
- With cost D, delete any pixel, so its original neighbors become neighboring pixels.
- With cost I, insert one pixel of any value into any position -- either between two existing pixels, or before the first pixel, or after the last pixel.
- You can change the value of any pixel. The cost is the absolute difference of the old value of the pixel and the new value of the pixel.
The array is smooth if any neighboring pixels have distance at most M. Find the minimum possible cost of a sequence of operations that makes the array smooth.
Note: The empty array -- the array containing no pixels -- is considered to be smooth.
Input
The first line of the input gives the number of test cases, T. T test cases follow, each with two lines. The first line is in the form "D I M N", the next line contains N numbers ai: the values of the pixels from left to the right.
Output
For each test case, output one line containing "Case #x: y", where x is the case number (starting from 1), and y is the minimum cost to make the input array smooth.
Limits
Time limit: 30 seconds per test set.
Memory limit: 1GB.
All the numbers in the input are integers.
1 ≤ T ≤ 100
0 ≤ D, I, M, ai ≤ 255
Small dataset (Test set 1 - Visible)
1 ≤ N ≤ 3.
Large dataset (Test set 2 - Hidden)
1 ≤ N ≤ 100.
Sample
2 6 6 2 3 1 7 5 100 1 5 3 1 50 7
Case #1: 4 Case #2: 17
Explanation
In Case #1, decreasing the 7 to 3 costs 4 and is the cheapest solution. In Case #2, deleting is extremely expensive; it's cheaper to insert elements so your final array looks like [1, 6, 11, 16, 21, 26, 31, 36, 41, 46, 50, 45, 40, 35, 30, 25, 20, 15, 10, 7].
C. Number Game
Problem
Arya and Bran are playing a game. Initially, two positive integers A and B are written on a blackboard. The players take turns, starting with Arya. On his or her turn, a player can replace A with A - k*B for any positive integer k, or replace B with B - k*A for any positive integer k. The first person to make one of the numbers drop to zero or below loses.
For example, if the numbers are initially (12, 51), the game might progress as follows:
- Arya replaces 51 with 51 - 3*12 = 15, leaving (12, 15) on the blackboard.
- Bran replaces 15 with 15 - 1*12 = 3, leaving (12, 3) on the blackboard.
- Arya replaces 12 with 12 - 3*3 = 3, leaving (3, 3) on the blackboard.
- Bran replaces one 3 with 3 - 1*3 = 0, and loses.
Given four integers A1, A2, B1, B2, count how many winning positions (A, B) there are with A1 ≤ A ≤ A2 and B1 ≤ B ≤ B2.
Input
The first line of the input gives the number of test cases, T. T test cases follow, one per line. Each line contains the four integers A1, A2, B1, B2, separated by spaces.
Output
For each test case, output one line containing "Case #x: y", where x is the case number (starting from 1), and y is the number of winning positions (A, B) with A1 ≤ A ≤ A2 and B1 ≤ B ≤ B2.
Limits
Memory limit: 1GB.
1 ≤ T ≤ 100.
1 ≤ A1 ≤ A2 ≤ 1,000,000.
1 ≤ B1 ≤ B2 ≤ 1,000,000.
Small dataset (Test set 1 - Visible)
Time limit: 30 seconds.
A2 - A1 ≤ 30.
B2 - B1 ≤ 30.
Large dataset (Test set 2 - Hidden)
Time limit: 90 seconds.
A2 - A1 ≤ 999,999.
B2 - B1 ≤ 999,999.
No additional constraints.
Sample
3 5 5 8 8 11 11 2 2 1 6 1 6
Case #1: 0 Case #2: 1 Case #3: 20
Analysis — A. Rotate
This is a relatively straightforward simulation problem -- the problem statement tells you what to do, and you just need to do it.
Well, except for one fun point: The name of the problem is Rotate, and in the statement we talk about the rotation a lot. However, that is the one thing you do not need to implement! Rotating 90 degrees clockwise and pushing everything downwards has the same effect as pushing everything towards the right without rotating. As long as you push the pieces in the correct direction, it doesn't matter whether you actually do the rotation. Any K pieces in a row will be the same in these two pictures, and your output will be the same too.
So, a simple solution to this problem looks like this:
(1) In each row, push everything to the right. This can be done with some code like the following:
for (int row = 1; row < n; ++row) {
int x = n-1;
for (int col = n-1; col >= 0; col--)
if (piece[row][col] != '.') {
piece[row][x] = piece[row][col]; x--;
}
while(x>=0) {piece[row][x]='.'; x--;}
}
(2) Test if there are K pieces in a row of the same color. There are tricks that can be done to speed this up, but in our problem, N is at most 50, and no special optimizations are needed. For each piece, we can just start from that piece and look in all 8 directions (or we can do just 4 directions because of symmetry). For each direction, we go K steps from the starting piece, and see if all the pieces encountered are of the same color. The code -- how to go step by step in a direction, and how to check if we are off the board -- will look similar in many different programming languages. We encourage you to check out some of the correct solutions by downloading them from the scoreboard.
Analysis — B. Make it Smooth
The Basic Solution
Just about any solution to this problem is going to ultimately rely on building up a smoothed array by first solving smaller sub-problems. The challenge is two-fold: (1) What are the sub-problems you want to solve? And (2) How can you efficiently process them all?
It is natural to start off by making the first N-1 pixels smooth, and then figuring out afterwards what to do with the last pixel. The catch is what we do with the last pixel q depends on p, the final pixel we set before-hand. If p and q differ by at most M, then we are already done! Otherwise, we have two choices:
- Delete
qwith costD, leaving the final pixel of our smoothed picture asp. - Move
qto some valueq'with cost|q - q'|. If|q' - p| > M, we will then have to add some pixels before-hand to make the transition smooth. In fact, we will need to add exactly(|q' - p| - 1)/ Mof these pixels.
q'.
Perhaps the trickiest part of this setup is understanding insertions. After all, when deciding what steps to take to smooth out the transition from one pixel in the starting image to the next pixel, there are a lot of options: we could change either pixel and we could have any number of insertions between them. The insight is that once we have decided where to move both pixels, it is obvious how many insertions we need to do.
The pseudo-code shown below recursively finds the minimal cost to make pixels[] smooth, subject to the constraint that the final pixel in the smoothed version must equal final_value:
int Solve(pixels[], final_value) {
if (pixels is empty) return 0
// Try deleting
best = Solve(pixels[1 to N-1], final_value) + D
// Try all values for the previous pixel value
for (all prev_value) {
prev_cost = Solve(pixels[1 to N-1], prev_value)
move_cost = |final_value - pixels[N]|
num_inserts = (|final_value - prev_value| - 1) / M
insert_cost = num_inserts * I
best = min(best, prev_cost + move_cost + insert_cost)
}
return best
}
To answer the original problem, we just take the minimum value from Solve over all possible choices of final_value.
Unfortunately, this algorithm will be too slow if implemented exactly like this. Within each call to Solve, we are making 257 recursive calls, and we might have to go 100 levels deep. That won't finish in any of our life times, let alone within the time limit! Fortunately, the only reason it is this slow is because we are duplicating work. There are only 256 * N different sets of parameters that we will ever see for the Solve function, so as long as we store the result in a cache, and re-use it when we see the same set of parameters, everything will be much faster. This trick is called Dynamic Programming or more specifically, Memoization.
The Fancy Solution
The run-time of the previous solution is O(256 * 256 * N), which is plenty fast in a competitive language. (Some interpreted languages are orders of magnitude slower at this kind of work than compiled languages - beware!) The extra 256 factor comes from the fact that we need to try 256 possibilities within each function call. It is actually possible to solve this problem in just O(256 * N) time. Here are some hints in case you are interested:
- As before, you want to calculate
Cost[n][p], the cost of making the firstnpixels smooth while setting the final pixel to valuep. Unlike before, you want to do a batch of these updates at the same time. In particular, you want to simultaneously calculate all values forn+1given the values forn. - So how do we do this batch update? First, let's do an intermediate step to calculate
Cost'[n][p], the minimum cost for each value after doing all insertions between pixelnand pixeln+1. To make this more tractable, it helps to notice that there is never any need to insert a pixel with distance less thanMfrom the previous pixel. (Do you see why?) - The real challenge is that when calculating
Cost[n][]fromCost'[n][], you are going to want to take minimums over several elements. For example,Cost[n][q] = min(Cost[n-1][q], {Cost'[n][q-M], Cost'[n][q-M+1], Cost'[n][q-M+2], ..., Cost'[n][q+M]}). In other words, given the arrayCost'[n][], you are going to need to be able to calculate in linear time the minimum element in each range of length2M+1. This is an interesting and challenging problem in its own right, and we encourage you to think it through! For a more thorough discussion of this sub-problem, see here.
Analysis — C. Number Game
Let us begin by focusing on a single game. Given A and B, we can first assume without loss of generality that A ≥ B. Now, how can we decide if it is a winning position or not? (It is impossible to have a tie game since A+B is always decreasing.) Well, a position is winning if and only if, in one step, you can reach a losing position for your opponent. This is an important fact of combinatorial games, so make sure you understand why it's true!
Observations, easy and not so easy
One trivial observation is that (A, A) is a losing position.
Another observation is much trickier unless you have already been exposed to combinatorial games before:
IfTo justify this: in such a position, supposeA ≥ 2B, then(A, B)is a winning position.
k is the largest number of B's we can subtract from A, i.e., A - kB ≥ 0 and A - (k+1)B < 0. We do not know yet whether (A-kB, B) is a winning position or not. But there are just two possibilities. If it is losing, great, we can subtract kB from A, and hand the bad position to our opponent. On the other hand, if it is winning, we can subtract (k-1)B from A, and our opponent has no choice but to subtract another B from the result, giving us the winning position (A-kB, B). Therefore, (A, B) is a winning position either way!
Expand further
The observation above gives us a fairly quick algorithm to figure out who wins a single game (A, B). Instead of using dynamic programming to solve the subproblem for all (A', B') with A' ≤ A and B' ≤ B, which is the most common way of analyzing this kind of game, we can do the following:
- In round 1: If
A ≥ 2B, it's a winning position and we're done. Otherwise, we have only one choice: subtractBfromA, and give our opponent(B, A-B). - In round 2: If
B ≥ 2(A-B), it is a winning position for our opponent. Otherwise, the only choice he has is to subtractA-BfromB, and hand us(A-B, 2B-A). - In round 3: If
A-B ≥ 2(2B-A), it is a winning position for us again. Otherwise, we are going to make it(2B-A, 2A-3B).
(A, B), assuming A ≥ B:
bool winning(int A, int B) {
if (B == 0) return true;
if (A >= 2*B) return true;
return !winning(B, A-B);
}
Does this sound familiar? One connection you might see is that the Number Game closely resembles Euclid's algorithm for greatest common divisor. It is not hard to see that this algorithm, like Euclid's, will need to recurse at most O(log A) times.
Unfortunately, we still cannot afford to run the algorithm for every possible (A, B)! To solve the problem, we need to work with many positions at once. Let us go through the same rounds, but imagine having a fixed B and consider all possible A's at the same time:
- Round 1:
(A, B). IfA ≥ 2B, i.e.,A/B ≥ 2, then(A, B)is winning. - Round 2:
(B, A-B). IfB ≥ 2(A-B), i.e.,A/B ≤ 3/2, then(A, B)is losing. - Round 3:
(A-B, 2B-A). IfA-B ≥ 2(2B-A), i.e.,A/B ≥ 5/3, then(A, B)is wining. - Round 4:
(2B-A, 2A-3B). If2B-A ≥ 2(2A-3B), i.e.,A/B ≤ 8/5, then(A, B)is losing. - And so on.
B, we consider all A's in the above manner, and in O(log 106) rounds, we can classify all the A's.
Simplify
The above method is perfectly correct, but it can be made simpler. First of all, does anything in the above list look familiar? There are Fibonacci numbers all over the place! Let F(i) be the i-th Fibonacci number. One can show by induction that the previous analysis is actually saying the following:
- Round 2t-1: If
A/B ≥ F(2t+1)/F(2t), then(A,B)is a winning position. - Round 2t: If
A/B ≤ F(2t+2)/F(2t+1), then(A,B)is a losing position.
F(2t+1)/F(2t) and F(2t+2)/F(2t+1) approach the golden ratio φ = (1 + √ 5) / 2 as t gets large. This means there is a very simple characterization of all winning positions!
Theorem:Using this theorem, it is easy to solve the problem. Loop through each value for(A, B)is a winning position if and only ifA ≥ φ B.
B, and count how many A values satisfy A ≥ φ B.
Why it is Golden?
Once we have stumbled upon the statement of this theorem, it is actually pretty easy to prove. Here is one method: Using mathematical induction, assume we proved the theorem for all smaller A's and B's. If A ≥ 2B, then (A, B) is a winning position as we discussed earlier. Otherwise we will leave our opponent with (B, A-B). Then (A, B) is winning if and only if (B, A-B) is losing. By our inductive hypothesis, this is equivalent to B ≤ φ (A - B), or A ≥ ((1 + φ) / φ) * B. Since φ = (1 + φ) / φ, this proves (A, B) is winning if and only if A ≥ φ B, as required.
Here is another, more geometric viewpoint. You start with a piece of paper which is an A by B rectangle (A ≥ B), and cut out a B by B square from it. If the rectangle is golden, where A = φB, then the resulting rectangle will also be golden. In our game, A and B are integers, so the rectangle is never golden. We call it thin if A > φB, otherwise we call it fat. From a thin rectangle you can always cut it to a fat rectangle, and from a fat one you can only cut it to a thin one. They correspond to the winning positions and losing positions, respectively.
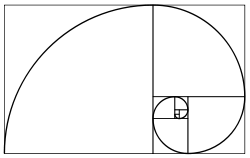
A picture of golden rectangles from Wikipedia.
Other Approaches
There are many ways of arriving at the solution to this problem -- our analysis focuses on only one of these ways. Another approach would be to start with a slower method and compute which (A, B) are winning positions for small A, B. From looking at these results, you could easily guess that (A, B) is winning if and only if A ≥ x B for some x, and all that remains would be to figure out what x is!