Google Code Jam Archive — APAC Semifinal 2008 problems
Overview
This is the first local onsite final of the 2008 Code Jam. We had four problems with different styles, two of them unconventional for different reasons.
Problem C, the Millionaire, is one of the rare gems in the programming contests that, at first glance, is continuous and offers an infinite search space. The beautiful solution makes the problem discrete, and reminds us of some classical puzzles of recursive reasoning. Players from Japan did really well on this problem. 8 Japanese players qualified for the world finals; all of them solved the small dataset of this problem, which is almost as hard as the large dataset.
Problem B, Apocalypse Soon, is another type of big puzzle. The solution is really simple, but you need to see through the properties of the game with very good intuition to believe that the code is really just a trivial simulation. Under such pressure, with the other nice and hard problems, it is not a big surprise that this one had the least number of correct submissions. The top two scorers both solved left this problem to the end.
Problem A, What Are Birds, was meant to be the easy problem here. The best way to solve it is to visualize it as a cute geometry problem. The problem is far from trivial. Several players solved a more difficult problem yet still missed the qualification just because they did not succeed on this one.
Problem D, Modern Art Plagiarism, had the biggest point value. It is a standard graph problem, with a nice solution using matchings. It turns out we have more contestants who solved D than B or C. This implies that many of our players are well trained in classical algorithms.
Again, we had scores of 100 in this match. They are two of the favorites, ACRush and Ahyangyi, both from China. Around 30 minutes before the end of the contest we saw a duel for the top spot. They both had the last program -- for problem C -- almost ready, but soon submitted 6 wrong submissions to C-small. Finally, they fixed their bugs. Ahyangyi was the first to finish all the problems, but had 3 more wrong submissions. ACRush was the winner of the APAC final, with a lower penalty score.
Congratulations to all the participants. It was a wonderful match.
Credits
Problem A. What are Birds? Written by John Dethridge. Prepared by John Dethridge and Marius Andrei.
Problem B. Apocalypse Soon Written by Derek Kisman. Prepared by Igor Naverniouk and Kelly Poon.
Problem C. Millionaire Written by Geir Engdahl. Prepared by Xiaomin Chen.
Problem D. Modern Art Plagiarism Written by John Dethridge. Prepared by Frank Chu and Marius Andrei.
Contest analysis presented by Xiaomin Chen, Derek Kisman, and Geir Engdahl.
A. What are Birds?
Problem
You are studying animals in a forest, and are trying to determine which animals are birds and which are not.
You do this by taking two measurements of each animal – their height and their weight. For an animal to be a bird, its height needs to be within some range, and its weight needs to be within another range, but you're not sure what the height and weight ranges are. You also know that every animal that satisfies these ranges is a bird.
You have taken some of the animals you have measured and shown them to biologists, and they have told you which are birds and which are not. This has given you some information on what the height and weight ranges for a bird must be. For the remaining animals, your program should determine if they are definitely birds, definitely not birds, or if you don't know from the information you have.
Input
One line containing an integer C, the number of test cases in the input.
Then for each of the C test cases:
- One line containing an integer N, the number of animals you have shown to the biologists.
- N lines, one for each of these animals, each of the format "H W X", where H is the height of the animal, W is the weight of the animal, and X is either the string "BIRD" or "NOT BIRD". All numbers are positive integers.
- One line containing an integer M, the number of animals you have not shown to the biologists.
- M lines, one for each of these animals, each of the format "H W", where H is the height of the animal and W is the weight of the animal. All numbers are positive integers.
Output
For each of the C test cases:
- One line containing the string "Case #X:" where X is the number of the test case, starting from 1.
- M lines, each containing one of "BIRD", "NOT BIRD", or "UNKNOWN" (quotes are just for clarity and should not be part of the output).
Limits
Time limit: 30 seconds per test set.
Memory limit: 1GB.
1 ≤ C ≤ 10
1 ≤ all heights and weights ≤ 1000000
Small dataset (Test set 1 - Visible)
1 ≤ N ≤ 10
1 ≤ M ≤ 10
Large dataset (Test set 2 - Hidden)
1 ≤ N ≤ 1000
1 ≤ M ≤ 1000
Sample
3 5 1000 1000 BIRD 2000 1000 BIRD 2000 2000 BIRD 1000 2000 BIRD 1500 2010 NOT BIRD 3 1500 1500 900 900 1400 2020 3 500 700 NOT BIRD 501 700 BIRD 502 700 NOT BIRD 2 501 600 502 501 1 100 100 NOT BIRD 3 107 93 86 70 110 115
Case #1: BIRD UNKNOWN NOT BIRD Case #2: UNKNOWN NOT BIRD Case #3: UNKNOWN UNKNOWN UNKNOWN
Case 1:
The animal "1500 1500" must be within the ranges for birds, since we know that the ranges for height and weight each include 1000 and 2000.
The animal "900 900" may or may not be a bird; we don't know if the ranges for height and weight include 900.
The animal "1400 2020" is within the height range for birds, but if 2020 was in the weight range, then the animal "1500 2010", which we know is not a bird, would also have to be within the weight range.
Case 2:
In this case we know that birds must have a height of 501. But we don't know what the weight range for a bird is, other than that it includes weight 700.
Case 3:
In this case, we know that anything with height 100 and weight 100 is not a bird, but we just don't know what birds are.
B. Apocalypse Soon
Problem
Oh no! The delicate political balance of the world has finally collapsed, and everybody has declared war on everybody else. You warned whoever would listen that this would happen, but did they pay attention? Ha! Now the only thing you can hope for is to survive as long as possible.
Fortunately (sort of), everyone's industrial centers have already been nuked, so the only method of attack available to each nation is to hurl wave after wave of conscripted soldiers at each other. This limits each nation to attacking only its immediate neighbors. The world is a R-by-C grid with R rows, numbered from 1 in the far North to R in the far South, and C columns, numbered from 1 in the far West to C in the far East. Each nation occupies one square of the grid, which means that each nation can reach at most 4 other adjacent nations.
Every nation starts with a specific strength value, known to everyone. They have no concept of advanced strategy, so at the beginning of each day, they will simply choose their strongest neighbor (breaking ties first by Northernmost nation, then by Westernmost) and attack them with an army. The army will have a power equal to the current strength S of the nation; by the end of the day, it will have depleted that neighbor's strength by S. A nation whose strength reaches 0 is destroyed. Note that all nations attack at the same time; an army's power is the same regardless of whether its nation is attacked that day.
Your nation is located at (c, r), in row r and column c. Fortunately, your nation is listening to your advice, so you don't have to follow this crazy strategy. You may choose to attack any of your neighbors on a given day (or do nothing at all). You can't attack multiple neighbors, however, or attack with an army of less than full power.
Determine the maximum number days you can survive.
Input
The first line of input gives the number of cases, T. T test cases follow. The first line of each test case contains four integers, C, R, c, and r. The next R lines each contain C integers, giving the starting strength Sci,ri of the nation in column ci and row ri. It may be 0, indicating that the nation has already been destroyed. Your nation's starting strength will not be 0.
Output
For each test case, output one line containing "Case #A: " followed by:
- "B day(s)", where B is the most days you can hope to survive.
- "forever", if you can outlast all your neighbors.
Limits
Time limit: 30 seconds per test set.
Memory limit: 1GB.
1 ≤ T ≤ 100
1 ≤ c ≤ C
1 ≤ r ≤ R
Small dataset (Test set 1 - Visible)
1 ≤ C ≤ 5
1 ≤ R ≤ 5
0 ≤ Sci,ri ≤ 10
Large dataset (Test set 2 - Hidden)
1 ≤ C ≤ 50
1 ≤ R ≤ 50
0 ≤ Sci,ri ≤ 1000
Sample
2 3 3 2 2 2 3 2 1 7 1 2 1 2 4 3 2 1 1 2 2 0 10 8 5 10 10 2 9 10
Case #1: forever Case #2: 3 day(s)
C. Millionaire
Problem
You have been invited to the popular TV show "Would you like to be a millionaire?". Of course you would!
The rules of the show are simple:
- Before the game starts, the host spins a wheel of fortune to determine P, the probability of winning each bet.
- You start out with some money: X dollars.
-
There are M rounds of betting. In each round, you can bet any part of
your current money, including none of it or all of it. The amount is not
limited to whole dollars or whole cents.
If you win the bet, your total amount of money increases by the amount you bet. Otherwise, your amount of money decreases by the amount you bet. - After all the rounds of betting are done, you get to keep your winnings (this time the amount is rounded down to whole dollars) only if you have accumulated $1000000 or more. Otherwise you get nothing.
Given M, P and X, determine your probability of winning at least $1000000 if you play optimally (i.e. you play so that you maximize your chances of becoming a millionaire).
Input
The first line of input gives the number of cases, N.
Each of the following N lines has the format "M P X", where:
- M is an integer, the number of rounds of betting.
- P is a real number, the probability of winning each round.
- X is an integer, the starting number of dollars.
Output
For each test case, output one line containing "Case #X: Y", where:
- X is the test case number, beginning at 1.
- Y is the probability of becoming a millionaire, between 0 and 1.
Answers with a relative or absolute error of at most 10-6 will be considered correct.
Limits
Time limit: 30 seconds per test set.
Memory limit: 1GB.
1 ≤ N ≤ 100
0 ≤ P ≤ 1.0, there will be at most 6 digits after the decimal
point.
1 ≤ X ≤ 1000000
Small dataset (Test set 1 - Visible)
1 ≤ M ≤ 5
Large dataset (Test set 2 - Hidden)
1 ≤ M ≤ 15
Sample
2 1 0.5 500000 3 0.75 600000
Case #1: 0.500000 Case #2: 0.843750
In the first case, the only way to reach $1000000 is to bet everything in the single round.
In the second case, you can play so that you can still reach $1000000 even if you lose a bet. Here's one way to do it:
- You have $600000 on the first round. Bet $150000.
- If you lose the first round, you have $450000 left. Bet $100000.
- If you lose the first round and win the second round, you have $550000 left. Bet $450000.
- If you win the first round, you have $750000 left. Bet $250000.
- If you win the first round and lose the second round, you have $500000 left. Bet $500000.
D. Modern Art Plagiarism
Problem
You have pictures of two sculptures. The sculptures consist of several solid metal spheres, and some rubber pipes connecting pairs of spheres. The pipes in each sculpture are connected in such a way that for any pair of spheres, there is exactly one path following a series of pipes (without repeating any) between those two spheres. All the spheres have the same radius, and all the pipes have the same length.
You suspect that the smaller of the two sculptures was actually created by simply removing some spheres and pipes from the larger one. You want to write a program to test if this is possible.
The input will contain several test cases. One sculpture is described by numbering the spheres consecutively from 1, and listing the pairs of spheres which are connected by pipes. The numbering is chosen independently for each sculpture.
Input
- One line containing an integer C, the number of test cases in the input file.
- One line containing the integer N, the number of spheres in the large sculpture.
- N−1 lines, each containing a pair of space-separated integers, indicating that the two spheres with those numbers in the large sculpture are connected by a pipe.
- One line containing the integer M, the number of spheres in the small sculpture.
- M−1 lines, each containing a pair of space-separated integers, indicating that the two spheres with those numbers in the small sculpture are connected by a pipe.
Output
- C lines, one for each test case in the order they occur in the input file, containing "Case #X: YES" if the small sculpture in case X could have been created from the large sculpture in case X, or "Case #X: NO" if it could not. (X is the number of the test case, between 1 and C.)
Limits
Time limit: 30 seconds per test set.
Memory limit: 1GB.
Small dataset (Test set 1 - Visible)
1 ≤ C ≤ 100
2 ≤ N ≤ 8
1 ≤ M < N
Large dataset (Test set 2 - Hidden)
1 ≤ C ≤ 50
2 ≤ N ≤ 100
1 ≤ M < N
Sample
2 5 1 2 2 3 3 4 4 5 4 1 2 1 3 1 4 5 1 2 1 3 1 4 4 5 4 1 2 2 3 3 4
Case #1: NO Case #2: YES
In the first case, the large sculpture has five spheres connected in a line, and the small sculpture has one sphere that has three other spheres connected to it. There's no way the smaller sculpture could have been made by removing things from the larger one.
In the second case, the small sculpture is four spheres connected in a line. These can match the larger sculpture's spheres in the order 2-1-4-5.
Analysis — A. What are Birds?
The Simple Solution
Let us visualize this problem. Each animal is characterized as a pair (H, W), which can be viewed as a point in the two dimensional Cartesian coordinate system. For each animal that is known to be a bird, we color it red. For each animal known to be a non-bird, we color it blue. The problem states that there exists a rectangle such that a point is red if and only if it is in the rectangle. The problem is trivial if there are no red points. From now on we assume there are red points.
For any two distinct points U and V, there is naturally a rectangle determined by U and V. It is the smallest rectangle containing both U and V, with the four corners U, V, (HU, WV), and (HV, WU). When U and V are on the same horizontal or vertical line, the rectangle degenerates to a segment. Formally, the rectangle contains all the points (H, W) such that
(|H - HU| + |W - WU|) + (|H - HV| + |W - WV|) = |HU - HV| + |WU - WV|.
We have the following proposition.
If U and V are two red points, and R be the rectangle determined by U and V; then any point in R must also be red, since any rectangle containing both U and V must contain R.
For the set of all red points in the input, there is also naturally a smallest rectangle, R0, that contains all of them. There are different ways to define this rectangle:
- (a) The intersection of all the rectangles that contain all the red points.
- (b) The union of all the rectangles determined by U and V, where (U, V) range over all the red point pairs.
- (c) The rectangle with four corners A=(Hmin, Wmin), B=(Hmin, Wmax), C=(Hmax, Wmin), and D=(Hmax, Wmax), where the min and max are taken over all the red points.
Now, given a point X, we want to know if it is a bird or not. Clearly, if X is inside R0, then it must be bird. Otherwise, we may pretend it is red, and compute the new rectangle R' based on (c). This can be done in a constant number of comparisons. If there is a blue point from the input that lies in R', then X must not be a bird. Otherwise, X might (taking R' as the red rectangle) or might not (taking R0 as the red rectangle) be a bird.
By the limits of this problem, a Θ(NM) algorithm is fast enough. That is, we simply take any blue input point, and check if that is inside R'.
Further Discussion
Another way to view the last step of the solution, when the query point X is given, is to see whether there is a known red point Y such that the rectangle determined by X and Y contains any blue point. It is enough to check Y = A, B, C, or D as in (c). To check this, we do not need to go over all the blue input points. There are standard pre-processing techniques that can reduce the query time from N to log N.
For example, for A, we can define two sets based on the blue inputs: those points that are higher (along the W-axis) than A (call them A1) and the rest of the A points (
Analysis — B. Apocalypse Soon
This problem is a sheep in wolf's clothing. However, it must have been very convincing wolf's clothing! Fewer competitors solved it than any other problem, despite the simplicity of the actual solution. Since this was an onsite round, they were all experienced competitors; in some sense, that worked against them.
Why does the problem seem so hard? To a practiced eye, it has all the trappings of a horrible exponential search. You have 5 actions to choose from on each day, and the results of those actions don't tend to overlap, leading to an exponential number of possible states. Furthermore, even the subtlest change in a nation's strength can drastically affect the final outcome, so at each step the entire state of the world matters. This makes a Dynamic Programming-based solution look unlikely. And due to the chaotic nature of the rules, there's unlikely to be a greedy strategy that works in all cases.
So a horrible exponential search seems essential. On a 50x50 grid of numbers between 0 and 1000, this is clearly intractable! Give up and go home. No, wait... it's supposed to be solvable somehow, right? How could that be?
Well, if you try a few cases by hand, you'll soon realize why: everyone ends up killing their neighbors really, really quickly. A random map tends to stabilize (no living neighbors) in only 4-6 days. It's actually very difficult to come up with a case that takes longer. The more you try, the more you'll realize just how difficult it is; the army sizes required grow exponentially, and the tighter you pack them the sooner they all die. The map size doesn't turn out to matter much - it's the army size bound of 1000 that really sets the cap on how long you'll need to search.
What exactly is this cap? That's a really tough question. For instance, if
army sizes are unbounded, there is no small limit. Here's a simple
(2n-2)x2 case that takes n days to stabilize:
1 2 4 8 ... 22n-3
1 2 4 8 ... 22n-3
However, the army sizes must grow exponentially relative to the number of days. Here's a simple proof: on day n, let Sn be the strength of the strongest nation that still has living neighbors. Let N be any nation with strength ≥ Sn/2. Suppose that after 8 days N still has strength ≥ Sn/2. Then it must have killed all its neighbors, since none had strength ≥ Sn (that is, any neighbor would die after at most 2 attacks). So every such N either ends up isolated or weaker than Sn/2 after 8 days. Thus, Sn+8 ≤ Sn/2. This puts a strict bound of 8(log2Sn+1) more days before all nations are dead or isolated.
Unfortunately, for army sizes of 1000 this bound of 80 days still isn't very helpful. The bound can be improved with tighter reasoning, but due to the compact, constrained nature of the grid, the "true" bound is probably much smaller - around 9-10 days! However, we don't know how to prove a bound anywhere near this. If you can think of a way, let us know! :)
The worst test case in our data had an answer of "9 day(s)". So as it turns out, even a straight brute force solution (on the worst-case order of 50x50x59) would suffice to solve it. Adding simple pruning heuristics and memoization can potentially also help, but isn't necessary.
Incidentally, one potential coding error you could make is to assume that effects can only propagate at one grid square per day. The "speed of light" (as it's known in cellular automata) is actually two grid squares per day, because if an army's neighbor changes, it may choose to attack its opposite neighbor instead. In the "9 day(s)" test case, there are nations 13 squares away from yours that end up affecting the answer. So if you tried to speed up your solution by considering only the local region around your nation, you'd have to be careful not to make it too local.
In the end, all it took to get this problem was bravery (or foolishness). If you code it properly and try it, it works! It's just a question of how well you can convince yourself that the simple solution has a hope of working. You certainly wouldn't want to download the Large dataset and then realize your solution was too slow...
Analysis — C. Millionaire
The problem explicitly states that the contestant has an infinite number of degrees of freedom. She can bet ANY fraction of her current amount. This makes it impossible to brute force over all of the possible bets. The trick is to discretize the problem.
Following one of the principles in problem solving, we look at the easier cases. The problem is easy if there is one round. We suggest you do it for the case when there are two rounds. It is not hard, but it reveals the interesting nature of the problem. The figure below illustrates the situation in the second-to-last round, the last round and after the last round.
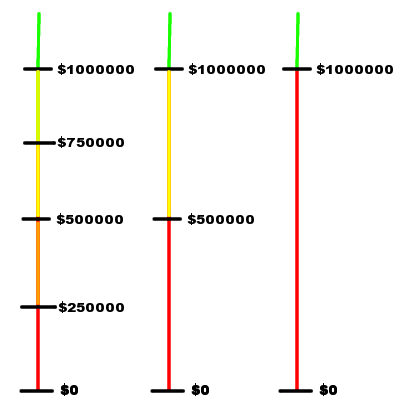
The colors represent different probability zones. All sums in a probability zone share the same probability of winning. The important sums are marked and labeled.
If we know the probability of winning for all sums in the next round Pnext(sum), then the probability of winning in this round is:
p * Pnext(sum + stake) + (1 - p) Pnext(sum - stake),
where stake is the amount we are betting.
Now, given the existence and location of the important sums in the next round, we can find the locations of the important sums in this round. The figure below illustrates how we find these sums. The midpoints between the important sums of the next round become important in this round. I.e in the case of the green point in figure 2, we can move up by lowering the stake, and we can move down by increasing the stake, without changing the end probability. The probability of the blue, green and red points is the same. This also illustrates that the probability in a 'probability zone' which is limited by two important sums is equal to the probability at the lower important sum.
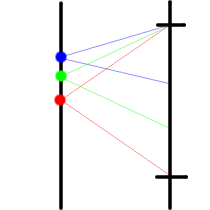
Conclusion: The important sums of round i are the union of the important sums
of round
Now, we only need to compute probabilities at the important sums, bootstrapping at 1.0 for $1000000, and 0.0 for $0 in the last round. Then, going backwards, we fill the probabilities at the important sums in the previous rounds.
By the limits of the input, we may try all the stakes that lead to important points in the next round. It is an interesting question whether there are mathematical properties that could reduce the complexity of this computation, but that is beyond the scope of this analysis.
Analysis — D. Modern Art Plagiarism
This problem is a classical graph problem called subtree isomorphism. As an interesting note, the modern era in art history actually starts far earlier than the so called classical period in computer science.
In this problem, we are given two trees T1 and T2. We are going to decide if T2 is isomorphic to any subtree of T1. The general sub-graph isomorphism problem is notoriously hard. But as you perhaps have seen many times, when the things come to trees, it is very solvable. The problem is actually well studied, and is a standard exercise in algorithm design.
First, a bit of terminology. Just for convenience, in our discussion, for two rooted trees, we say one fits into the other if there us an isomorphism that maps the former to a subtree of the latter such that the root is mapped to the other's root.
We may fix T2 and consider it as a tree rooted at vertex 0. We do
not know which vertex of T1 corresponds to 0 of T2 in
the isomorphism. But we may try each vertex in T1, and see if
T2 fits into T1.
For a concrete example, let's say we root T1 at vertex x.
Assume that there are 3 children of 0 in T2 -- y1,
y2, and y3. Assume that there are 5 children of x in
T1 -- x1. x2, x3. T2
fits into T1 if and only if we can find that the subtree at
y1 fits into the subtree at xi for some i, the subtree
at y2 fits into the subtree at xj for some other j ≠
i, and the subtree at y3 fits into the subtree at xk
for some k ≠ i, k ≠ j.
The solution for this problem as follows. Once we have fixed the root x, each
vertex has a level in its tree. For each vertex u in T1 and
v in T2, if they have the same level (just a bit of
reasonable optimization, not necessary for this problem), we want to decide if
the subtree at v fits into the subtree at u. We do this from bottom up, the
deeper levels first.
For any such pair (u, v) with children { ui | i = 1,2,... } and {
vj | j = 1,2,... }, we know which vj fits into which
ui since we are doing the computations bottom up. We find a fit if
and only if we can find, for each vj, a distinct ui such
that vj fits into ui. This is clearly a bipartite graph
matching problem.
We leave it an exercise to prove that the algorithm, runs in
O(N2M2) time. There are algorithms with better
complexities. For interested readers, we refer to the following paper
R. Shamir, D. Tsur, "Faster Subtree Isomorphism", Journal of Algorithm,
33, 267-280 (1999).
which contains a recent result as well as references to earlier works.
More information
Subtree Isomorphism - Graph Isomorphism - Bipartite Matching